 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Remember, Learn, and Forget in Attention-Based Models
Feb 11, 2026In-Context Learning (ICL) in transformers acts as an online associative memory and is believed to underpin their high performance on complex sequence processing tasks. However, in gated linear attention models, this memory has a fixed capacity and is prone to interference, especially for long sequences. We propose Palimpsa, a self-attention model that views ICL as a continual learning problem that must address a stability-plasticity dilemma. Palimpsa uses Bayesian metaplasticity, where the plasticity of each attention state is tied to an importance state grounded by a prior distribution that captures accumulated knowledge. We demonstrate that various gated linear attention models emerge as specific architecture choices and posterior approximations, and that Mamba2 is a special case of Palimpsa where forgetting dominates. This theoretical link enables the transformation of any non-metaplastic model into a metaplastic one, significantly expanding its memory capacity. Our experiments show that Palimpsa consistently outperforms baselines on the Multi-Query Associative Recall (MQAR) benchmark and on Commonsense Reasoning tasks.
A Truly Sparse and General Implementation of Gradient-Based Synaptic Plasticity
Jan 20, 2025



Online synaptic plasticity rules derived from gradient descent achieve high accuracy on a wide range of practical tasks. However, their software implementation often requires tediously hand-derived gradients or using gradient backpropagation which sacrifices the online capability of the rules. In this work, we present a custom automatic differentiation (AD) pipeline for sparse and online implementation of gradient-based synaptic plasticity rules that generalizes to arbitrary neuron models. Our work combines the programming ease of backpropagation-type methods for forward AD while being memory-efficient. To achieve this, we exploit the advantageous compute and memory scaling of online synaptic plasticity by providing an inherently sparse implementation of AD where expensive tensor contractions are replaced with simple element-wise multiplications if the tensors are diagonal. Gradient-based synaptic plasticity rules such as eligibility propagation (e-prop) have exactly this property and thus profit immensely from this feature. We demonstrate the alignment of our gradients with respect to gradient backpropagation on an synthetic task where e-prop gradients are exact, as well as audio speech classification benchmarks. We demonstrate how memory utilization scales with network size without dependence on the sequence length, as expected from forward AD methods.
SNNAX -- Spiking Neural Networks in JAX
Sep 04, 2024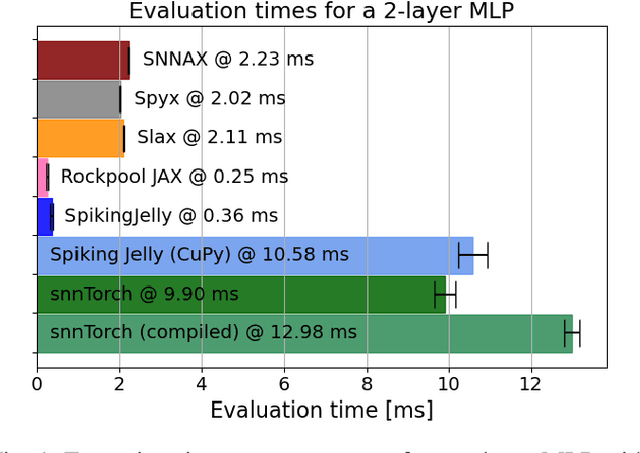
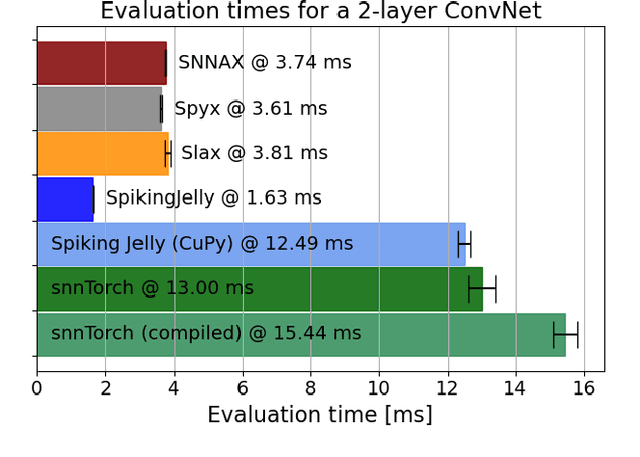
Spiking Neural Networks (SNNs) simulators are essential tools to prototype biologically inspired models and neuromorphic hardware architectures and predict their performance. For such a tool, ease of use and flexibility are critical, but so is simulation speed especially given the complexity inherent to simulating SNN. Here, we present SNNAX, a JAX-based framework for simulating and training such models with PyTorch-like intuitiveness and JAX-like execution speed. SNNAX models are easily extended and customized to fit the desired model specifications and target neuromorphic hardware. Additionally, SNNAX offers key features for optimizing the training and deployment of SNNs such as flexible automatic differentiation and just-in-time compilation. We evaluate and compare SNNAX to other commonly used machine learning (ML) frameworks used for programming SNNs. We provide key performance metrics, best practices, documented examples for simulating SNNs in SNNAX, and implement several benchmarks used in the literature.
Optimizing Automatic Differentiation with Deep Reinforcement Learning
Jun 07, 2024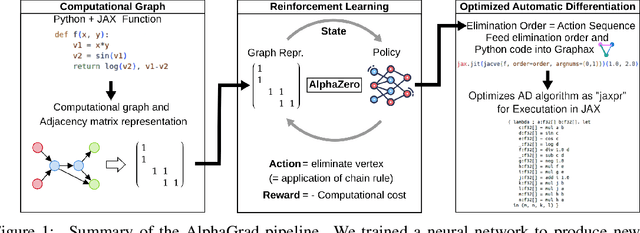
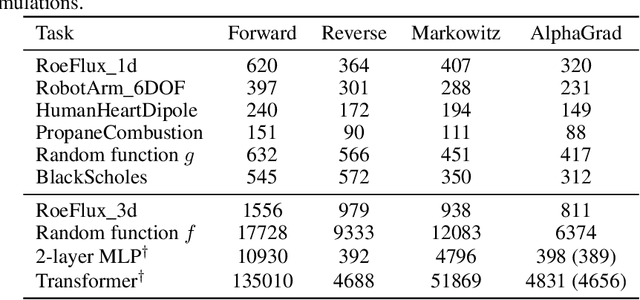
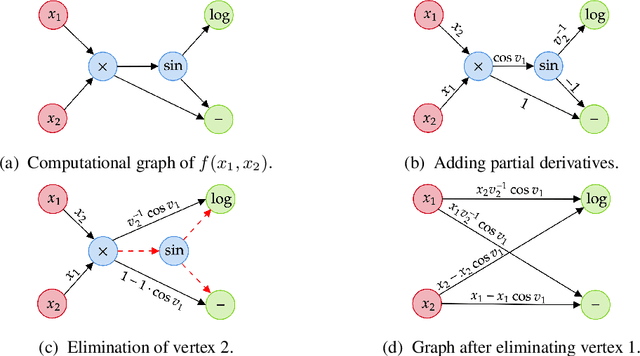
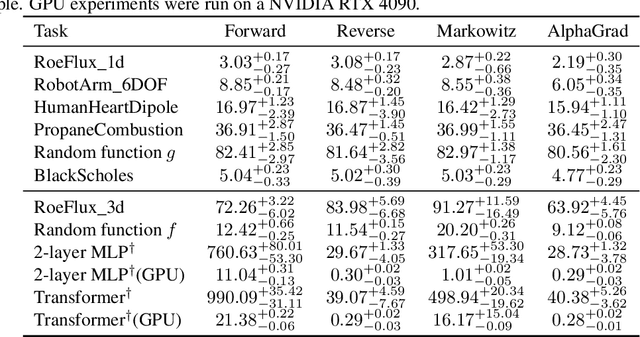
Computing Jacobians with automatic differentiation is ubiquitous in many scientific domains such as machine learning, computational fluid dynamics, robotics and finance. Even small savings in the number of computations or memory usage in Jacobian computations can already incur massive savings in energy consumption and runtime. While there exist many methods that allow for such savings, they generally trade computational efficiency for approximations of the exact Jacobian. In this paper, we present a novel method to optimize the number of necessary multiplications for Jacobian computation by leveraging deep reinforcement learning (RL) and a concept called cross-country elimination while still computing the exact Jacobian. Cross-country elimination is a framework for automatic differentiation that phrases Jacobian accumulation as ordered elimination of all vertices on the computational graph where every elimination incurs a certain computational cost. We formulate the search for the optimal elimination order that minimizes the number of necessary multiplications as a single player game which is played by an RL agent. We demonstrate that this method achieves up to 33% improvements over state-of-the-art methods on several relevant tasks taken from diverse domains. Furthermore, we show that these theoretical gains translate into actual runtime improvements by providing a cross-country elimination interpreter in JAX that can efficiently execute the obtained elimination orders.