 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Kernel Matching for Non-conforming Data: A Case Study of T-cell Receptor Datasets
Mar 18, 2021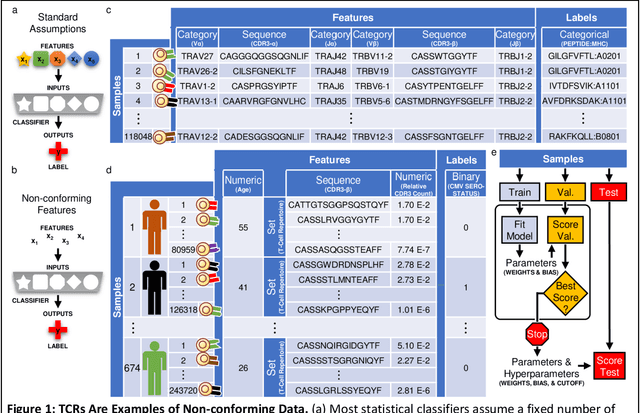
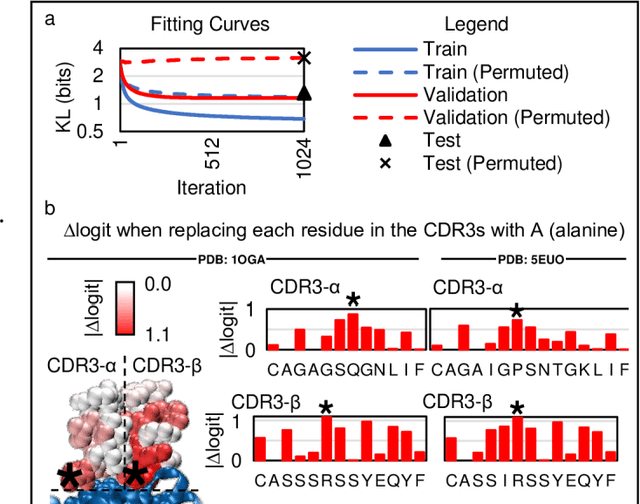
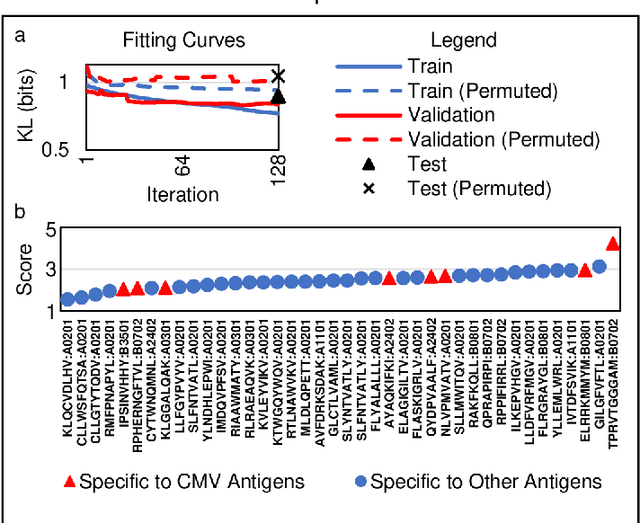
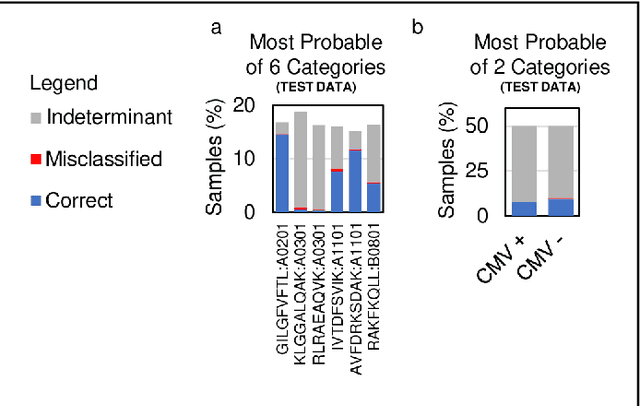
Most statistical classifiers are designed to find patterns in data where numbers fit into rows and columns, like in a spreadsheet, but many kinds of data do not conform to this structure. To uncover patterns in non-conforming data, we describe an approach for modifying established statistical classifiers to handle non-conforming data, which we call dynamic kernel matching (DKM). As examples of non-conforming data, we consider (i) a dataset of T-cell receptor (TCR) sequences labelled by disease antigen and (ii) a dataset of sequenced TCR repertoires labelled by patient cytomegalovirus (CMV) serostatus, anticipating that both datasets contain signatures for diagnosing disease. We successfully fit statistical classifiers augmented with DKM to both datasets and report the performance on holdout data using standard metrics and metrics allowing for indeterminant diagnoses. Finally, we identify the patterns used by our statistical classifiers to generate predictions and show that these patterns agree with observations from experimental studies.
Machine Learning on Sequential Data Using a Recurrent Weighted Average
May 04, 2017



Recurrent Neural Networks (RNN) are a type of statistical model designed to handle sequential data. The model reads a sequence one symbol at a time. Each symbol is processed based on information collected from the previous symbols. With existing RNN architectures, each symbol is processed using only information from the previous processing step. To overcome this limitation, we propose a new kind of RNN model that computes a recurrent weighted average (RWA) over every past processing step. Because the RWA can be computed as a running average, the computational overhead scales like that of any other RNN architecture. The approach essentially reformulates the attention mechanism into a stand-alone model. The performance of the RWA model is assessed on the variable copy problem, the adding problem, classification of artificial grammar, classification of sequences by length, and classification of the MNIST images (where the pixels are read sequentially one at a time). On almost every task, the RWA model is found to outperform a standard LSTM model.