 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Side-by-side Comparison of Transformers for English Implicit Discourse Relation Classification
Jul 07, 2023
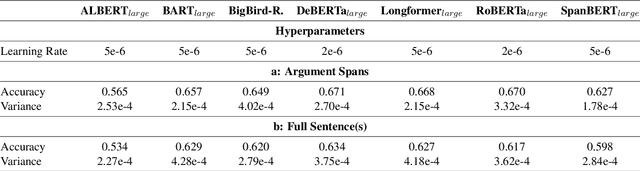


Though discourse parsing can help multiple NLP fields, there has been no wide language model search done on implicit discourse relation classification. This hinders researchers from fully utilizing public-available models in discourse analysis. This work is a straightforward, fine-tuned discourse performance comparison of seven pre-trained language models. We use PDTB-3, a popular discourse relation annotated dataset. Through our model search, we raise SOTA to 0.671 ACC and obtain novel observations. Some are contrary to what has been reported before (Shi and Demberg, 2019b), that sentence-level pre-training objectives (NSP, SBO, SOP) generally fail to produce the best performing model for implicit discourse relation classification. Counterintuitively, similar-sized PLMs with MLM and full attention led to better performance.
LFTK: Handcrafted Features in Computational Linguistics
May 25, 2023



Past research has identified a rich set of handcrafted linguistic features that can potentially assist various tasks. However, their extensive number makes it difficult to effectively select and utilize existing handcrafted features. Coupled with the problem of inconsistent implementation across research works, there has been no categorization scheme or generally-accepted feature names. This creates unwanted confusion. Also, most existing handcrafted feature extraction libraries are not open-source or not actively maintained. As a result, a researcher often has to build such an extraction system from the ground up. We collect and categorize more than 220 popular handcrafted features grounded on past literature. Then, we conduct a correlation analysis study on several task-specific datasets and report the potential use cases of each feature. Lastly, we devise a multilingual handcrafted linguistic feature extraction system in a systematically expandable manner. We open-source our system for public access to a rich set of pre-implemented handcrafted features. Our system is coined LFTK and is the largest of its kind. Find it at github.com/brucewlee/lftk.
Prompt-based Learning for Text Readability Assessment
Feb 25, 2023We propose the novel adaptation of a pre-trained seq2seq model for readability assessment. We prove that a seq2seq model - T5 or BART - can be adapted to discern which text is more difficult from two given texts (pairwise). As an exploratory study to prompt-learn a neural network for text readability in a text-to-text manner, we report useful tips for future work in seq2seq training and ranking-based approach to readability assessment. Specifically, we test nine input-output formats/prefixes and show that they can significantly influence the final model performance. Also, we argue that the combination of text-to-text training and pairwise ranking setup 1) enables leveraging multiple parallel text simplification data for teaching readability and 2) trains a neural model for the general concept of readability (therefore, better cross-domain generalization). At last, we report a 99.6% pairwise classification accuracy on Newsela and a 98.7% for OneStopEnglish, through a joint training approach.
Traditional Readability Formulas Compared for English
Jan 10, 2023Traditional English readability formulas, or equations, were largely developed in the 20th century. Nonetheless, many researchers still rely on them for various NLP applications. This phenomenon is presumably due to the convenience and straightforwardness of readability formulas. In this work, we contribute to the NLP community by 1. introducing New English Readability Formula (NERF), 2. recalibrating the coefficients of old readability formulas (Flesch-Kincaid Grade Level, Fog Index, SMOG Index, Coleman-Liau Index, and Automated Readability Index), 3. evaluating the readability formulas, for use in text simplification studies and medical texts, and 4. developing a Python-based program for the wide application to various NLP projects.
Pushing on Text Readability Assessment: A Transformer Meets Handcrafted Linguistic Features
Sep 25, 2021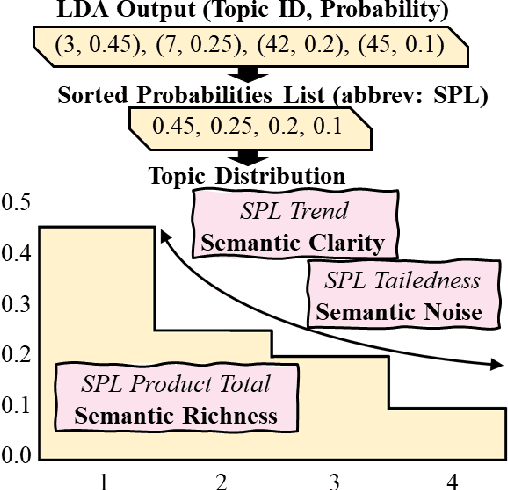


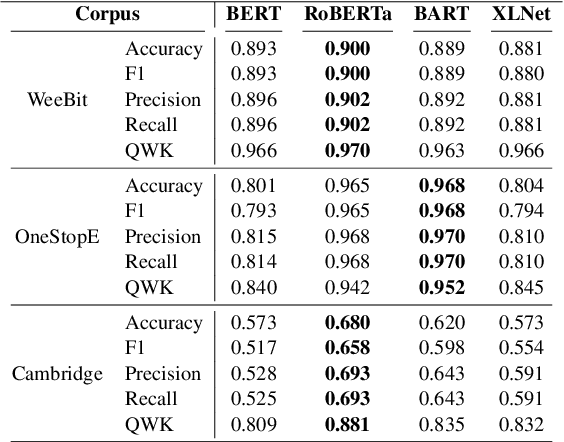
We report two essential improvements in readability assessment: 1. three novel features in advanced semantics and 2. the timely evidence that traditional ML models (e.g. Random Forest, using handcrafted features) can combine with transformers (e.g. RoBERTa) to augment model performance. First, we explore suitable transformers and traditional ML models. Then, we extract 255 handcrafted linguistic features using self-developed extraction software. Finally, we assemble those to create several hybrid models, achieving state-of-the-art (SOTA) accuracy on popular datasets in readability assessment. The use of handcrafted features help model performance on smaller datasets. Notably, our RoBERTA-RF-T1 hybrid achieves the near-perfect classification accuracy of 99%, a 20.3% increase from the previous SOTA.
LXPER Index 2.0: Improving Text Readability Assessment for L2 English Learners in South Korea
Nov 05, 2020



Developing a text readability assessment model specifically for texts in a foreign English Language Training (ELT) curriculum has never had much attention in the field of Natural Language Processing. Hence, most developed models show extremely low accuracy for L2 English texts, up to the point where not many even serve as a fair comparison. In this paper, we investigate a text readability assessment model for L2 English learners in Korea. In accordance, we improve and expand the Text Corpus of the Korean ELT curriculum (CoKEC-text). Each text is labeled with its target grade level. We train our model with CoKEC-text and significantly improve the accuracy of readability assessment for texts in the Korean ELT curriculum.
LXPER Index: a curriculum-specific text readability assessment model for EFL students in Korea
Aug 01, 2020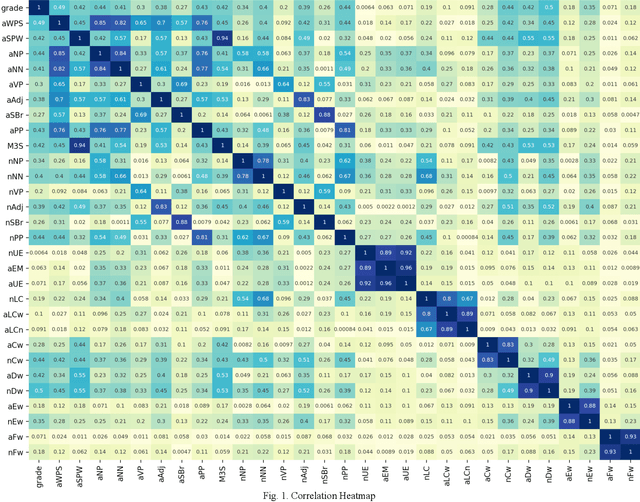
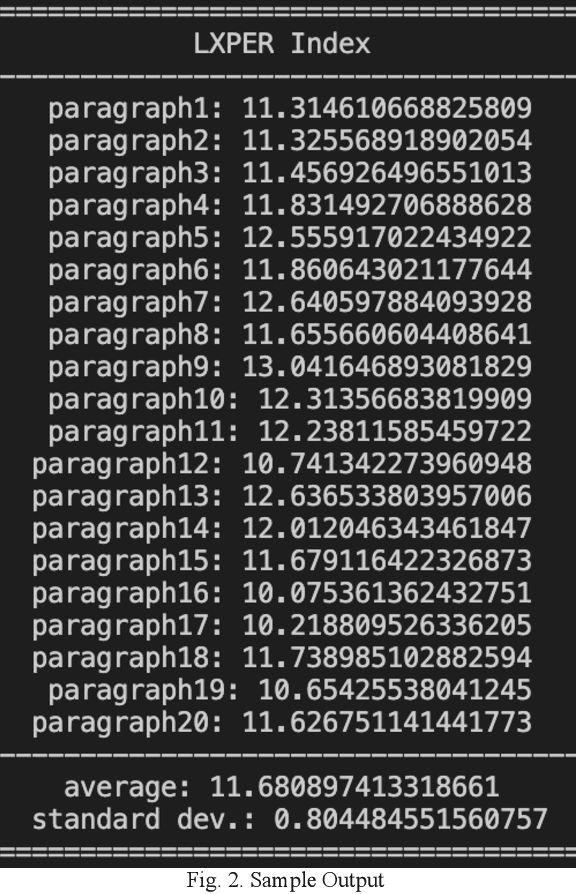


Automatic readability assessment is one of the most important applications of Natural Language Processing (NLP) in education. Since automatic readability assessment allows the fast selection of appropriate reading material for readers at all levels of proficiency, it can be particularly useful for the English education of English as Foreign Language (EFL) students around the world. Most readability assessment models are developed for the native readers of English and have low accuracy for texts in the non-native English Language Training (ELT) curriculum. We introduce LXPER Index, which is a readability assessment model for non-native EFL readers in the ELT curriculum of Korea. Our experiments show that our new model, trained with CoKEC-text (Text Corpus of the Korean ELT Curriculum), significantly improves the accuracy of automatic readability assessment for texts in the Korean ELT curriculum.