 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-triggered Natural Hazard Monitoring with Convolutional Neural Networks on the Edge
Oct 22, 2018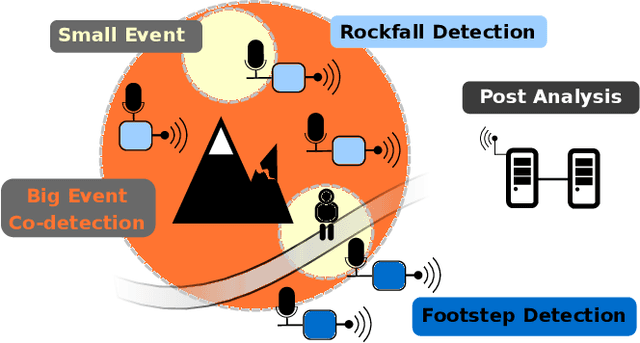
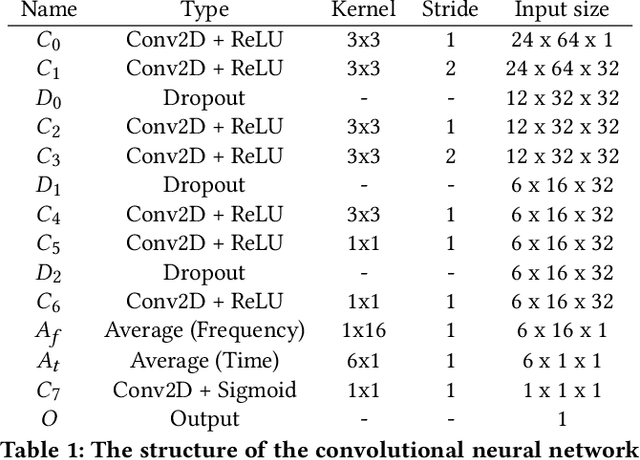
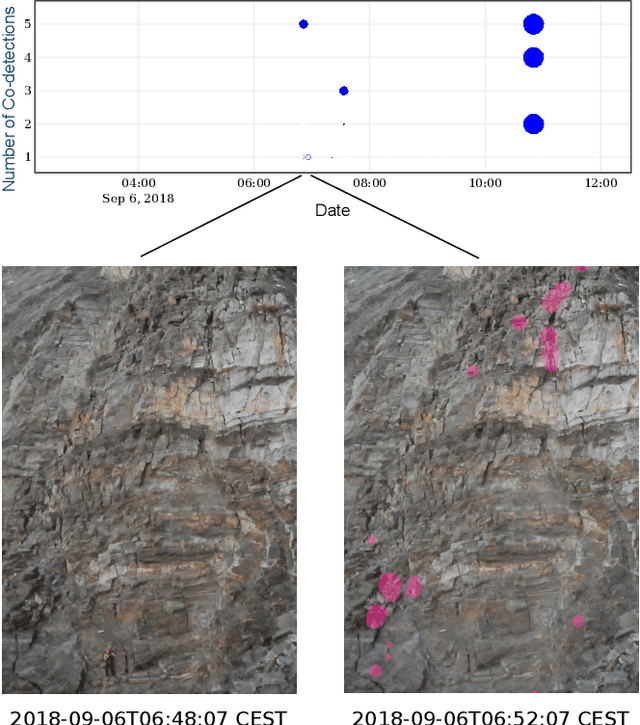

In natural hazard warning systems fast decision making is vital to avoid catastrophes. Decision making at the edge of a wireless sensor network promises fast response times but is limited by the availability of energy, data transfer speed, processing and memory constraints. In this work we present a realization of a wireless sensor network for hazard monitoring which is based on an array of event-triggered seismic sensors with advanced signal processing and characterization capabilities for a novel co-detection technique. On the one hand we leverage an ultra-low power, threshold-triggering circuit paired with on-demand digital signal acquisition capable of extracting relevant information exactly when it matters most and not wasting precious resources when nothing can be observed. On the other hand we use machine-learning-based classification implemented on low-power, off-the-shelf microcontrollers to avoid false positive warnings and to actively identify humans in hazard zones. The sensors' response time and memory requirement is substantially improved by pipelining the inference of a convolutional neural network. In this way, convolutional neural networks that would not run unmodified on a memory constrained device can be executed in real-time and at scale on low-power embedded devices.
Unsupervised Feature Learning for Audio Analysis
Dec 11, 2017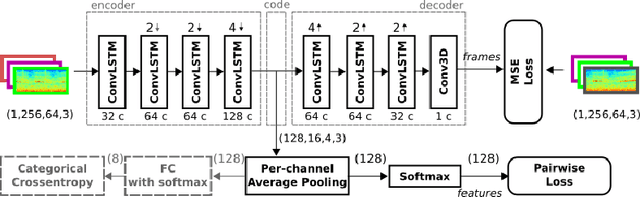
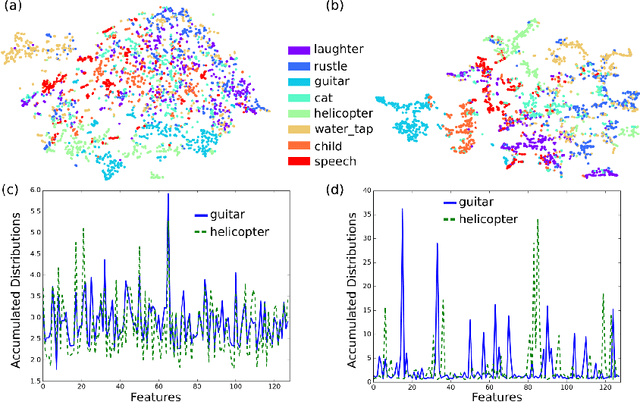
Identifying acoustic events from a continuously streaming audio source is of interest for many applications including environmental monitoring for basic research. In this scenario neither different event classes are known nor what distinguishes one class from another. Therefore, an unsupervised feature learning method for exploration of audio data is presented in this paper. It incorporates the two following novel contributions: First, an audio frame predictor based on a Convolutional LSTM autoencoder is demonstrated, which is used for unsupervised feature extraction. Second, a training method for autoencoders is presented, which leads to distinct features by amplifying event similarities. In comparison to standard approaches, the features extracted from the audio frame predictor trained with the novel approach show 13 % better results when used with a classifier and 36 % better results when used for clustering.