 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWMDecompose: A Framework for Leveraging the Interpretable Properties of Word Mover's Distance in Sociocultural Analysis
Paper and Code


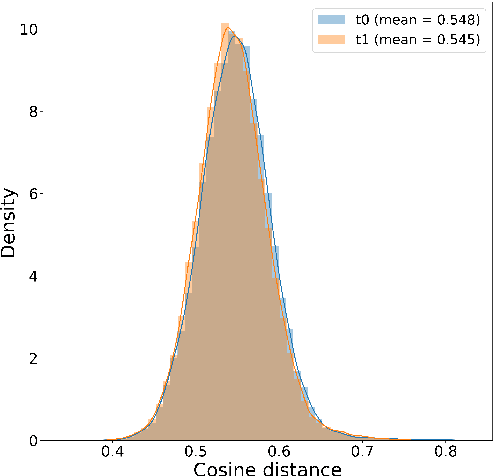
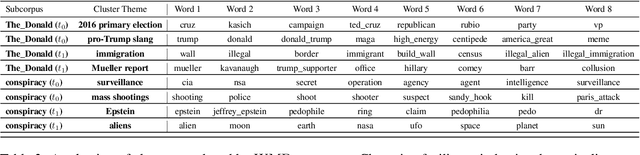
Despite the increasing popularity of NLP in the humanities and social sciences, advances in model performance and complexity have been accompanied by concerns about interpretability and explanatory power for sociocultural analysis. One popular model that balances complexity and legibility is Word Mover's Distance (WMD). Ostensibly adapted for its interpretability, WMD has nonetheless been used and further developed in ways which frequently discard its most interpretable aspect: namely, the word-level distances required for translating a set of words into another set of words. To address this apparent gap, we introduce WMDecompose: a model and Python library that 1) decomposes document-level distances into their constituent word-level distances, and 2) subsequently clusters words to induce thematic elements, such that useful lexical information is retained and summarized for analysis. To illustrate its potential in a social scientific context, we apply it to a longitudinal social media corpus to explore the interrelationship between conspiracy theories and conservative American discourses. Finally, because of the full WMD model's high time-complexity, we additionally suggest a method of sampling document pairs from large datasets in a reproducible way, with tight bounds that prevent extrapolation of unreliable results due to poor sampling practices.