 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating large adversarial perturbations on X-MAS (X minus Moving Averaged Samples)
Jan 23, 2020
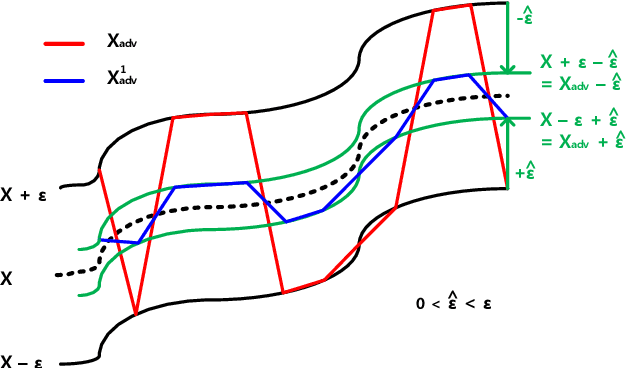

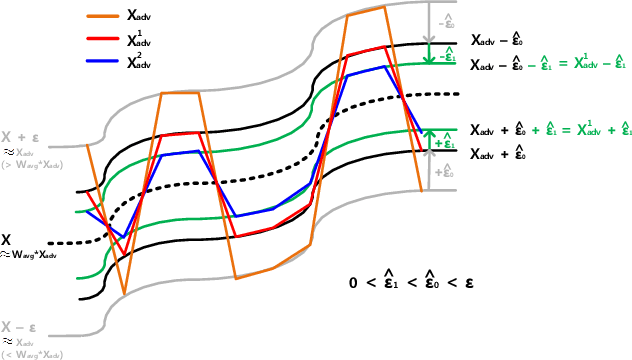
We propose the scheme that mitigates the adversarial perturbation $\epsilon$ on the adversarial example $X_{adv}$ ($=$ $X$ $\pm$ $\epsilon$, $X$ is a benign sample) by subtracting the estimated perturbation $\hat{\epsilon}$ from $X$ $+$ $\epsilon$ and adding $\hat{\epsilon}$ to $X$ $-$ $\epsilon$. The estimated perturbation $\hat{\epsilon}$ comes from the difference between $X_{adv}$ and its moving-averaged outcome $W_{avg}*X_{adv}$ where $W_{avg}$ is $N \times N$ moving average kernel that all the coefficients are one. Usually, the adjacent samples of an image are close to each other such that we can let $X$ $\approx$ $W_{avg}*X$ (naming this relation after X-MAS[X minus Moving Averaged Samples]). By doing that, we can make the estimated perturbation $\hat{\epsilon}$ falls within the range of $\epsilon$. The scheme is also extended to do the multi-level mitigation by configuring the mitigated adversarial example $X_{adv}$ $\pm$ $\hat{\epsilon}$ as a new adversarial example to be mitigated. The multi-level mitigation gets $X_{adv}$ closer to $X$ with a smaller (i.e. mitigated) perturbation than original unmitigated perturbation by setting the moving averaged adversarial sample $W_{avg} * X_{adv}$ (which has the smaller perturbation than $X_{adv}$ if $X$ $\approx$ $W_{avg}*X$) as the boundary condition that the multi-level mitigation cannot cross over (i.e. decreasing $\epsilon$ cannot go below and increasing $\epsilon$ cannot go beyond). With the multi-level mitigation, we can get high prediction accuracies even in the adversarial example having a large perturbation (i.e. $\epsilon$ $>$ $16$). The proposed scheme is evaluated with adversarial examples crafted by the FGSM (Fast Gradient Sign Method) based attacks on ResNet-50 trained with ImageNet dataset.
Convolutional Neural Network Quantization using Generalized Gamma Distribution
Oct 31, 2018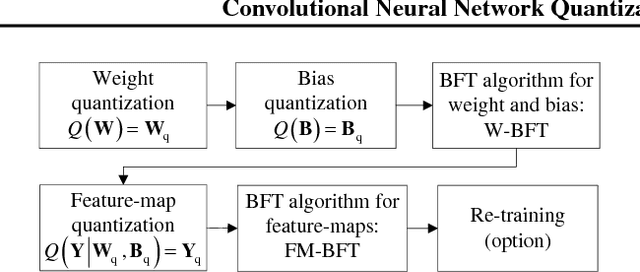
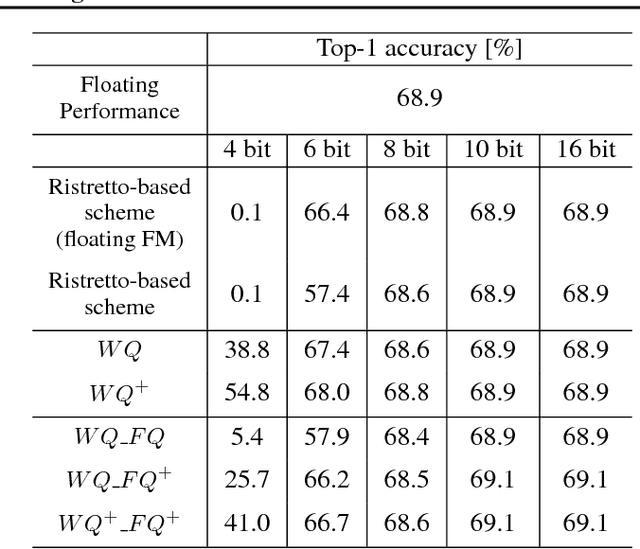
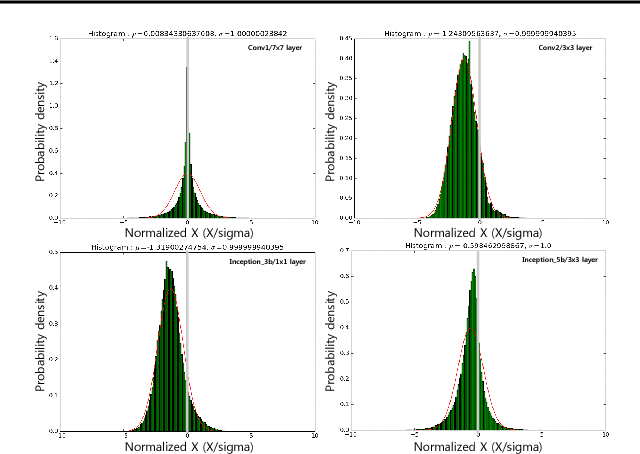
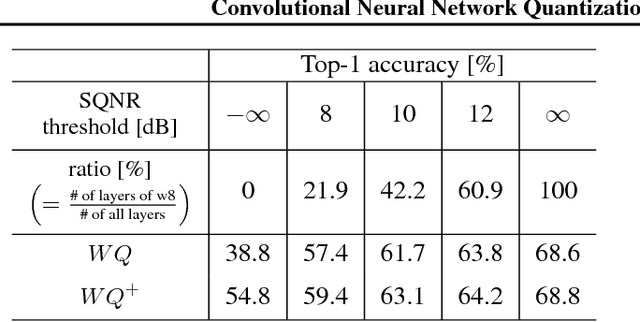
As edge applications using convolutional neural networks (CNN) models grow, it is becoming necessary to introduce dedicated hardware accelerators in which network parameters and feature-map data are represented with limited precision. In this paper we propose a novel quantization algorithm for energy-efficient deployment of the hardware accelerators. For weights and biases, the optimal bit length of the fractional part is determined so that the quantization error is minimized over their distribution. For feature-map data, meanwhile, their sample distribution is well approximated with the generalized gamma distribution (GGD), and accordingly the optimal quantization step size can be obtained through the asymptotical closed form solution of GGD. The proposed quantization algorithm has a higher signal-to-quantization-noise ratio (SQNR) than other quantization schemes previously proposed for CNNs, and even can be more improved by tuning the quantization parameters, resulting in efficient implementation of the hardware accelerators for CNNs in terms of power consumption and memory bandwidth.
Controlling the privacy loss with the input feature maps of the layers in convolutional neural networks
May 14, 2018
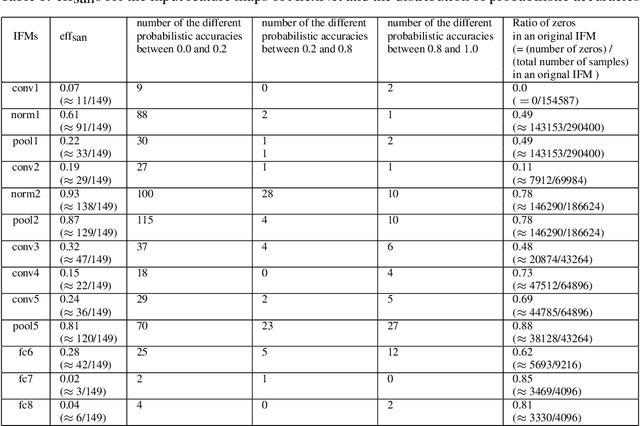
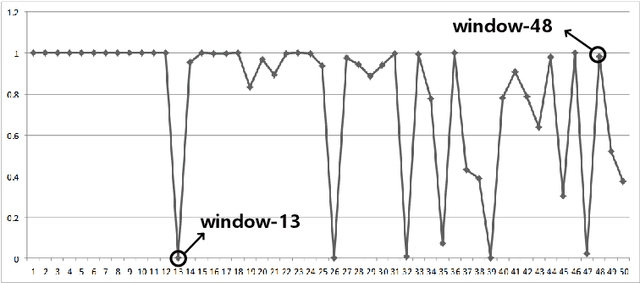
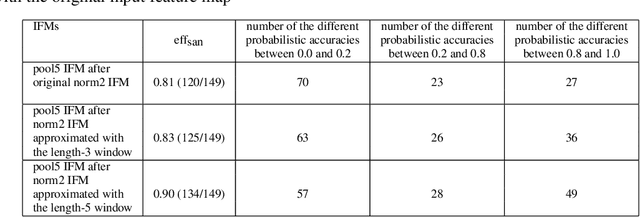
We propose the method to sanitize the privacy of the IFM(Input Feature Map)s that are fed into the layers of CNN(Convolutional Neural Network)s. The method introduces the degree of the sanitization that makes the application using a CNN be able to control the privacy loss represented as the ratio of the probabilistic accuracies for original IFM and sanitized IFM. For the sanitization of an IFM, the sample-and-hold based approximation scheme is devised to satisfy an application-specific degree of the sanitization. The scheme approximates an IFM by replacing all the samples in a window with the non-zero sample closest to the mean of the sampling window. It also removes the dependency on CNN configuration by unfolding multi-dimensional IFM tensors into one-dimensional streams to be approximated.