 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Highly Adaptive Acoustic Model for Accurate Multi-Dialect Speech Recognition
May 06, 2022
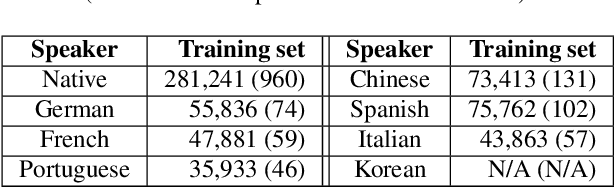
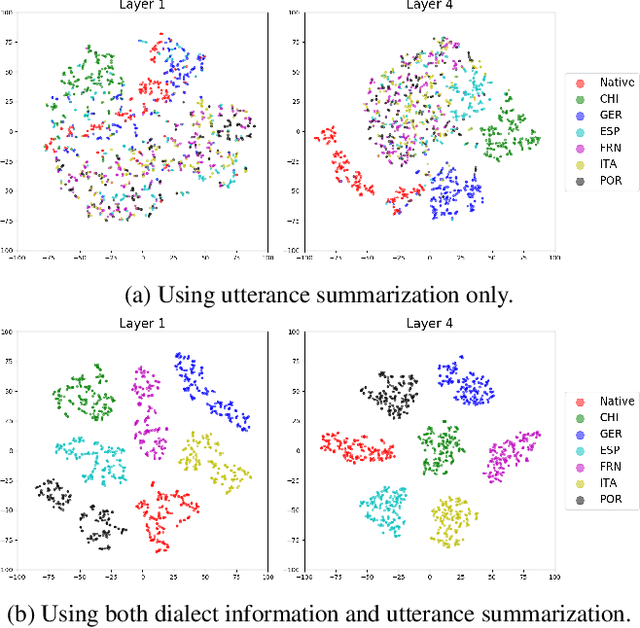
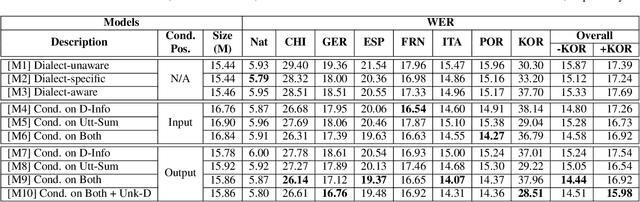
Despite the success of deep learning in speech recognition, multi-dialect speech recognition remains a difficult problem. Although dialect-specific acoustic models are known to perform well in general, they are not easy to maintain when dialect-specific data is scarce and the number of dialects for each language is large. Therefore, a single unified acoustic model (AM) that generalizes well for many dialects has been in demand. In this paper, we propose a novel acoustic modeling technique for accurate multi-dialect speech recognition with a single AM. Our proposed AM is dynamically adapted based on both dialect information and its internal representation, which results in a highly adaptive AM for handling multiple dialects simultaneously. We also propose a simple but effective training method to deal with unseen dialects. The experimental results on large scale speech datasets show that the proposed AM outperforms all the previous ones, reducing word error rates (WERs) by 8.11% relative compared to a single all-dialects AM and by 7.31% relative compared to dialect-specific AMs.
Dynamic Layer Normalization for Adaptive Neural Acoustic Modeling in Speech Recognition
Jul 19, 2017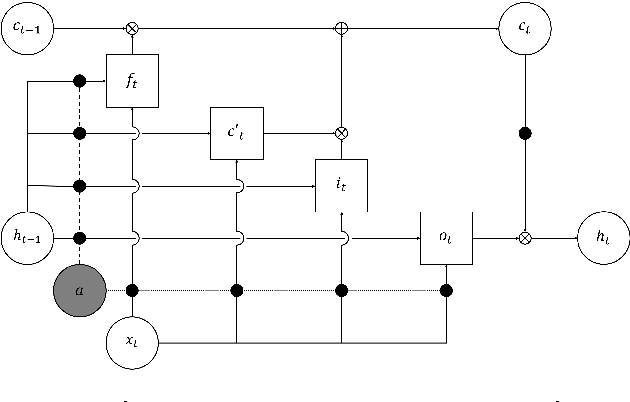
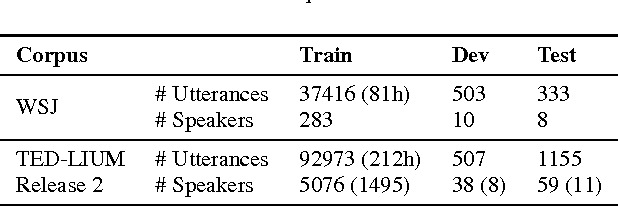
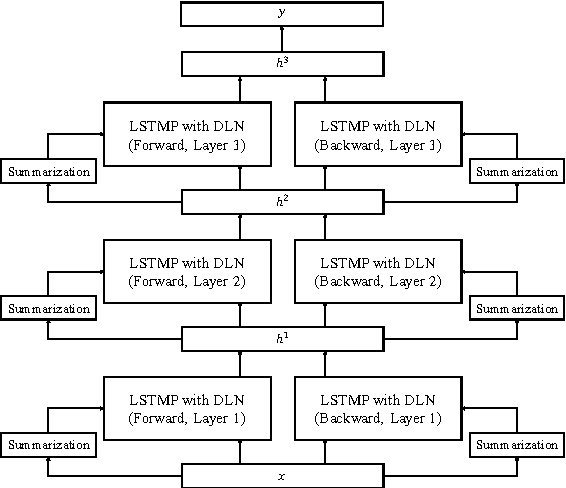
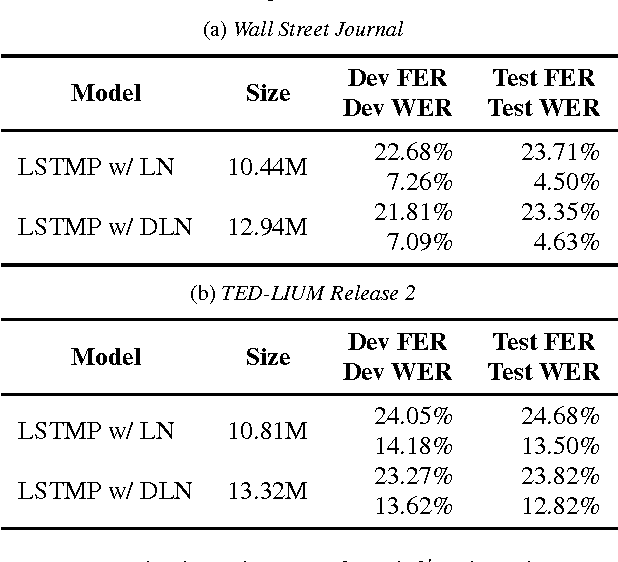
Layer normalization is a recently introduced technique for normalizing the activities of neurons in deep neural networks to improve the training speed and stability. In this paper, we introduce a new layer normalization technique called Dynamic Layer Normalization (DLN) for adaptive neural acoustic modeling in speech recognition. By dynamically generating the scaling and shifting parameters in layer normalization, DLN adapts neural acoustic models to the acoustic variability arising from various factors such as speakers, channel noises, and environments. Unlike other adaptive acoustic models, our proposed approach does not require additional adaptation data or speaker information such as i-vectors. Moreover, the model size is fixed as it dynamically generates adaptation parameters. We apply our proposed DLN to deep bidirectional LSTM acoustic models and evaluate them on two benchmark datasets for large vocabulary ASR experiments: WSJ and TED-LIUM release 2. The experimental results show that our DLN improves neural acoustic models in terms of transcription accuracy by dynamically adapting to various speakers and environments.