 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeployment of a Robust and Explainable Mortality Prediction Model: The COVID-19 Pandemic and Beyond
Nov 28, 2023This study investigated the performance, explainability, and robustness of deployed artificial intelligence (AI) models in predicting mortality during the COVID-19 pandemic and beyond. The first study of its kind, we found that Bayesian Neural Networks (BNNs) and intelligent training techniques allowed our models to maintain performance amidst significant data shifts. Our results emphasize the importance of developing robust AI models capable of matching or surpassing clinician predictions, even under challenging conditions. Our exploration of model explainability revealed that stochastic models generate more diverse and personalized explanations thereby highlighting the need for AI models that provide detailed and individualized insights in real-world clinical settings. Furthermore, we underscored the importance of quantifying uncertainty in AI models which enables clinicians to make better-informed decisions based on reliable predictions. Our study advocates for prioritizing implementation science in AI research for healthcare and ensuring that AI solutions are practical, beneficial, and sustainable in real-world clinical environments. By addressing unique challenges and complexities in healthcare settings, researchers can develop AI models that effectively improve clinical practice and patient outcomes.
Revisiting the Fragility of Influence Functions
Mar 22, 2023
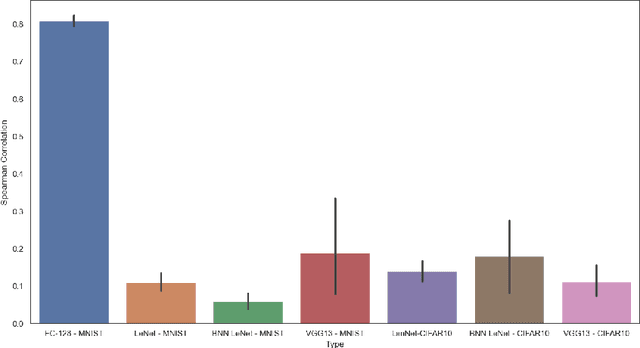


In the last few years, many works have tried to explain the predictions of deep learning models. Few methods, however, have been proposed to verify the accuracy or faithfulness of these explanations. Recently, influence functions, which is a method that approximates the effect that leave-one-out training has on the loss function, has been shown to be fragile. The proposed reason for their fragility remains unclear. Although previous work suggests the use of regularization to increase robustness, this does not hold in all cases. In this work, we seek to investigate the experiments performed in the prior work in an effort to understand the underlying mechanisms of influence function fragility. First, we verify influence functions using procedures from the literature under conditions where the convexity assumptions of influence functions are met. Then, we relax these assumptions and study the effects of non-convexity by using deeper models and more complex datasets. Here, we analyze the key metrics and procedures that are used to validate influence functions. Our results indicate that the validation procedures may cause the observed fragility.