 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality-Aware Neighborhood Methods for Recommender Systems
Dec 17, 2020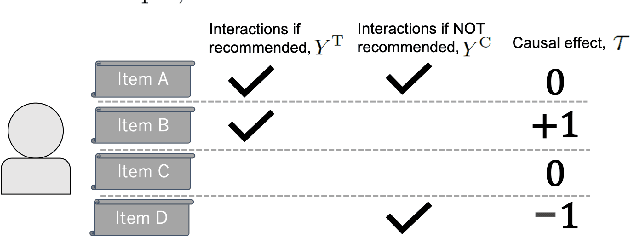
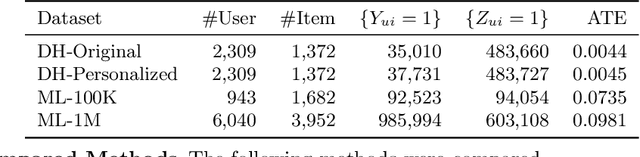

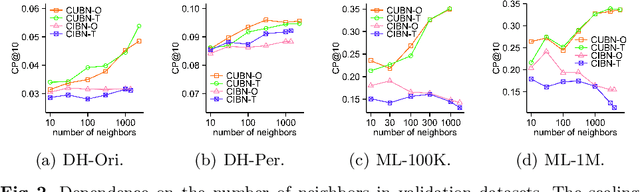
The business objectives of recommenders, such as increasing sales, are aligned with the causal effect of recommendations. Previous recommenders targeting for the causal effect employ the inverse propensity scoring (IPS) in causal inference. However, IPS is prone to suffer from high variance. The matching estimator is another representative method in causal inference field. It does not use propensity and hence free from the above variance problem. In this work, we unify traditional neighborhood recommendation methods with the matching estimator, and develop robust ranking methods for the causal effect of recommendations. Our experiments demonstrate that the proposed methods outperform various baselines in ranking metrics for the causal effect. The results suggest that the proposed methods can achieve more sales and user engagement than previous recommenders.
Unbiased Learning for the Causal Effect of Recommendation
Aug 20, 2020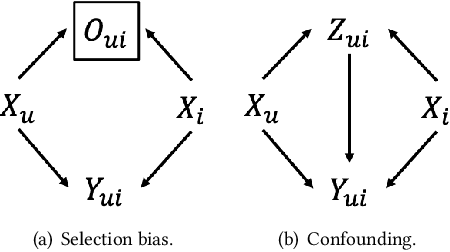
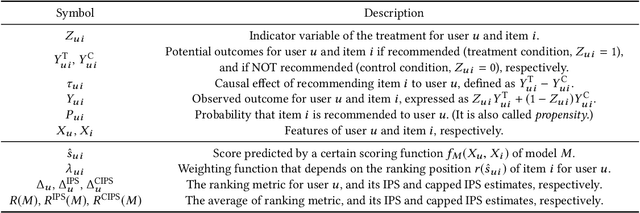
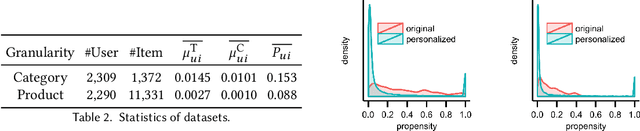
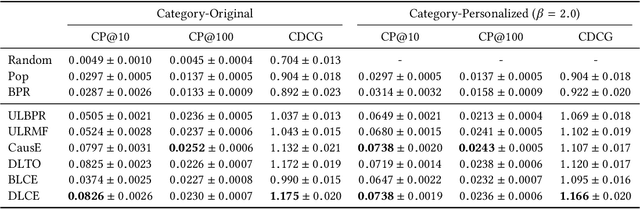
Increasing users' positive interactions, such as purchases or clicks, is an important objective of recommender systems. Recommenders typically aim to select items that users will interact with. If the recommended items are purchased, an increase in sales is expected. However, the items could have been purchased even without recommendation. Thus, we want to recommend items that results in purchases caused by recommendation. This can be formulated as a ranking problem in terms of the causal effect. Despite its importance, this problem has not been well explored in the related research. It is challenging because the ground truth of causal effect is unobservable, and estimating the causal effect is prone to the bias arising from currently deployed recommenders. This paper proposes an unbiased learning framework for the causal effect of recommendation. Based on the inverse propensity scoring technique, the proposed framework first constructs unbiased estimators for ranking metrics. Then, it conducts empirical risk minimization on the estimators with propensity capping, which reduces variance under finite training samples. Based on the framework, we develop an unbiased learning method for the causal effect extension of a ranking metric. We theoretically analyze the unbiasedness of the proposed method and empirically demonstrate that the proposed method outperforms other biased learning methods in various settings.
Submodular Bandit Problem Under Multiple Constraints
Jun 03, 2020


The linear submodular bandit problem was proposed to simultaneously address diversified retrieval and online learning in a recommender system. If there is no uncertainty, this problem is equivalent to a submodular maximization problem under a cardinality constraint. However, in some situations, recommendation lists should satisfy additional constraints such as budget constraints, other than a cardinality constraint. Thus, motivated by diversified retrieval considering budget constraints, we introduce a submodular bandit problem under the intersection of $l$ knapsacks and a $k$-system constraint. Here $k$-system constraints form a very general class of constraints including cardinality constraints and the intersection of $k$ matroid constraints. To solve this problem, we propose a non-greedy algorithm that adaptively focuses on a standard or modified upper-confidence bound. We provide a high-probability upper bound of an approximation regret, where the approximation ratio matches that of a fast offline algorithm. Moreover, we perform experiments under various combinations of constraints using a synthetic and two real-world datasets and demonstrate that our proposed methods outperform the existing baselines.