 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Kernel Matching for Non-conforming Data: A Case Study of T-cell Receptor Datasets
Paper and Code
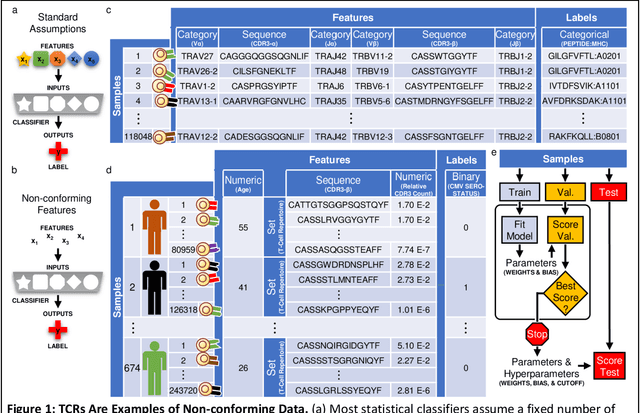
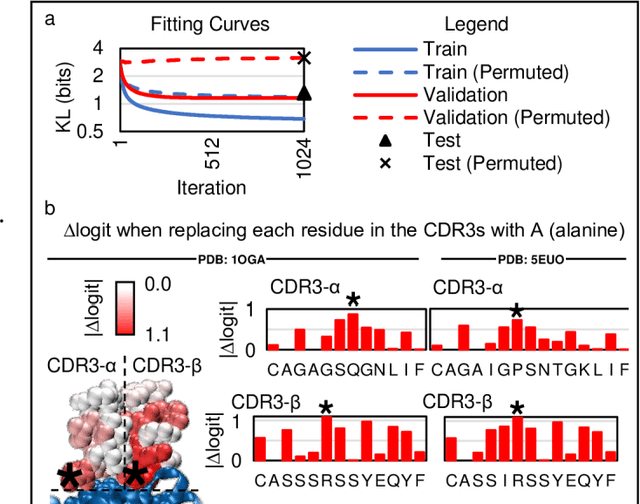
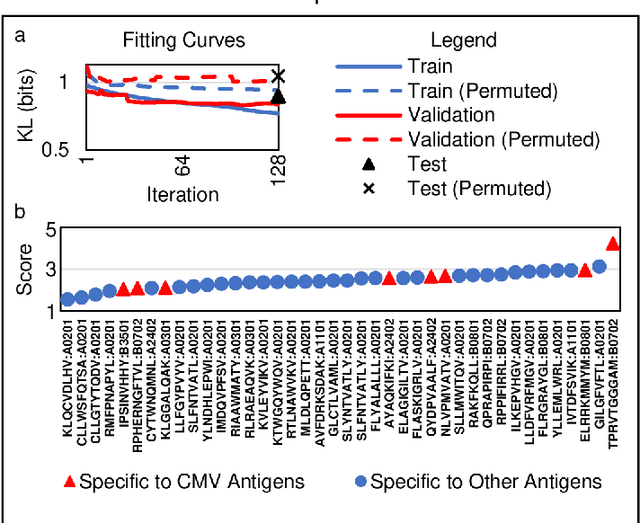
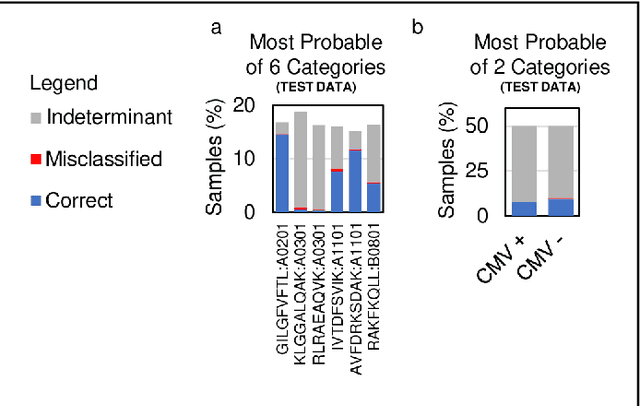
Most statistical classifiers are designed to find patterns in data where numbers fit into rows and columns, like in a spreadsheet, but many kinds of data do not conform to this structure. To uncover patterns in non-conforming data, we describe an approach for modifying established statistical classifiers to handle non-conforming data, which we call dynamic kernel matching (DKM). As examples of non-conforming data, we consider (i) a dataset of T-cell receptor (TCR) sequences labelled by disease antigen and (ii) a dataset of sequenced TCR repertoires labelled by patient cytomegalovirus (CMV) serostatus, anticipating that both datasets contain signatures for diagnosing disease. We successfully fit statistical classifiers augmented with DKM to both datasets and report the performance on holdout data using standard metrics and metrics allowing for indeterminant diagnoses. Finally, we identify the patterns used by our statistical classifiers to generate predictions and show that these patterns agree with observations from experimental studies.