 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity-Aware Hardware-Software Co-Design of Spiking Neural Networks: An Overview
Aug 26, 2024Spiking Neural Networks (SNNs) are inspired by the sparse and event-driven nature of biological neural processing, and offer the potential for ultra-low-power artificial intelligence. However, realizing their efficiency benefits requires specialized hardware and a co-design approach that effectively leverages sparsity. We explore the hardware-software co-design of sparse SNNs, examining how sparsity representation, hardware architectures, and training techniques influence hardware efficiency. We analyze the impact of static and dynamic sparsity, discuss the implications of different neuron models and encoding schemes, and investigate the need for adaptability in hardware designs. Our work aims to illuminate the path towards embedded neuromorphic systems that fully exploit the computational advantages of sparse SNNs.
GPU-RANC: A CUDA Accelerated Simulation Framework for Neuromorphic Architectures
Apr 24, 2024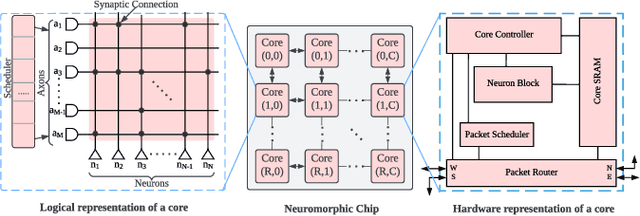
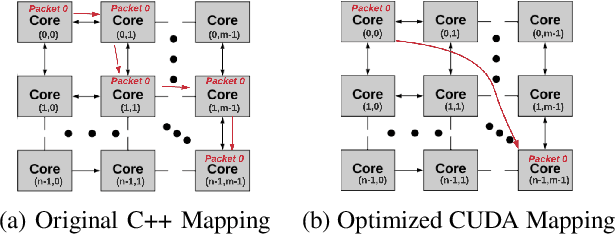
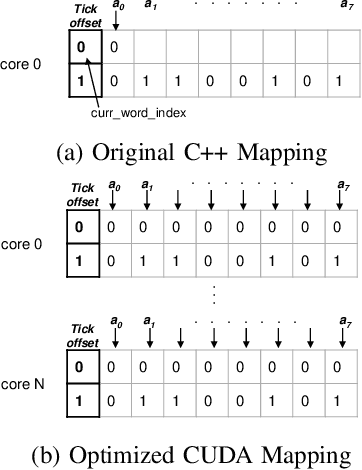
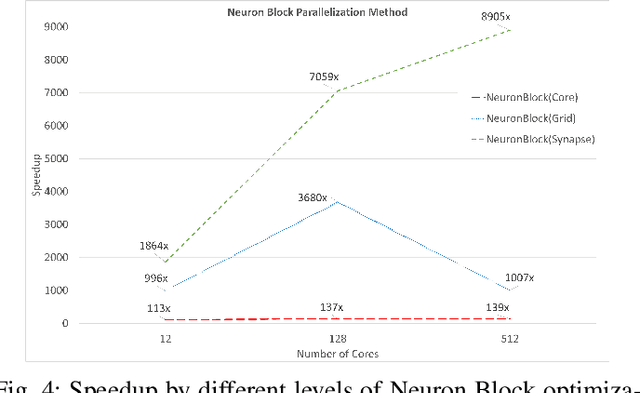
Open-source simulation tools play a crucial role for neuromorphic application engineers and hardware architects to investigate performance bottlenecks and explore design optimizations before committing to silicon. Reconfigurable Architecture for Neuromorphic Computing (RANC) is one such tool that offers ability to execute pre-trained Spiking Neural Network (SNN) models within a unified ecosystem through both software-based simulation and FPGA-based emulation. RANC has been utilized by the community with its flexible and highly parameterized design to study implementation bottlenecks, tune architectural parameters or modify neuron behavior based on application insights and study the trade space on hardware performance and network accuracy. In designing architectures for use in neuromorphic computing, there are an incredibly large number of configuration parameters such as number and precision of weights per neuron, neuron and axon counts per core, network topology, and neuron behavior. To accelerate such studies and provide users with a streamlined productive design space exploration, in this paper we introduce the GPU-based implementation of RANC. We summarize our parallelization approach and quantify the speedup gains achieved with GPU-based tick-accurate simulations across various use cases. We demonstrate up to 780 times speedup compared to serial version of the RANC simulator based on a 512 neuromorphic core MNIST inference application. We believe that the RANC ecosystem now provides a much more feasible avenue in the research of exploring different optimizations for accelerating SNNs and performing richer studies by enabling rapid convergence to optimized neuromorphic architectures.
Fine-Tuning Surrogate Gradient Learning for Optimal Hardware Performance in Spiking Neural Networks
Feb 09, 2024

The highly sparse activations in Spiking Neural Networks (SNNs) can provide tremendous energy efficiency benefits when carefully exploited in hardware. The behavior of sparsity in SNNs is uniquely shaped by the dataset and training hyperparameters. This work reveals novel insights into the impacts of training on hardware performance. Specifically, we explore the trade-offs between model accuracy and hardware efficiency. We focus on three key hyperparameters: surrogate gradient functions, beta, and membrane threshold. Results on an FPGA-based hardware platform show that the fast sigmoid surrogate function yields a lower firing rate with similar accuracy compared to the arctangent surrogate on the SVHN dataset. Furthermore, by cross-sweeping the beta and membrane threshold hyperparameters, we can achieve a 48% reduction in hardware-based inference latency with only 2.88% trade-off in inference accuracy compared to the default setting. Overall, this study highlights the importance of fine-tuning model hyperparameters as crucial for designing efficient SNN hardware accelerators, evidenced by the fine-tuned model achieving a 1.72x improvement in accelerator efficiency (FPS/W) compared to the most recent work.