 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Speedy Q-learning
Nov 01, 2019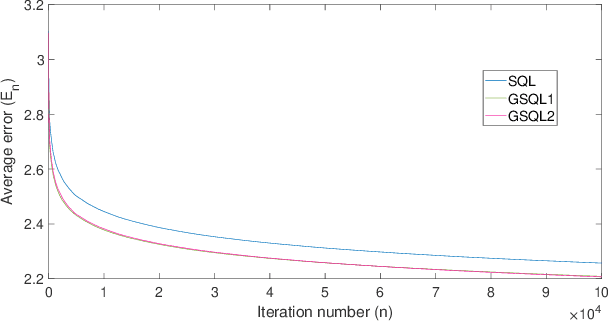
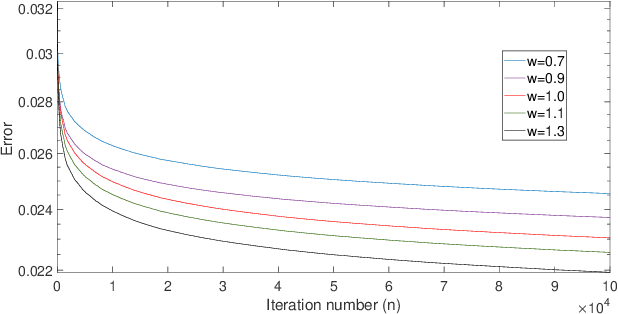
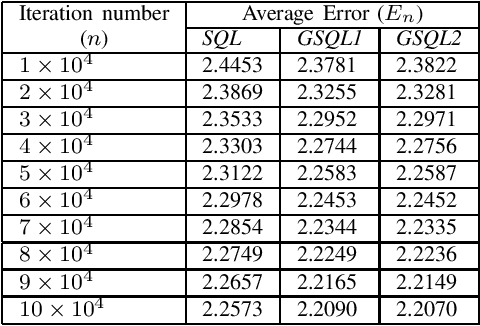
In this paper, we derive a generalization of the Speedy Q-learning (SQL) algorithm that was proposed in the Reinforcement Learning (RL) literature to handle slow convergence of Watkins' Q-learning. In most RL algorithms such as Q-learning, the Bellman equation and the Bellman operator play an important role. It is possible to generalize the Bellman operator using the technique of successive relaxation. We use the generalized Bellman operator to derive a simple and efficient family of algorithms called Generalized Speedy Q-learning (GSQL-w) and analyze its finite time performance. We show that GSQL-w has an improved finite time performance bound compared to SQL for the case when the relaxation parameter w is greater than 1. This improvement is a consequence of the contraction factor of the generalized Bellman operator being less than that of the standard Bellman operator. Numerical experiments are provided to demonstrate the empirical performance of the GSQL-w algorithm.