 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimPINNs: Simulation-Driven Physics-Informed Neural Networks for Enhanced Performance in Nonlinear Inverse Problems
Sep 27, 2023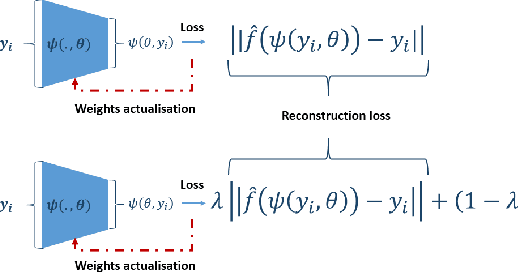
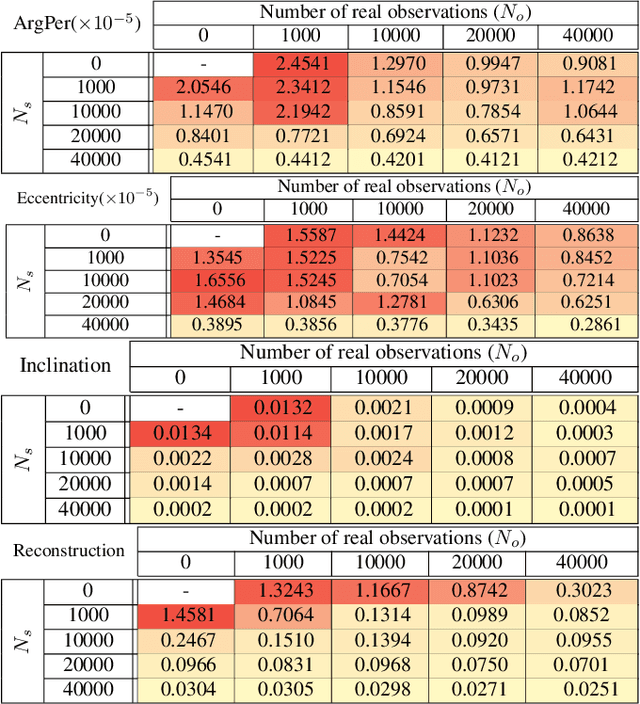
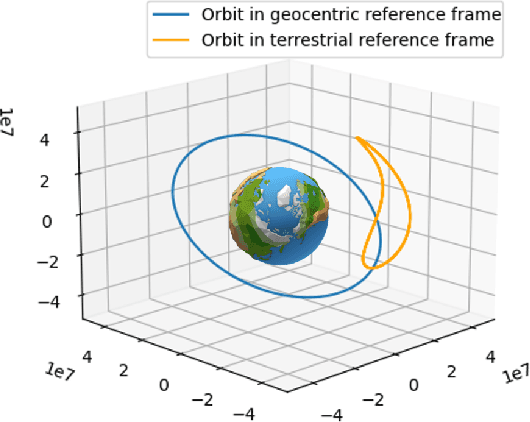
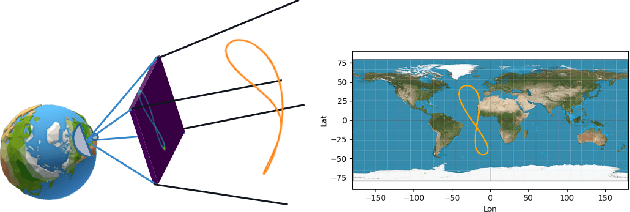
This paper introduces a novel approach to solve inverse problems by leveraging deep learning techniques. The objective is to infer unknown parameters that govern a physical system based on observed data. We focus on scenarios where the underlying forward model demonstrates pronounced nonlinear behaviour, and where the dimensionality of the unknown parameter space is substantially smaller than that of the observations. Our proposed method builds upon physics-informed neural networks (PINNs) trained with a hybrid loss function that combines observed data with simulated data generated by a known (approximate) physical model. Experimental results on an orbit restitution problem demonstrate that our approach surpasses the performance of standard PINNs, providing improved accuracy and robustness.
Low Complexity Regularization of Linear Inverse Problems
Dec 08, 2014Inverse problems and regularization theory is a central theme in contemporary signal processing, where the goal is to reconstruct an unknown signal from partial indirect, and possibly noisy, measurements of it. A now standard method for recovering the unknown signal is to solve a convex optimization problem that enforces some prior knowledge about its structure. This has proved efficient in many problems routinely encountered in imaging sciences, statistics and machine learning. This chapter delivers a review of recent advances in the field where the regularization prior promotes solutions conforming to some notion of simplicity/low-complexity. These priors encompass as popular examples sparsity and group sparsity (to capture the compressibility of natural signals and images), total variation and analysis sparsity (to promote piecewise regularity), and low-rank (as natural extension of sparsity to matrix-valued data). Our aim is to provide a unified treatment of all these regularizations under a single umbrella, namely the theory of partial smoothness. This framework is very general and accommodates all low-complexity regularizers just mentioned, as well as many others. Partial smoothness turns out to be the canonical way to encode low-dimensional models that can be linear spaces or more general smooth manifolds. This review is intended to serve as a one stop shop toward the understanding of the theoretical properties of the so-regularized solutions. It covers a large spectrum including: (i) recovery guarantees and stability to noise, both in terms of $\ell^2$-stability and model (manifold) identification; (ii) sensitivity analysis to perturbations of the parameters involved (in particular the observations), with applications to unbiased risk estimation ; (iii) convergence properties of the forward-backward proximal splitting scheme, that is particularly well suited to solve the corresponding large-scale regularized optimization problem.
Model Consistency of Partly Smooth Regularizers
Jun 29, 2014

This paper studies least-square regression penalized with partly smooth convex regularizers. This class of functions is very large and versatile allowing to promote solutions conforming to some notion of low-complexity. Indeed, they force solutions of variational problems to belong to a low-dimensional manifold (the so-called model) which is stable under small perturbations of the function. This property is crucial to make the underlying low-complexity model robust to small noise. We show that a generalized "irrepresentable condition" implies stable model selection under small noise perturbations in the observations and the design matrix, when the regularization parameter is tuned proportionally to the noise level. This condition is shown to be almost a necessary condition. We then show that this condition implies model consistency of the regularized estimator. That is, with a probability tending to one as the number of measurements increases, the regularized estimator belongs to the correct low-dimensional model manifold. This work unifies and generalizes several previous ones, where model consistency is known to hold for sparse, group sparse, total variation and low-rank regularizations.