 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Feature Learning for Audio Analysis
Paper and Code
Dec 11, 2017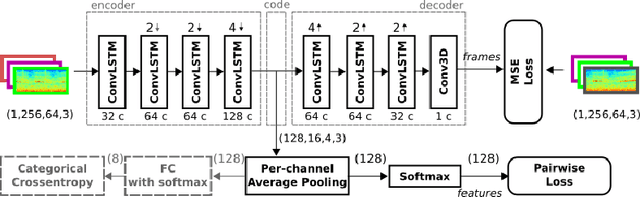
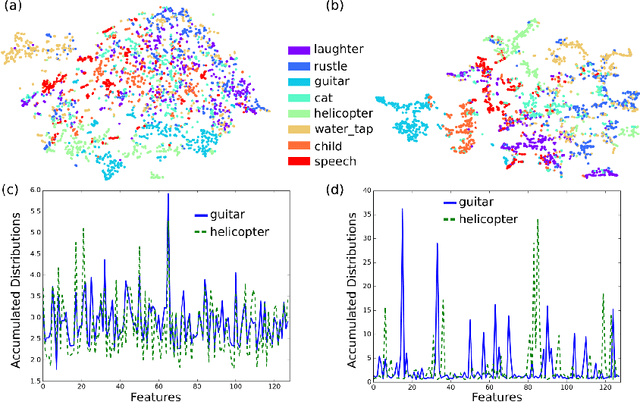
Identifying acoustic events from a continuously streaming audio source is of interest for many applications including environmental monitoring for basic research. In this scenario neither different event classes are known nor what distinguishes one class from another. Therefore, an unsupervised feature learning method for exploration of audio data is presented in this paper. It incorporates the two following novel contributions: First, an audio frame predictor based on a Convolutional LSTM autoencoder is demonstrated, which is used for unsupervised feature extraction. Second, a training method for autoencoders is presented, which leads to distinct features by amplifying event similarities. In comparison to standard approaches, the features extracted from the audio frame predictor trained with the novel approach show 13 % better results when used with a classifier and 36 % better results when used for clustering.