 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Federated Learning with Adaptive Differential Privacy and Priority-Based Aggregation
Jun 26, 2024Federated learning (FL), a novel branch of distributed machine learning (ML), develops global models through a private procedure without direct access to local datasets. However, it is still possible to access the model updates (gradient updates of deep neural networks) transferred between clients and servers, potentially revealing sensitive local information to adversaries using model inversion attacks. Differential privacy (DP) offers a promising approach to addressing this issue by adding noise to the parameters. On the other hand, heterogeneities in data structure, storage, communication, and computational capabilities of devices can cause convergence problems and delays in developing the global model. A personalized weighted averaging of local parameters based on the resources of each device can yield a better aggregated model in each round. In this paper, to efficiently preserve privacy, we propose a personalized DP framework that injects noise based on clients' relative impact factors and aggregates parameters while considering heterogeneities and adjusting properties. To fulfill the DP requirements, we first analyze the convergence boundary of the FL algorithm when impact factors are personalized and fixed throughout the learning process. We then further study the convergence property considering time-varying (adaptive) impact factors.
Adaptive Differential Privacy in Federated Learning: A Priority-Based Approach
Jan 04, 2024Federated learning (FL) as one of the novel branches of distributed machine learning (ML), develops global models through a private procedure without direct access to local datasets. However, access to model updates (e.g. gradient updates in deep neural networks) transferred between clients and servers can reveal sensitive information to adversaries. Differential privacy (DP) offers a framework that gives a privacy guarantee by adding certain amounts of noise to parameters. This approach, although being effective in terms of privacy, adversely affects model performance due to noise involvement. Hence, it is always needed to find a balance between noise injection and the sacrificed accuracy. To address this challenge, we propose adaptive noise addition in FL which decides the value of injected noise based on features' relative importance. Here, we first propose two effective methods for prioritizing features in deep neural network models and then perturb models' weights based on this information. Specifically, we try to figure out whether the idea of adding more noise to less important parameters and less noise to more important parameters can effectively save the model accuracy while preserving privacy. Our experiments confirm this statement under some conditions. The amount of noise injected, the proportion of parameters involved, and the number of global iterations can significantly change the output. While a careful choice of parameters by considering the properties of datasets can improve privacy without intense loss of accuracy, a bad choice can make the model performance worse.
CBAG: An Efficient Genetic Algorithm for the Graph Burning Problem
Aug 06, 2022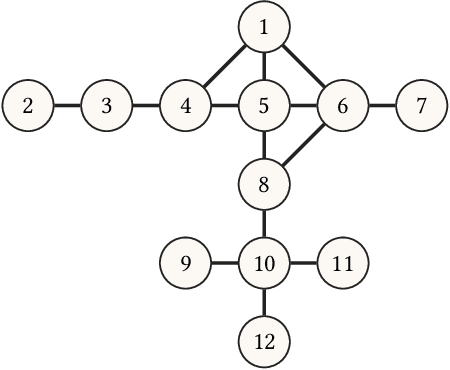
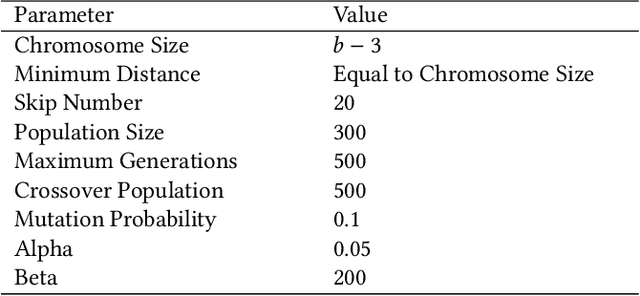
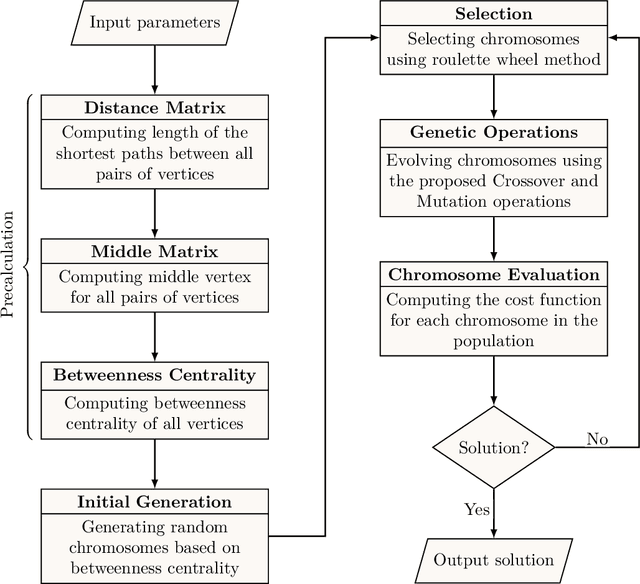

Information spread is an intriguing topic to study in network science, which investigates how information, influence, or contagion propagate through networks. Graph burning is a simplified deterministic model for how information spreads within networks. The complicated NP-complete nature of the problem makes it computationally difficult to solve using exact algorithms. Accordingly, a number of heuristics and approximation algorithms have been proposed in the literature for the graph burning problem. In this paper, we propose an efficient genetic algorithm called Centrality BAsed Genetic-algorithm (CBAG) for solving the graph burning problem. Considering the unique characteristics of the graph burning problem, we introduce novel genetic operators, chromosome representation, and evaluation method. In the proposed algorithm, the well-known betweenness centrality is used as the backbone of our chromosome initialization procedure. The proposed algorithm is implemented and compared with previous heuristics and approximation algorithms on 15 benchmark graphs of different sizes. Based on the results, it can be seen that the proposed algorithm achieves better performance in comparison to the previous state-of-the-art heuristics. The complete source code is available online and can be used to find optimal or near-optimal solutions for the graph burning problem.
Alarm-Based Root Cause Analysis in Industrial Processes Using Deep Learning
Mar 21, 2022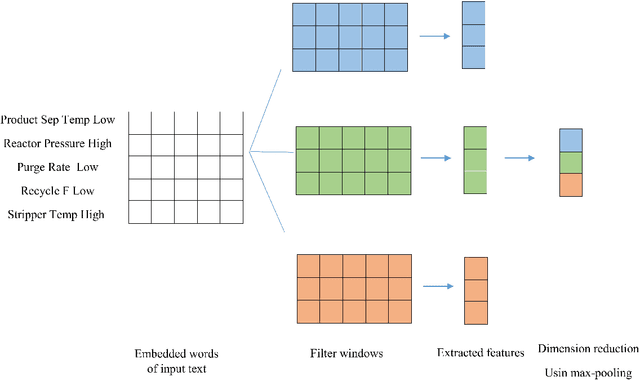
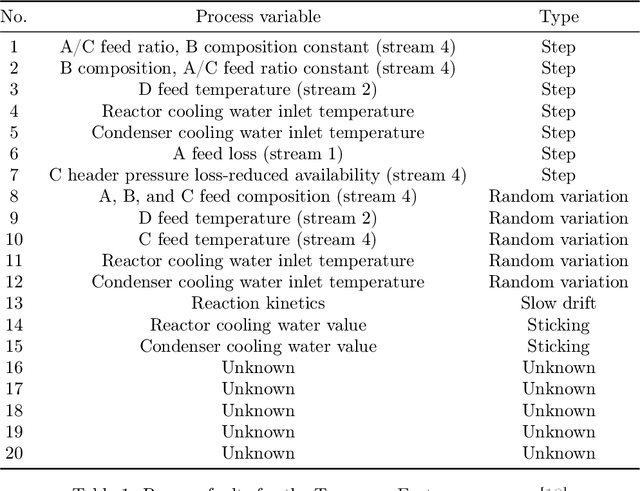
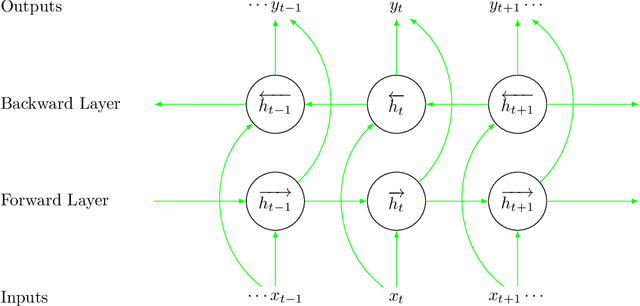

Alarm management systems have become indispensable in modern industry. Alarms inform the operator of abnormal situations, particularly in the case of equipment failures. Due to the interconnections between various parts of the system, each fault can affect other sections of the system operating normally. As a result, the fault propagates through faultless devices, increasing the number of alarms. Hence, the timely detection of the major fault that triggered the alarm by the operator can prevent the following consequences. However, due to the complexity of the system, it is often impossible to find precise relations between the underlying fault and the alarms. As a result, the operator needs support to make an appropriate decision immediately. Modeling alarms based on the historical alarm data can assist the operator in determining the root cause of the alarm. This research aims to model the relations between industrial alarms using historical alarm data in the database. Firstly, alarm data is collected, and alarm tags are sequenced. Then, these sequences are converted to numerical vectors using word embedding. Next, a self-attention-based BiLSTM-CNN classifier is used to learn the structure and relevance between historical alarm data. After training the model, this model is used for online fault detection. Finally, as a case study, the proposed model is implemented in the well-known Tennessee Eastman process, and the results are presented.
Detection of Correlated Alarms Using Graph Embedding
Jan 17, 2022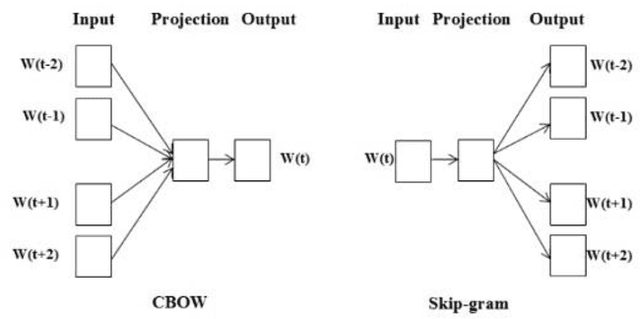
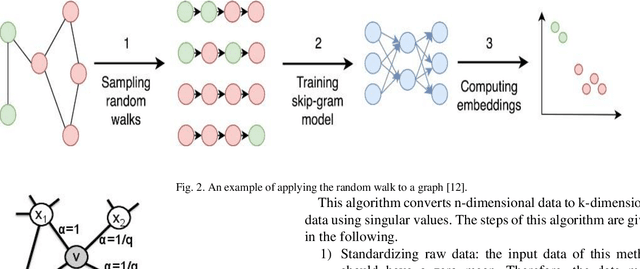
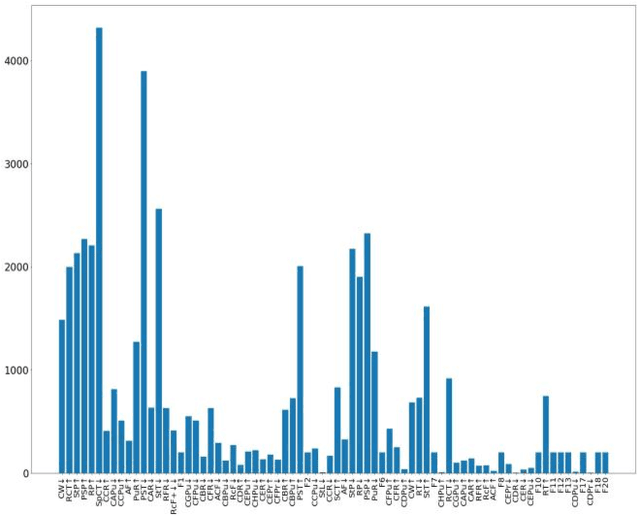
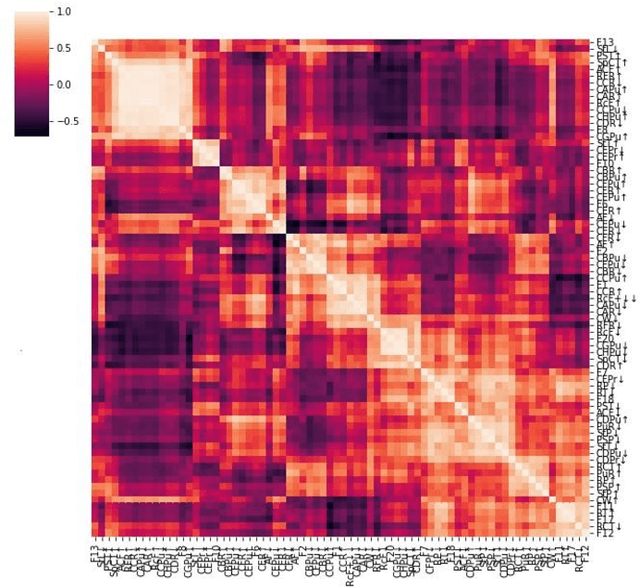
Industrial alarm systems have recently progressed considerably in terms of network complexity and the number of alarms. The increase in complexity and number of alarms presents challenges in these systems that decrease system efficiency and cause distrust of the operator, which might result in widespread damages. One contributing factor in alarm inefficiency is the correlated alarms. These alarms do not contain new information and only confuse the operator. This paper tries to present a novel method for detecting correlated alarms based on artificial intelligence methods to help the operator. The proposed method is based on graph embedding and alarm clustering, resulting in the detection of correlated alarms. To evaluate the proposed method, a case study is conducted on the well-known Tennessee-Eastman process.