 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvacheck at GenAI Detection Task 1: AI Detection Powered by Domain-Aware Multi-Tasking
Nov 18, 2024
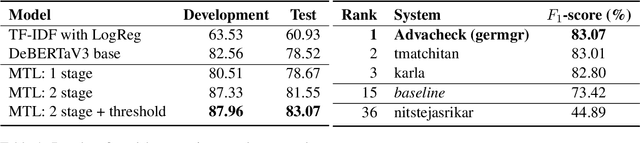
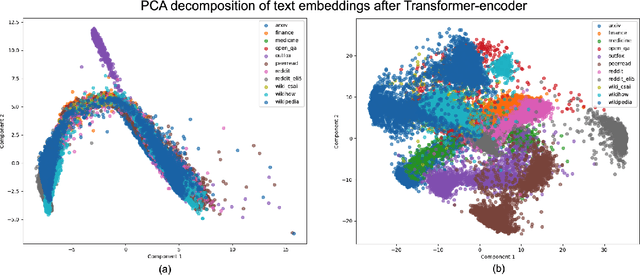
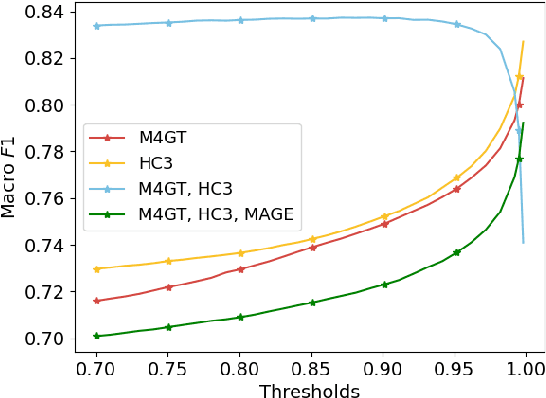
The paper describes a system designed by Advacheck team to recognise machine-generated and human-written texts in the monolingual subtask of GenAI Detection Task 1 competition. Our developed system is a multi-task architecture with shared Transformer Encoder between several classification heads. One head is responsible for binary classification between human-written and machine-generated texts, while the other heads are auxiliary multiclass classifiers for texts of different domains from particular datasets. As multiclass heads were trained to distinguish the domains presented in the data, they provide a better understanding of the samples. This approach led us to achieve the first place in the official ranking with 83.07% macro F1-score on the test set and bypass the baseline by 10%. We further study obtained system through ablation, error and representation analyses, finding that multi-task learning outperforms single-task mode and simultaneous tasks form a cluster structure in embeddings space.
Multi-head Span-based Detector for AI-generated Fragments in Scientific Papers
Nov 11, 2024
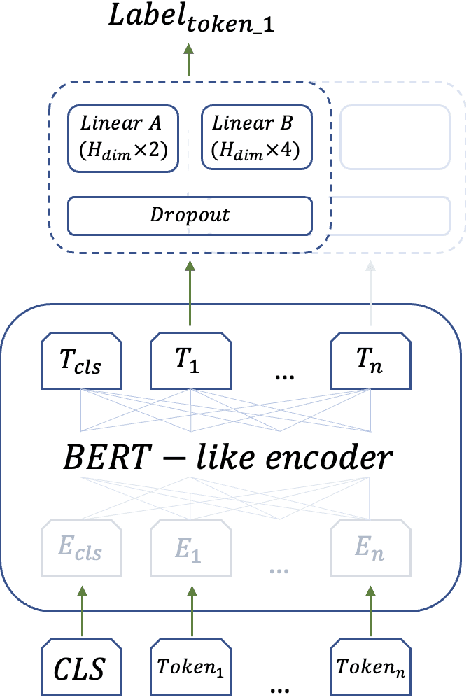


This paper describes a system designed to distinguish between AI-generated and human-written scientific excerpts in the DAGPap24 competition hosted within the Fourth Workshop on Scientific Document Processing. In this competition the task is to find artificially generated token-level text fragments in documents of a scientific domain. Our work focuses on the use of a multi-task learning architecture with two heads. The application of this approach is justified by the specificity of the task, where class spans are continuous over several hundred characters. We considered different encoder variations to obtain a state vector for each token in the sequence, as well as a variation in splitting fragments into tokens to further feed into the input of a transform-based encoder. This approach allows us to achieve a 9% quality improvement relative to the baseline solution score on the development set (from 0.86 to 0.95) using the average macro F1-score, as well as a score of 0.96 on a closed test part of the dataset from the competition.