 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU-RANC: A CUDA Accelerated Simulation Framework for Neuromorphic Architectures
Apr 24, 2024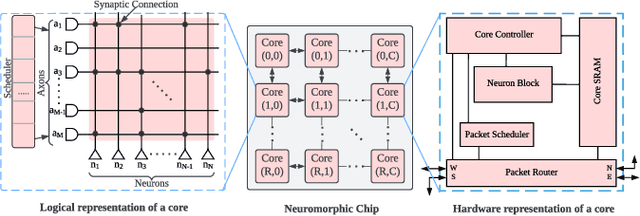
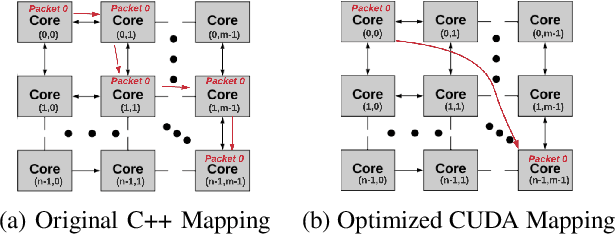
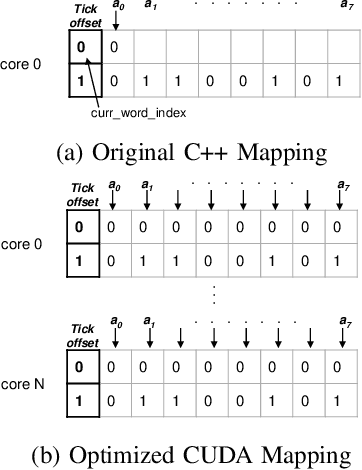
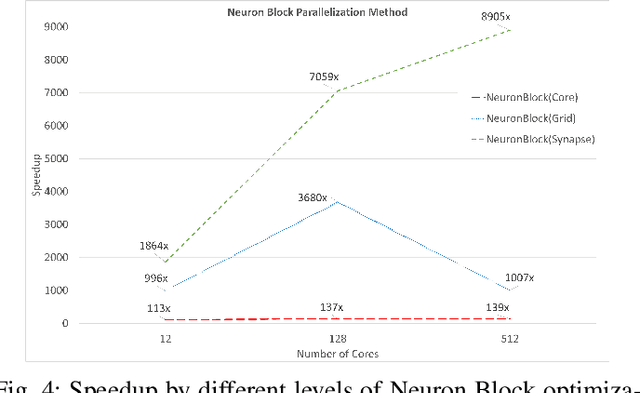
Open-source simulation tools play a crucial role for neuromorphic application engineers and hardware architects to investigate performance bottlenecks and explore design optimizations before committing to silicon. Reconfigurable Architecture for Neuromorphic Computing (RANC) is one such tool that offers ability to execute pre-trained Spiking Neural Network (SNN) models within a unified ecosystem through both software-based simulation and FPGA-based emulation. RANC has been utilized by the community with its flexible and highly parameterized design to study implementation bottlenecks, tune architectural parameters or modify neuron behavior based on application insights and study the trade space on hardware performance and network accuracy. In designing architectures for use in neuromorphic computing, there are an incredibly large number of configuration parameters such as number and precision of weights per neuron, neuron and axon counts per core, network topology, and neuron behavior. To accelerate such studies and provide users with a streamlined productive design space exploration, in this paper we introduce the GPU-based implementation of RANC. We summarize our parallelization approach and quantify the speedup gains achieved with GPU-based tick-accurate simulations across various use cases. We demonstrate up to 780 times speedup compared to serial version of the RANC simulator based on a 512 neuromorphic core MNIST inference application. We believe that the RANC ecosystem now provides a much more feasible avenue in the research of exploring different optimizations for accelerating SNNs and performing richer studies by enabling rapid convergence to optimized neuromorphic architectures.
A Novel Implementation Methodology for Error Correction Codes on a Neuromorphic Architecture
Jun 06, 2023The Internet of Things infrastructure connects a massive number of edge devices with an increasing demand for intelligent sensing and inferencing capability. Such data-sensitive functions necessitate energy-efficient and programmable implementations of Error Correction Codes (ECC) and decoders. The algorithmic flow of ECCs with concurrent accumulation and comparison types of operations are innately exploitable by neuromorphic architectures for energy efficient execution -- an area that is relatively unexplored outside of machine learning applications. For the first time, we propose a methodology to map the hard-decision class of decoder algorithms on a neuromorphic architecture. We present the implementation of the Gallager B (GaB) decoding algorithm on a TrueNorth-inspired architecture that is emulated on the Xilinx Zynq ZCU102 MPSoC. Over this reference implementation, we propose architectural modifications at the neuron block level that result in a reduction of energy consumption by 31% with a negligible increase in resource usage while achieving the same error correction performance.