 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll SMILES Variational Autoencoder
Jun 03, 2019



Variational autoencoders (VAEs) defined over SMILES string and graph-based representations of molecules promise to improve the optimization of molecular properties, thereby revolutionizing the pharmaceuticals and materials industries. However, these VAEs are hindered by the non-unique nature of SMILES strings and the computational cost of graph convolutions. To efficiently pass messages along all paths through the molecular graph, we encode multiple SMILES strings of a single molecule using a set of stacked recurrent neural networks, pooling hidden representations of each atom between SMILES representations, and use attentional pooling to build a final fixed-length latent representation. By then decoding to a disjoint set of SMILES strings of the molecule, our All SMILES VAE learns an almost bijective mapping between molecules and latent representations near the high-probability-mass subspace of the prior. Our SMILES-derived but molecule-based latent representations significantly surpass the state-of-the-art in a variety of fully- and semi-supervised property regression and molecular property optimization tasks.
Discrete Variational Autoencoders
Apr 22, 2017
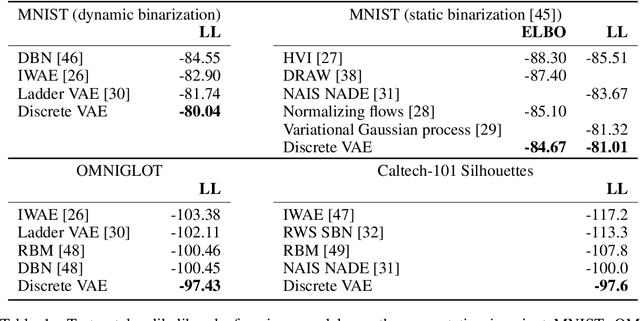


Probabilistic models with discrete latent variables naturally capture datasets composed of discrete classes. However, they are difficult to train efficiently, since backpropagation through discrete variables is generally not possible. We present a novel method to train a class of probabilistic models with discrete latent variables using the variational autoencoder framework, including backpropagation through the discrete latent variables. The associated class of probabilistic models comprises an undirected discrete component and a directed hierarchical continuous component. The discrete component captures the distribution over the disconnected smooth manifolds induced by the continuous component. As a result, this class of models efficiently learns both the class of objects in an image, and their specific realization in pixels, from unsupervised data, and outperforms state-of-the-art methods on the permutation-invariant MNIST, Omniglot, and Caltech-101 Silhouettes datasets.
Discriminative Recurrent Sparse Auto-Encoders
Mar 19, 2013



We present the discriminative recurrent sparse auto-encoder model, comprising a recurrent encoder of rectified linear units, unrolled for a fixed number of iterations, and connected to two linear decoders that reconstruct the input and predict its supervised classification. Training via backpropagation-through-time initially minimizes an unsupervised sparse reconstruction error; the loss function is then augmented with a discriminative term on the supervised classification. The depth implicit in the temporally-unrolled form allows the system to exhibit all the power of deep networks, while substantially reducing the number of trainable parameters. From an initially unstructured network the hidden units differentiate into categorical-units, each of which represents an input prototype with a well-defined class; and part-units representing deformations of these prototypes. The learned organization of the recurrent encoder is hierarchical: part-units are driven directly by the input, whereas the activity of categorical-units builds up over time through interactions with the part-units. Even using a small number of hidden units per layer, discriminative recurrent sparse auto-encoders achieve excellent performance on MNIST.