 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue You Can Trust: Human and AI Perspectives on Generated Conversations
Sep 03, 2024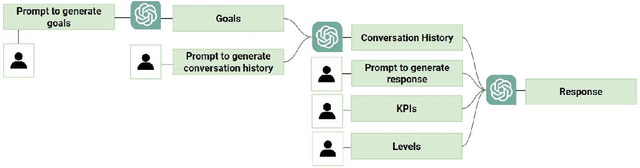
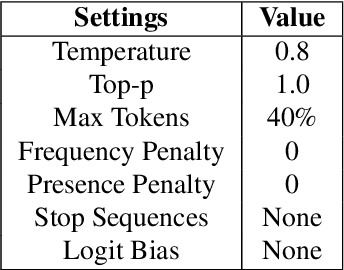

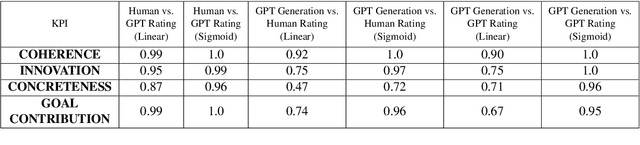
As dialogue systems and chatbots increasingly integrate into everyday interactions, the need for efficient and accurate evaluation methods becomes paramount. This study explores the comparative performance of human and AI assessments across a range of dialogue scenarios, focusing on seven key performance indicators (KPIs): Coherence, Innovation, Concreteness, Goal Contribution, Commonsense Contradiction, Incorrect Fact, and Redundancy. Utilizing the GPT-4o API, we generated a diverse dataset of conversations and conducted a two-part experimental analysis. In Experiment 1, we evaluated multi-party conversations on Coherence, Innovation, Concreteness, and Goal Contribution, revealing that GPT models align closely with human judgments. Notably, both human and AI evaluators exhibited a tendency towards binary judgment rather than linear scaling, highlighting a shared challenge in these assessments. Experiment 2 extended the work of Finch et al. (2023) by focusing on dyadic dialogues and assessing Commonsense Contradiction, Incorrect Fact, and Redundancy. The results indicate that while GPT-4o demonstrates strong performance in maintaining factual accuracy and commonsense reasoning, it still struggles with reducing redundancy and self-contradiction. Our findings underscore the potential of GPT models to closely replicate human evaluation in dialogue systems, while also pointing to areas for improvement. This research offers valuable insights for advancing the development and implementation of more refined dialogue evaluation methodologies, contributing to the evolution of more effective and human-like AI communication tools.