 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCensus-Independent Population Estimation using Representation Learning
Oct 06, 2021
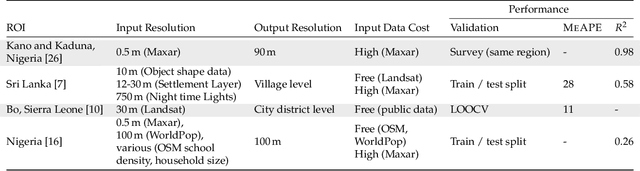

Knowledge of population distribution is critical for building infrastructure, distributing resources, and monitoring the progress of sustainable development goals. Although censuses can provide this information, they are typically conducted every ten years with some countries having forgone the process for several decades. Population can change in the intercensal period due to rapid migration, development, urbanisation, natural disasters, and conflicts. Census-independent population estimation approaches using alternative data sources, such as satellite imagery, have shown promise in providing frequent and reliable population estimates locally. Existing approaches, however, require significant human supervision, for example annotating buildings and accessing various public datasets, and therefore, are not easily reproducible. We explore recent representation learning approaches, and assess the transferability of representations to population estimation in Mozambique. Using representation learning reduces required human supervision, since features are extracted automatically, making the process of population estimation more sustainable and likely to be transferable to other regions or countries. We compare the resulting population estimates to existing population products from GRID3, Facebook (HRSL) and WorldPop. We observe that our approach matches the most accurate of these maps, and is interpretable in the sense that it recognises built-up areas to be an informative indicator of population.
Towards Sustainable Census Independent Population Estimation in Mozambique
Apr 26, 2021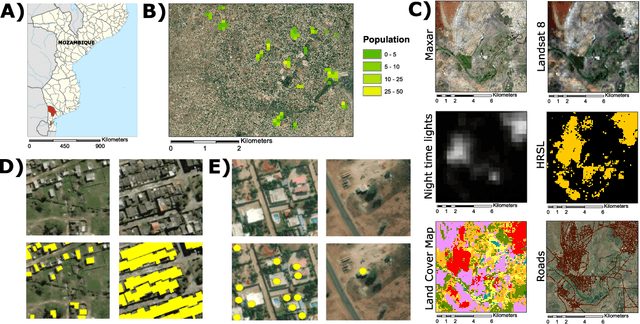
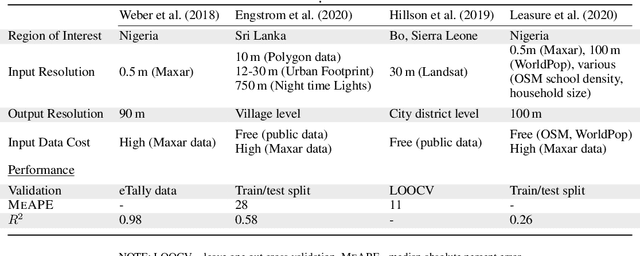
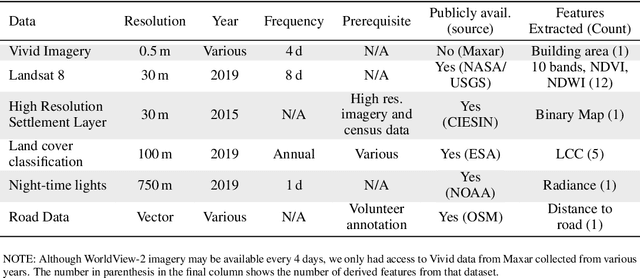
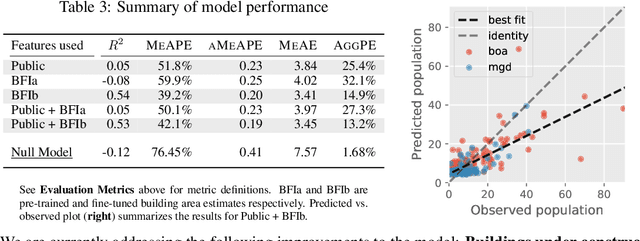
Reliable and frequent population estimation is key for making policies around vaccination and planning infrastructure delivery. Since censuses lack the spatio-temporal resolution required for these tasks, census-independent approaches, using remote sensing and microcensus data, have become popular. We estimate intercensal population count in two pilot districts in Mozambique. To encourage sustainability, we assess the feasibility of using publicly available datasets to estimate population. We also explore transfer learning with existing annotated datasets for predicting building footprints, and training with additional `dot' annotations from regions of interest to enhance these estimations. We observe that population predictions improve when using footprint area estimated with this approach versus only publicly available features.