 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Are the Facts? Automated Extraction of Court-Established Facts from Criminal-Court Opinions
Nov 07, 2025

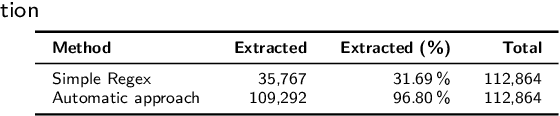
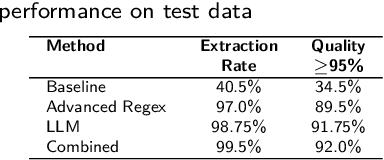
Criminal justice administrative data contain only a limited amount of information about the committed offense. However, there is an unused source of extensive information in continental European courts' decisions: descriptions of criminal behaviors in verdicts by which offenders are found guilty. In this paper, we study the feasibility of extracting these descriptions from publicly available court decisions from Slovakia. We use two different approaches for retrieval: regular expressions and large language models (LLMs). Our baseline was a simple method employing regular expressions to identify typical words occurring before and after the description. The advanced regular expression approach further focused on "sparing" and its normalization (insertion of spaces between individual letters), typical for delineating the description. The LLM approach involved prompting the Gemini Flash 2.0 model to extract the descriptions using predefined instructions. Although the baseline identified descriptions in only 40.5% of verdicts, both methods significantly outperformed it, achieving 97% with advanced regular expressions and 98.75% with LLMs, and 99.5% when combined. Evaluation by law students showed that both advanced methods matched human annotations in about 90% of cases, compared to just 34.5% for the baseline. LLMs fully matched human-labeled descriptions in 91.75% of instances, and a combination of advanced regular expressions with LLMs reached 92%.
Boosting Unsupervised Machine Translation with Pseudo-Parallel Data
Oct 22, 2023



Even with the latest developments in deep learning and large-scale language modeling, the task of machine translation (MT) of low-resource languages remains a challenge. Neural MT systems can be trained in an unsupervised way without any translation resources but the quality lags behind, especially in truly low-resource conditions. We propose a training strategy that relies on pseudo-parallel sentence pairs mined from monolingual corpora in addition to synthetic sentence pairs back-translated from monolingual corpora. We experiment with different training schedules and reach an improvement of up to 14.5 BLEU points (English to Ukrainian) over a baseline trained on back-translated data only.
* MT Summit 2023
CUNI Systems for the Unsupervised and Very Low Resource Translation Task in WMT20
Oct 22, 2020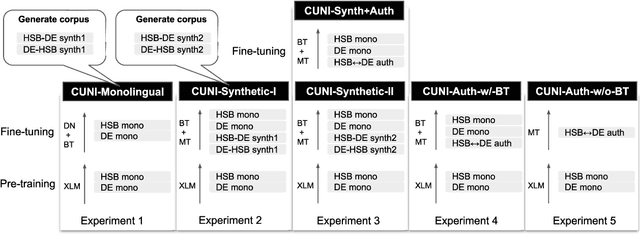
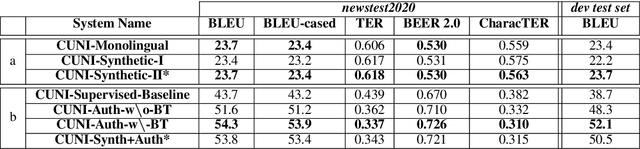
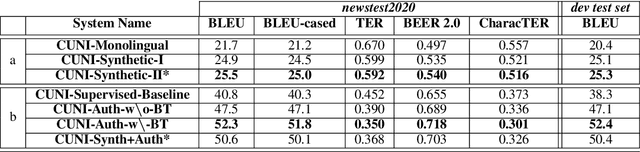
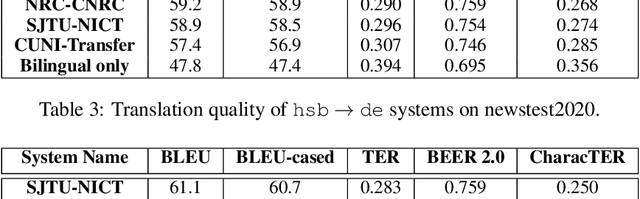
This paper presents a description of CUNI systems submitted to the WMT20 task on unsupervised and very low-resource supervised machine translation between German and Upper Sorbian. We experimented with training on synthetic data and pre-training on a related language pair. In the fully unsupervised scenario, we achieved 25.5 and 23.7 BLEU translating from and into Upper Sorbian, respectively. Our low-resource systems relied on transfer learning from German-Czech parallel data and achieved 57.4 BLEU and 56.1 BLEU, which is an improvement of 10 BLEU points over the baseline trained only on the available small German-Upper Sorbian parallel corpus.
CUNI Systems for the Unsupervised News Translation Task in WMT 2019
Jul 29, 2019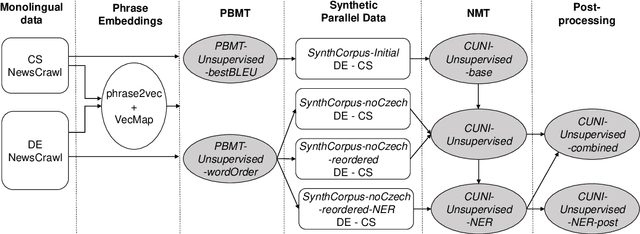
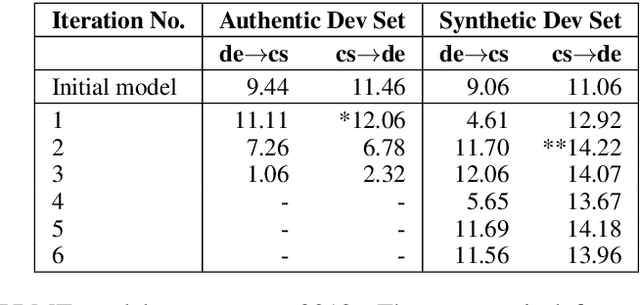
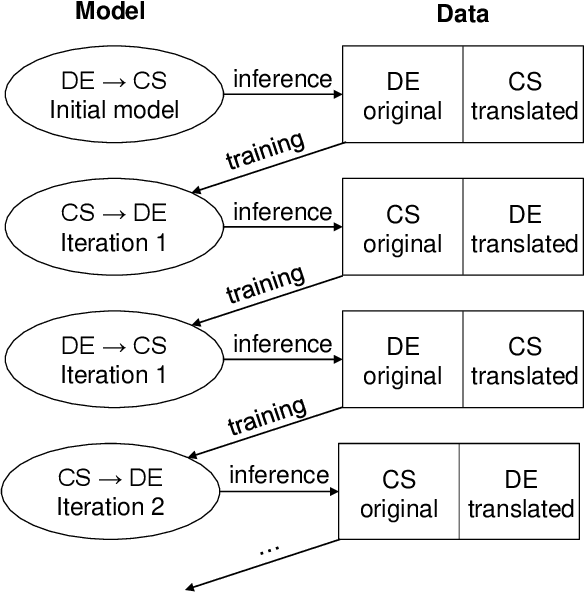
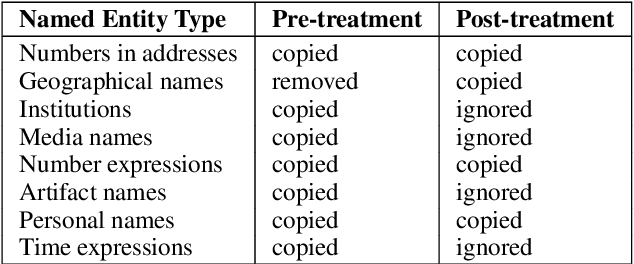
In this paper we describe the CUNI translation system used for the unsupervised news shared task of the ACL 2019 Fourth Conference on Machine Translation (WMT19). We follow the strategy of Artexte et al. (2018b), creating a seed phrase-based system where the phrase table is initialized from cross-lingual embedding mappings trained on monolingual data, followed by a neural machine translation system trained on synthetic parallel data. The synthetic corpus was produced from a monolingual corpus by a tuned PBMT model refined through iterative back-translation. We further focus on the handling of named entities, i.e. the part of vocabulary where the cross-lingual embedding mapping suffers most. Our system reaches a BLEU score of 15.3 on the German-Czech WMT19 shared task.