 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATBench: A Compiler Autotuning Benchmarking Suite for Black-box Optimization
Jun 24, 2024Bayesian optimization is a powerful method for automating tuning of compilers. The complex landscape of autotuning provides a myriad of rarely considered structural challenges for black-box optimizers, and the lack of standardized benchmarks has limited the study of Bayesian optimization within the domain. To address this, we present CATBench, a comprehensive benchmarking suite that captures the complexities of compiler autotuning, ranging from discrete, conditional, and permutation parameter types to known and unknown binary constraints, as well as both multi-fidelity and multi-objective evaluations. The benchmarks in CATBench span a range of machine learning-oriented computations, from tensor algebra to image processing and clustering, and uses state-of-the-art compilers, such as TACO and RISE/ELEVATE. CATBench offers a unified interface for evaluating Bayesian optimization algorithms, promoting reproducibility and innovation through an easy-to-use, fully containerized setup of both surrogate and real-world compiler optimization tasks. We validate CATBench on several state-of-the-art algorithms, revealing their strengths and weaknesses and demonstrating the suite's potential for advancing both Bayesian optimization and compiler autotuning research.
LS-CAT: A Large-Scale CUDA AutoTuning Dataset
Mar 26, 2021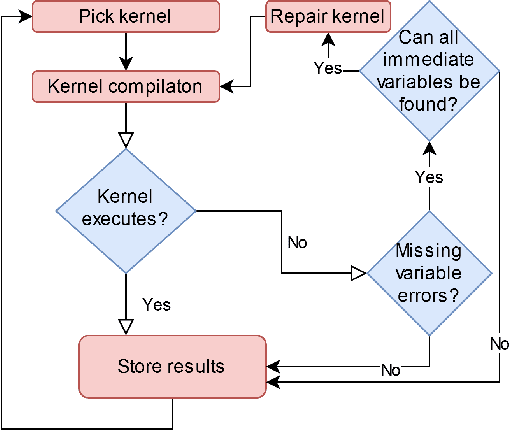
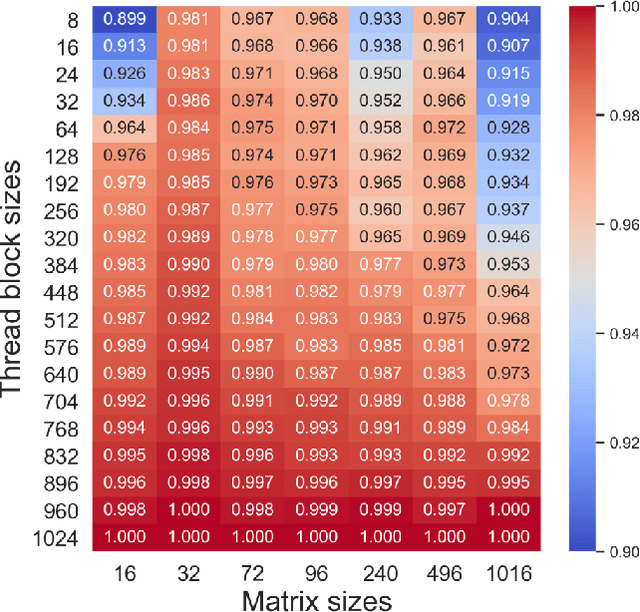
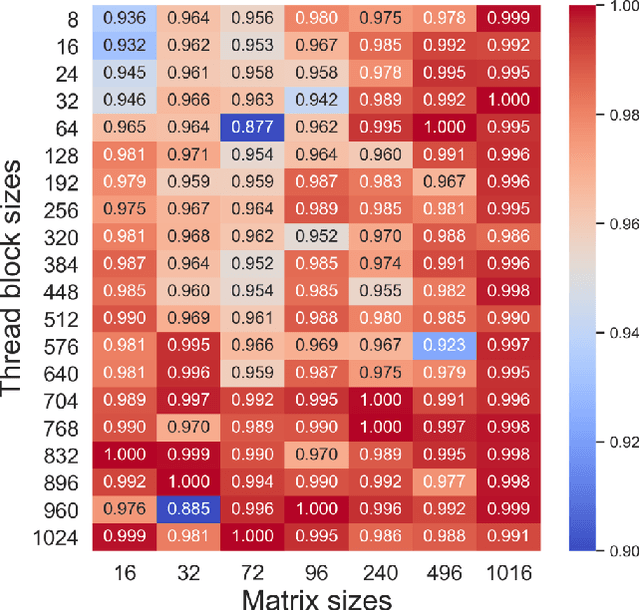
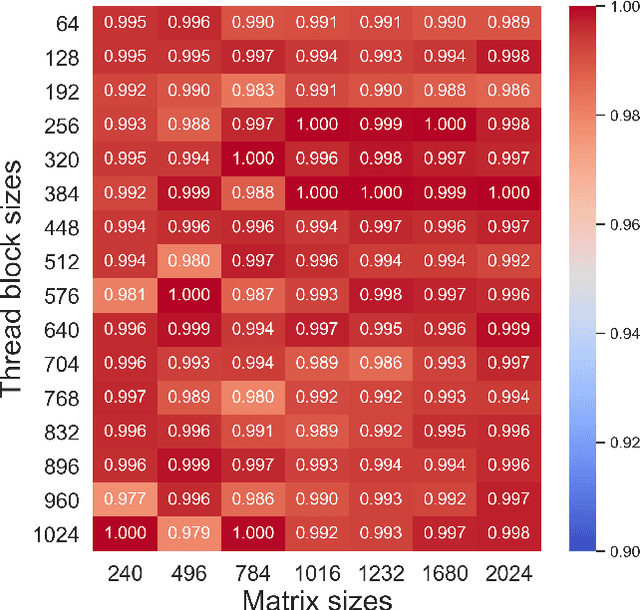
The effectiveness of Machine Learning (ML) methods depend on access to large suitable datasets. In this article, we present how we build the LS-CAT (Large-Scale CUDA AutoTuning) dataset sourced from GitHub for the purpose of training NLP-based ML models. Our dataset includes 19 683 CUDA kernels focused on linear algebra. In addition to the CUDA codes, our LS-CAT dataset contains 5 028 536 associated runtimes, with different combinations of kernels, block sizes and matrix sizes. The runtime are GPU benchmarks on both Nvidia GTX 980 and Nvidia T4 systems. This information creates a foundation upon which NLP-based models can find correlations between source-code features and optimal choice of thread block sizes. There are several results that can be drawn out of our LS-CAT database. E.g., our experimental results show that an optimal choice in thread block size can gain an average of 6% for the average case. We thus also analyze how much performance increase can be achieved in general, finding that in 10% of the cases more than 20% performance increase can be achieved by using the optimal block. A description of current and future work is also included.