 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLXPER Index: a curriculum-specific text readability assessment model for EFL students in Korea
Paper and Code
Aug 01, 2020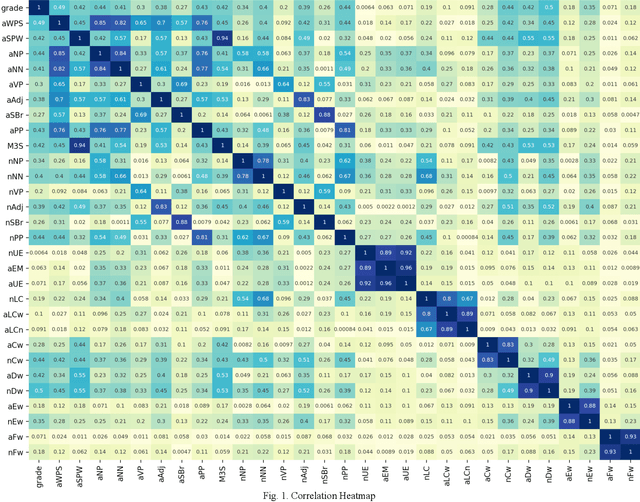
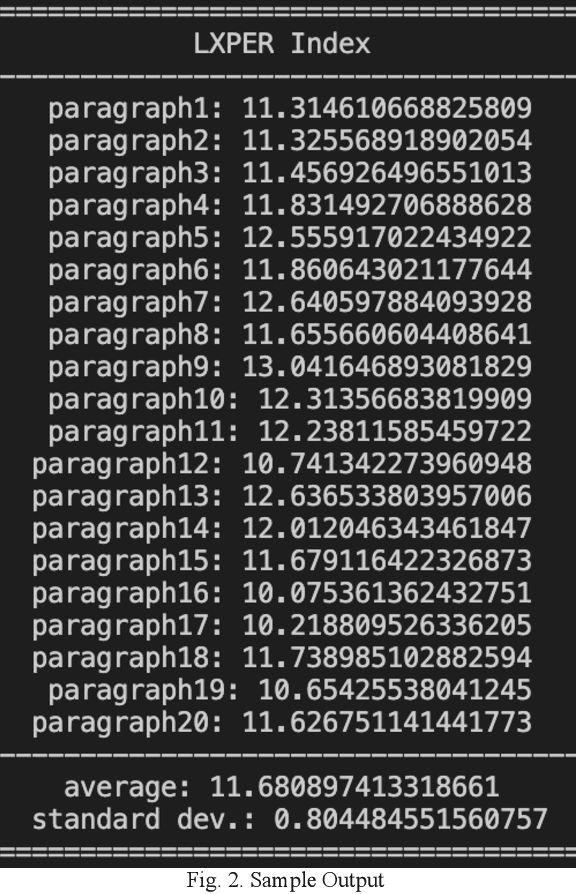


Automatic readability assessment is one of the most important applications of Natural Language Processing (NLP) in education. Since automatic readability assessment allows the fast selection of appropriate reading material for readers at all levels of proficiency, it can be particularly useful for the English education of English as Foreign Language (EFL) students around the world. Most readability assessment models are developed for the native readers of English and have low accuracy for texts in the non-native English Language Training (ELT) curriculum. We introduce LXPER Index, which is a readability assessment model for non-native EFL readers in the ELT curriculum of Korea. Our experiments show that our new model, trained with CoKEC-text (Text Corpus of the Korean ELT Curriculum), significantly improves the accuracy of automatic readability assessment for texts in the Korean ELT curriculum.