 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear stimulus reconstruction works on the KU Leuven audiovisual, gaze-controlled auditory attention decoding dataset
Dec 02, 2024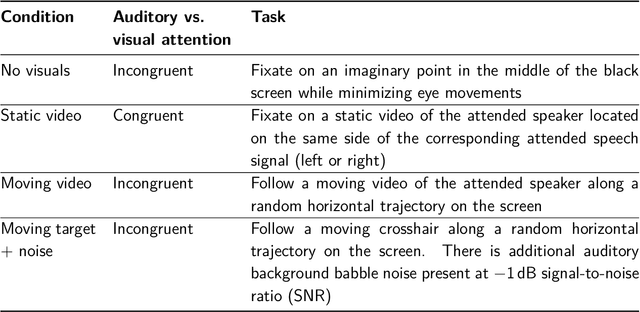
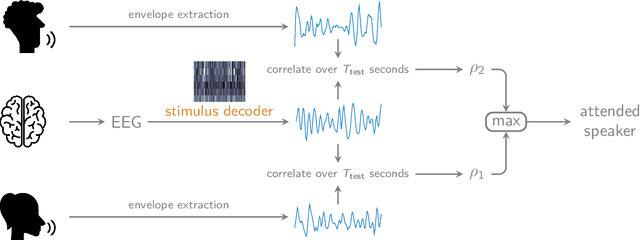
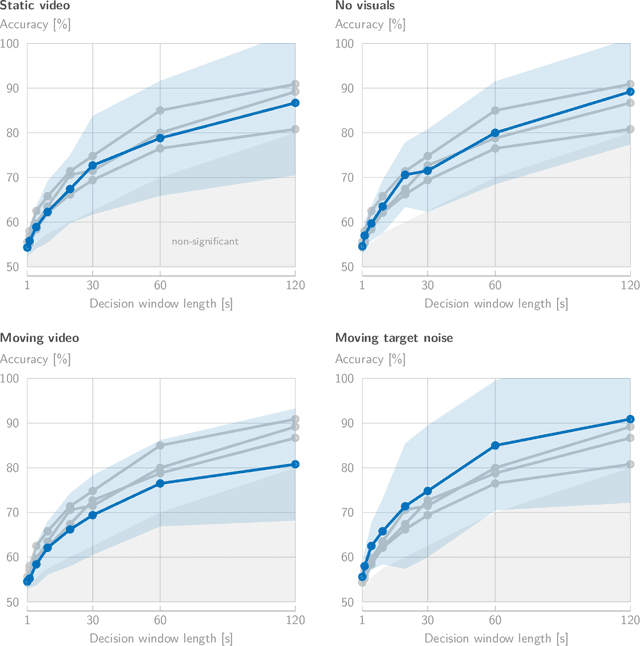
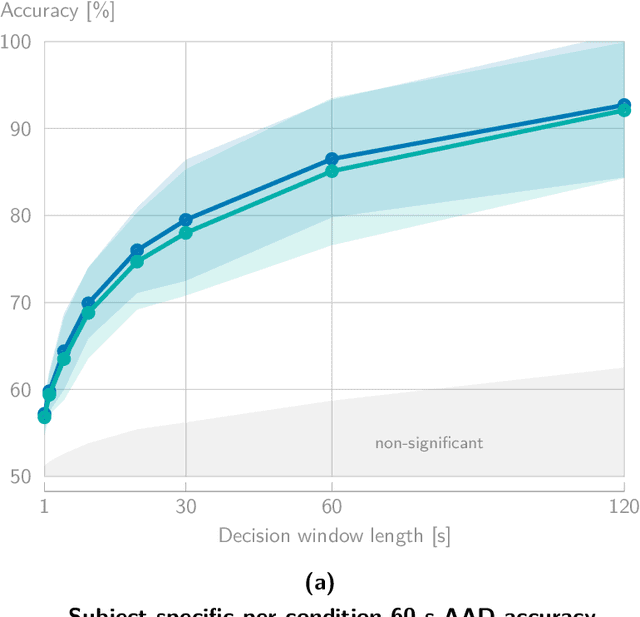
In a recent paper, we presented the KU Leuven audiovisual, gaze-controlled auditory attention decoding (AV-GC-AAD) dataset, in which we recorded electroencephalography (EEG) signals of participants attending to one out of two competing speakers under various audiovisual conditions. The main goal of this dataset was to disentangle the direction of gaze from the direction of auditory attention, in order to reveal gaze-related shortcuts in existing spatial AAD algorithms that aim to decode the (direction of) auditory attention directly from the EEG. Various methods based on spatial AAD do not achieve significant above-chance performances on our AV-GC-AAD dataset, indicating that previously reported results were mainly driven by eye gaze confounds in existing datasets. Still, these adverse outcomes are often discarded for reasons that are attributed to the limitations of the AV-GC-AAD dataset, such as the limited amount of data to train a working model, too much data heterogeneity due to different audiovisual conditions, or participants allegedly being unable to focus their auditory attention under the complex instructions. In this paper, we present the results of the linear stimulus reconstruction AAD algorithm and show that high AAD accuracy can be obtained within each individual condition and that the model generalizes across conditions, across new subjects, and even across datasets. Therefore, we eliminate any doubts that the inadequacy of the AV-GC-AAD dataset is the primary reason for the (spatial) AAD algorithms failing to achieve above-chance performance when compared to other datasets. Furthermore, this report provides a simple baseline evaluation procedure (including source code) that can serve as the minimal benchmark for all future AAD algorithms evaluated on this dataset.