 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable machine learning multi-label classification of Spanish legal judgements
May 27, 2024
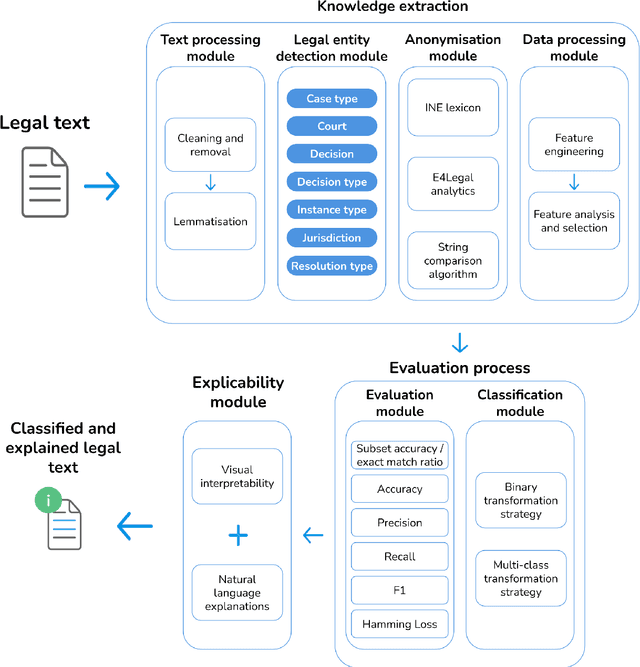


Artificial Intelligence techniques such as Machine Learning (ML) have not been exploited to their maximum potential in the legal domain. This has been partially due to the insufficient explanations they provided about their decisions. Automatic expert systems with explanatory capabilities can be specially useful when legal practitioners search jurisprudence to gather contextual knowledge for their cases. Therefore, we propose a hybrid system that applies ML for multi-label classification of judgements (sentences) and visual and natural language descriptions for explanation purposes, boosted by Natural Language Processing techniques and deep legal reasoning to identify the entities, such as the parties, involved. We are not aware of any prior work on automatic multi-label classification of legal judgements also providing natural language explanations to the end-users with comparable overall quality. Our solution achieves over 85 % micro precision on a labelled data set annotated by legal experts. This endorses its interest to relieve human experts from monotonous labour-intensive legal classification tasks.
Explainable automatic industrial carbon footprint estimation from bank transaction classification using natural language processing
May 23, 2024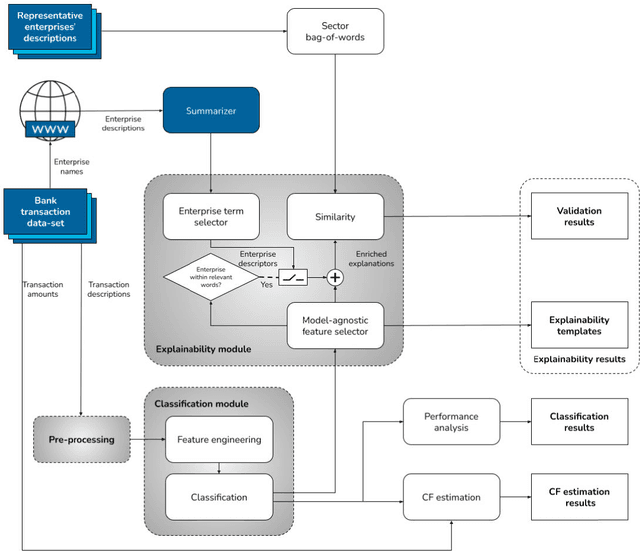

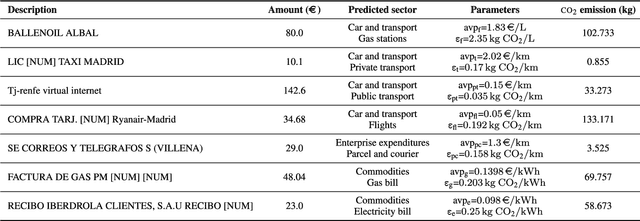
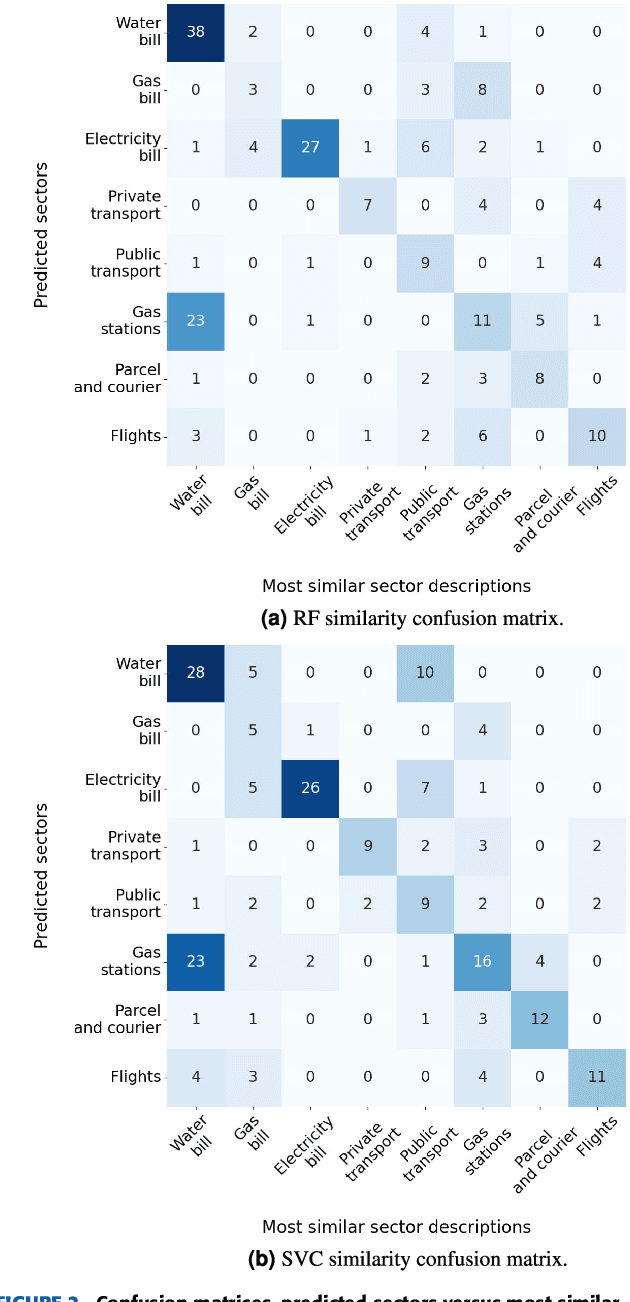
Concerns about the effect of greenhouse gases have motivated the development of certification protocols to quantify the industrial carbon footprint (CF). These protocols are manual, work-intensive, and expensive. All of the above have led to a shift towards automatic data-driven approaches to estimate the CF, including Machine Learning (ML) solutions. Unfortunately, the decision-making processes involved in these solutions lack transparency from the end user's point of view, who must blindly trust their outcomes compared to intelligible traditional manual approaches. In this research, manual and automatic methodologies for CF estimation were reviewed, taking into account their transparency limitations. This analysis led to the proposal of a new explainable ML solution for automatic CF calculations through bank transaction classification. Consideration should be given to the fact that no previous research has considered the explainability of bank transaction classification for this purpose. For classification, different ML models have been employed based on their promising performance in the literature, such as Support Vector Machine, Random Forest, and Recursive Neural Networks. The results obtained were in the 90 % range for accuracy, precision, and recall evaluation metrics. From their decision paths, the proposed solution estimates the CO2 emissions associated with bank transactions. The explainability methodology is based on an agnostic evaluation of the influence of the input terms extracted from the descriptions of transactions using locally interpretable models. The explainability terms were automatically validated using a similarity metric over the descriptions of the target categories. Conclusively, the explanation performance is satisfactory in terms of the proximity of the explanations to the associated activity sector descriptions.
Automatic explanation of the classification of Spanish legal judgments in jurisdiction-dependent law categories with tree estimators
Mar 30, 2024



Automatic legal text classification systems have been proposed in the literature to address knowledge extraction from judgments and detect their aspects. However, most of these systems are black boxes even when their models are interpretable. This may raise concerns about their trustworthiness. Accordingly, this work contributes with a system combining Natural Language Processing (NLP) with Machine Learning (ML) to classify legal texts in an explainable manner. We analyze the features involved in the decision and the threshold bifurcation values of the decision paths of tree structures and present this information to the users in natural language. This is the first work on automatic analysis of legal texts combining NLP and ML along with Explainable Artificial Intelligence techniques to automatically make the models' decisions understandable to end users. Furthermore, legal experts have validated our solution, and this knowledge has also been incorporated into the explanation process as "expert-in-the-loop" dictionaries. Experimental results on an annotated data set in law categories by jurisdiction demonstrate that our system yields competitive classification performance, with accuracy values well above 90%, and that its automatic explanations are easily understandable even to non-expert users.