 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a Critical Toponymy Framework for Named Entity Recognition: A Case Study of Airbnb in New York City
Oct 23, 2023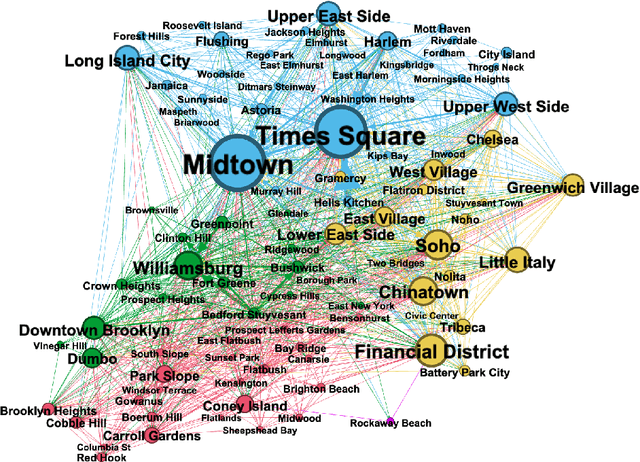



Critical toponymy examines the dynamics of power, capital, and resistance through place names and the sites to which they refer. Studies here have traditionally focused on the semantic content of toponyms and the top-down institutional processes that produce them. However, they have generally ignored the ways in which toponyms are used by ordinary people in everyday discourse, as well as the other strategies of geospatial description that accompany and contextualize toponymic reference. Here, we develop computational methods to measure how cultural and economic capital shape the ways in which people refer to places, through a novel annotated dataset of 47,440 New York City Airbnb listings from the 2010s. Building on this dataset, we introduce a new named entity recognition (NER) model able to identify important discourse categories integral to the characterization of place. Our findings point toward new directions for critical toponymy and to a range of previously understudied linguistic signals relevant to research on neighborhood status, housing and tourism markets, and gentrification.
What company do words keep? Revisiting the distributional semantics of J.R. Firth & Zellig Harris
May 16, 2022The power of word embeddings is attributed to the linguistic theory that similar words will appear in similar contexts. This idea is specifically invoked by noting that "you shall know a word by the company it keeps," a quote from British linguist J.R. Firth who, along with his American colleague Zellig Harris, is often credited with the invention of "distributional semantics." While both Firth and Harris are cited in all major NLP textbooks and many foundational papers, the content and differences between their theories is seldom discussed. Engaging in a close reading of their work, we discover two distinct and in many ways divergent theories of meaning. One focuses exclusively on the internal workings of linguistic forms, while the other invites us to consider words in new company - not just with other linguistic elements, but also in a broader cultural and situational context. Contrasting these theories from the perspective of current debates in NLP, we discover in Firth a figure who could guide the field towards a more culturally grounded notion of semantics. We consider how an expanded notion of "context" might be modeled in practice through two different strategies: comparative stratification and syntagmatic extension
WMDecompose: A Framework for Leveraging the Interpretable Properties of Word Mover's Distance in Sociocultural Analysis
Oct 14, 2021

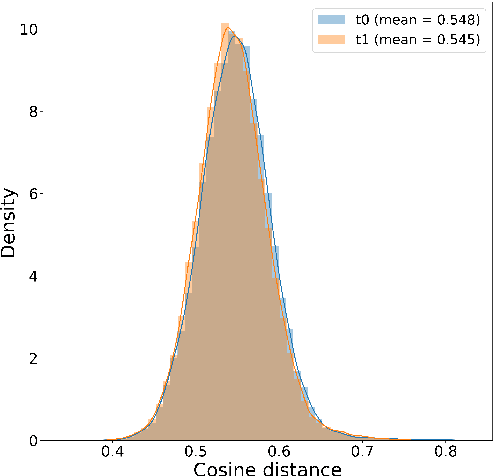
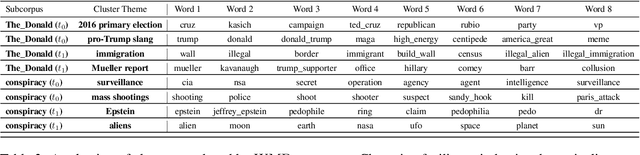
Despite the increasing popularity of NLP in the humanities and social sciences, advances in model performance and complexity have been accompanied by concerns about interpretability and explanatory power for sociocultural analysis. One popular model that balances complexity and legibility is Word Mover's Distance (WMD). Ostensibly adapted for its interpretability, WMD has nonetheless been used and further developed in ways which frequently discard its most interpretable aspect: namely, the word-level distances required for translating a set of words into another set of words. To address this apparent gap, we introduce WMDecompose: a model and Python library that 1) decomposes document-level distances into their constituent word-level distances, and 2) subsequently clusters words to induce thematic elements, such that useful lexical information is retained and summarized for analysis. To illustrate its potential in a social scientific context, we apply it to a longitudinal social media corpus to explore the interrelationship between conspiracy theories and conservative American discourses. Finally, because of the full WMD model's high time-complexity, we additionally suggest a method of sampling document pairs from large datasets in a reproducible way, with tight bounds that prevent extrapolation of unreliable results due to poor sampling practices.