 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetric Kernels with Non-Symmetric Data: A Data-Agnostic Learnability Bound
Jun 04, 2024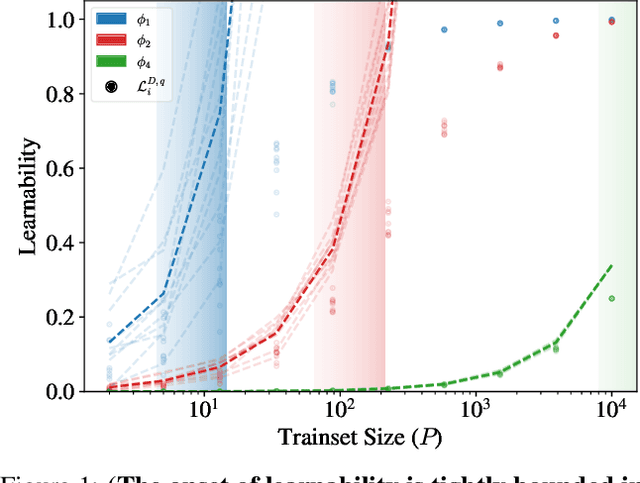
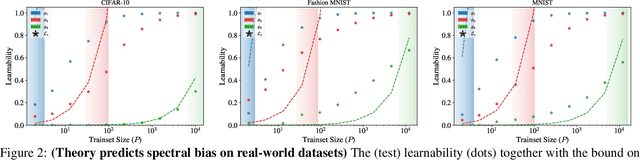
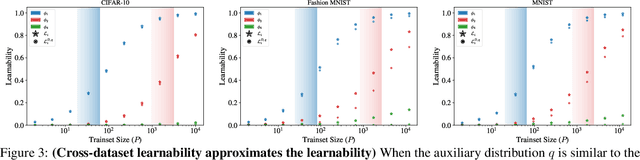
Kernel ridge regression (KRR) and Gaussian processes (GPs) are fundamental tools in statistics and machine learning with recent applications to highly over-parameterized deep neural networks. The ability of these tools to learn a target function is directly related to the eigenvalues of their kernel sampled on the input data. Targets having support on higher eigenvalues are more learnable. While kernels are often highly symmetric objects, the data is often not. Thus kernel symmetry seems to have little to no bearing on the above eigenvalues or learnability, making spectral analysis on real-world data challenging. Here, we show that contrary to this common lure, one may use eigenvalues and eigenfunctions associated with highly idealized data-measures to bound learnability on realistic data. As a demonstration, we give a theoretical lower bound on the sample complexity of copying heads for kernels associated with generic transformers acting on natural language.
Towards Understanding Inductive Bias in Transformers: A View From Infinity
Feb 07, 2024

We study inductive bias in Transformers in the infinitely over-parameterized Gaussian process limit and argue transformers tend to be biased towards more permutation symmetric functions in sequence space. We show that the representation theory of the symmetric group can be used to give quantitative analytical predictions when the dataset is symmetric to permutations between tokens. We present a simplified transformer block and solve the model at the limit, including accurate predictions for the learning curves and network outputs. We show that in common setups, one can derive tight bounds in the form of a scaling law for the learnability as a function of the context length. Finally, we argue WikiText dataset, does indeed possess a degree of permutation symmetry.