 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Tricks are Important for Learning to Rank?
Apr 04, 2022
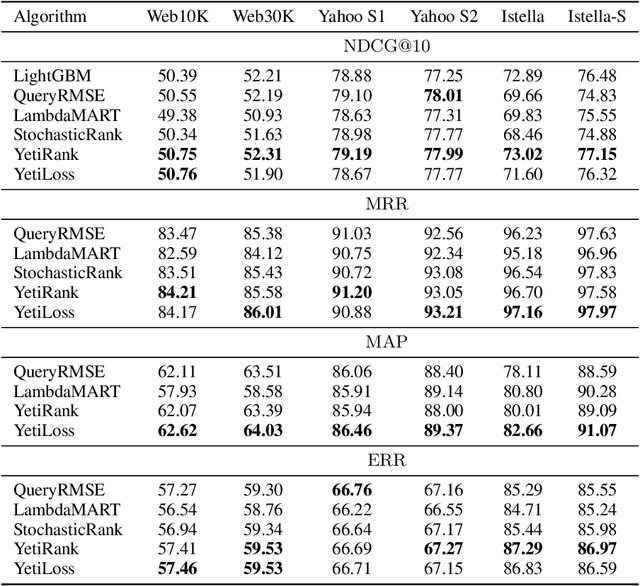
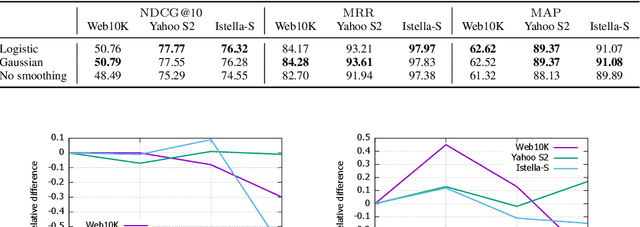
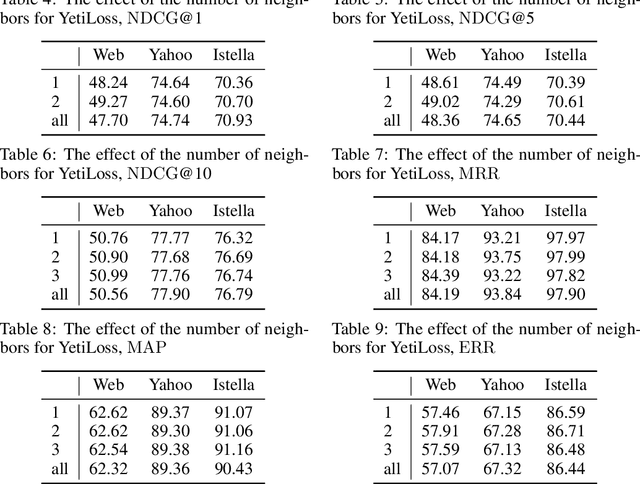
Nowadays, state-of-the-art learning-to-rank (LTR) methods are based on gradient-boosted decision trees (GBDT). The most well-known algorithm is LambdaMART that was proposed more than a decade ago. Recently, several other GBDT-based ranking algorithms were proposed. In this paper, we conduct a thorough analysis of these methods in a unified setup. In particular, we address the following questions. Is direct optimization of a smoothed ranking loss preferable over optimizing a convex surrogate? How to properly construct and smooth surrogate ranking losses? To address these questions, we compare LambdaMART with YetiRank and StochasticRank methods and their modifications. We also improve the YetiRank approach to allow for optimizing specific ranking loss functions. As a result, we gain insights into learning-to-rank approaches and obtain a new state-of-the-art algorithm.