 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvacheck at GenAI Detection Task 1: AI Detection Powered by Domain-Aware Multi-Tasking
Nov 18, 2024
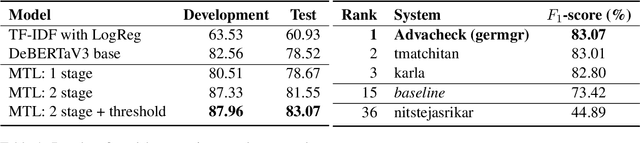
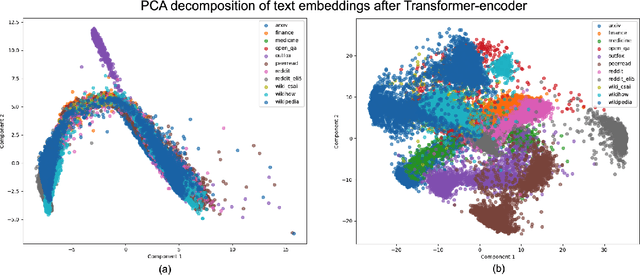
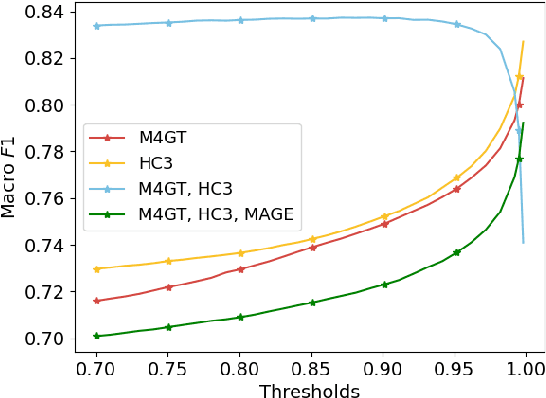
The paper describes a system designed by Advacheck team to recognise machine-generated and human-written texts in the monolingual subtask of GenAI Detection Task 1 competition. Our developed system is a multi-task architecture with shared Transformer Encoder between several classification heads. One head is responsible for binary classification between human-written and machine-generated texts, while the other heads are auxiliary multiclass classifiers for texts of different domains from particular datasets. As multiclass heads were trained to distinguish the domains presented in the data, they provide a better understanding of the samples. This approach led us to achieve the first place in the official ranking with 83.07% macro F1-score on the test set and bypass the baseline by 10%. We further study obtained system through ablation, error and representation analyses, finding that multi-task learning outperforms single-task mode and simultaneous tasks form a cluster structure in embeddings space.
Multi-head Span-based Detector for AI-generated Fragments in Scientific Papers
Nov 11, 2024
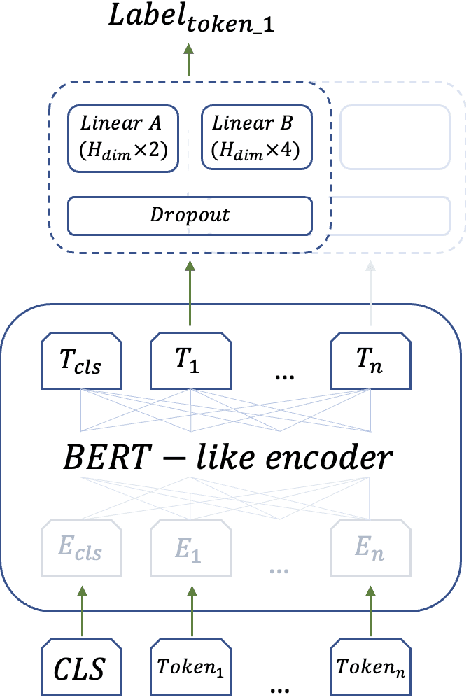


This paper describes a system designed to distinguish between AI-generated and human-written scientific excerpts in the DAGPap24 competition hosted within the Fourth Workshop on Scientific Document Processing. In this competition the task is to find artificially generated token-level text fragments in documents of a scientific domain. Our work focuses on the use of a multi-task learning architecture with two heads. The application of this approach is justified by the specificity of the task, where class spans are continuous over several hundred characters. We considered different encoder variations to obtain a state vector for each token in the sequence, as well as a variation in splitting fragments into tokens to further feed into the input of a transform-based encoder. This approach allows us to achieve a 9% quality improvement relative to the baseline solution score on the development set (from 0.86 to 0.95) using the average macro F1-score, as well as a score of 0.96 on a closed test part of the dataset from the competition.
Are AI Detectors Good Enough? A Survey on Quality of Datasets With Machine-Generated Texts
Oct 18, 2024
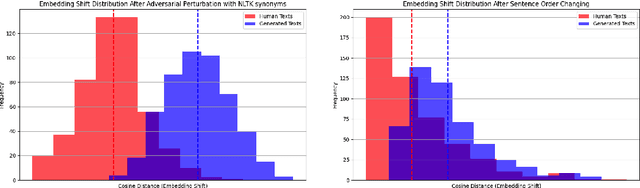
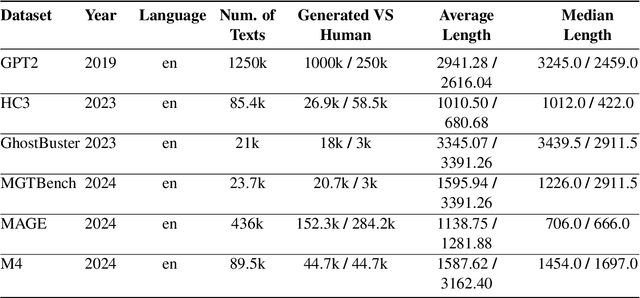
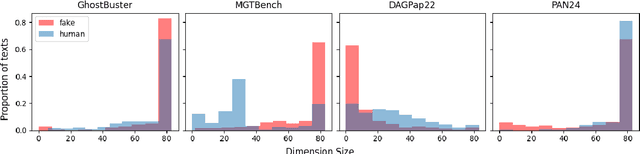
The rapid development of autoregressive Large Language Models (LLMs) has significantly improved the quality of generated texts, necessitating reliable machine-generated text detectors. A huge number of detectors and collections with AI fragments have emerged, and several detection methods even showed recognition quality up to 99.9% according to the target metrics in such collections. However, the quality of such detectors tends to drop dramatically in the wild, posing a question: Are detectors actually highly trustworthy or do their high benchmark scores come from the poor quality of evaluation datasets? In this paper, we emphasise the need for robust and qualitative methods for evaluating generated data to be secure against bias and low generalising ability of future model. We present a systematic review of datasets from competitions dedicated to AI-generated content detection and propose methods for evaluating the quality of datasets containing AI-generated fragments. In addition, we discuss the possibility of using high-quality generated data to achieve two goals: improving the training of detection models and improving the training datasets themselves. Our contribution aims to facilitate a better understanding of the dynamics between human and machine text, which will ultimately support the integrity of information in an increasingly automated world.
Neural machine translation system for Lezgian, Russian and Azerbaijani languages
Oct 07, 2024We release the first neural machine translation system for translation between Russian, Azerbaijani and the endangered Lezgian languages, as well as monolingual and parallel datasets collected and aligned for training and evaluating the system. Multiple experiments are conducted to identify how different sets of training language pairs and data domains can influence the resulting translation quality. We achieve BLEU scores of 26.14 for Lezgian-Azerbaijani, 22.89 for Azerbaijani-Lezgian, 29.48 for Lezgian-Russian and 24.25 for Russian-Lezgian pairs. The quality of zero-shot translation is assessed on a Large Language Model, showing its high level of fluency in Lezgian. However, the model often refuses to translate, justifying itself with its incompetence. We contribute our translation model along with the collected parallel and monolingual corpora and sentence encoder for the Lezgian language.
Unraveling the Hessian: A Key to Smooth Convergence in Loss Function Landscapes
Sep 18, 2024The loss landscape of neural networks is a critical aspect of their training, and understanding its properties is essential for improving their performance. In this paper, we investigate how the loss surface changes when the sample size increases, a previously unexplored issue. We theoretically analyze the convergence of the loss landscape in a fully connected neural network and derive upper bounds for the difference in loss function values when adding a new object to the sample. Our empirical study confirms these results on various datasets, demonstrating the convergence of the loss function surface for image classification tasks. Our findings provide insights into the local geometry of neural loss landscapes and have implications for the development of sample size determination techniques.