 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Engineering for Applied Monocular Reconstruction of Parametric Faces
Sep 06, 2022Many modern online 3D applications and video games rely on parametric models of human faces for creating believable avatars. However, manually reproducing someone's facial likeness with a parametric model is difficult and time-consuming. Machine Learning solution for that task is highly desirable but is also challenging. The paper proposes a novel approach to the so-called Face-to-Parameters problem (F2P for short), aiming to reconstruct a parametric face from a single image. The proposed method utilizes synthetic data, domain decomposition, and domain adaptation to address multifaceted challenges in solving the F2P. The open-sourced codebase illustrates our key observations and provides means for quantitative evaluation. The presented approach proves practical in an industrial application; it improves accuracy and allows for more efficient models training. The techniques have the potential to extend to other types of parametric models.
* An extended SIPP 2022 conference paper. arXiv admin note: substantial text overlap with arXiv:2208.02935
Applied monocular reconstruction of parametric faces with domain engineering
Aug 05, 2022Many modern online 3D applications and videogames rely on parametric models of human faces for creating believable avatars. However, manual reproduction of someone's facial likeness with a parametric model is difficult and time-consuming. Machine Learning solution for that task is highly desirable but is also challenging. The paper proposes a novel approach to the so-called Face-to-Parameters problem (F2P for short), aiming to reconstruct a parametric face from a single image. The proposed method utilizes synthetic data, domain decomposition, and domain adaptation for addressing multifaceted challenges in solving the F2P. The open-sourced codebase illustrates our key observations and provides means for quantitative evaluation. The presented approach proves practical in an industrial application; it improves accuracy and allows for more efficient models training. The techniques have the potential to extend to other types of parametric models.
Hierarchical Cooperative Multi-Agent Reinforcement Learning with Skill Discovery
Dec 07, 2019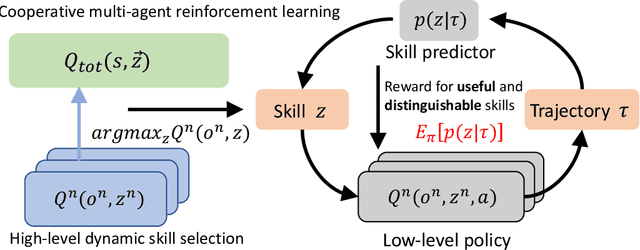
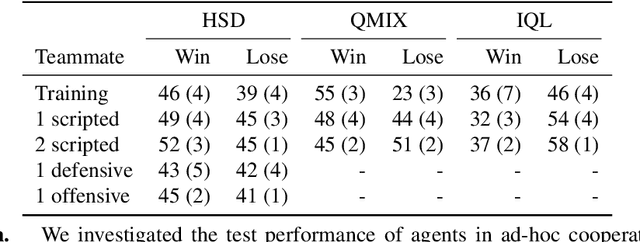
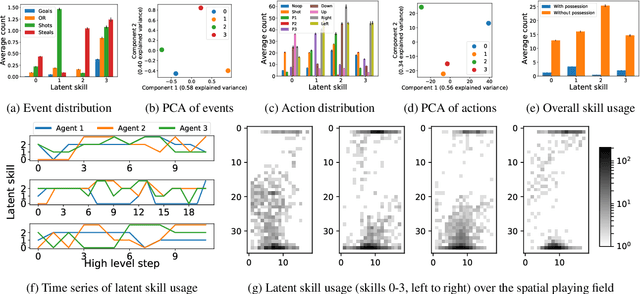
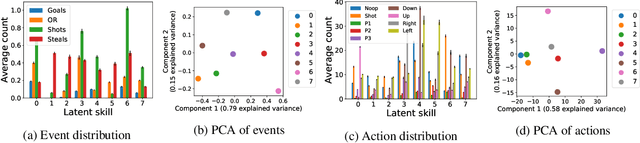
Human players in professional team sports achieve high level coordination by dynamically choosing complementary skills and executing primitive actions to perform these skills. As a step toward creating intelligent agents with this capability for fully cooperative multi-agent settings, we propose a two-level hierarchical multi-agent reinforcement learning (MARL) algorithm with unsupervised skill discovery. Agents learn useful and distinct skills at the low level via independent Q-learning, while they learn to select complementary latent skill variables at the high level via centralized multi-agent training with an extrinsic team reward. The set of low-level skills emerges from an intrinsic reward that solely promotes the decodability of latent skill variables from the trajectory of a low-level skill, without the need for hand-crafted rewards for each skill. For scalable decentralized execution, each agent independently chooses latent skill variables and primitive actions based on local observations. Our overall method enables the use of general cooperative MARL algorithms for training high level policies and single-agent RL for training low level skills. Experiments on a stochastic high dimensional team game show the emergence of useful skills and cooperative team play. The interpretability of the learned skills show the promise of the proposed method for achieving human-AI cooperation in team sports games.
On Multi-Agent Learning in Team Sports Games
Jun 25, 2019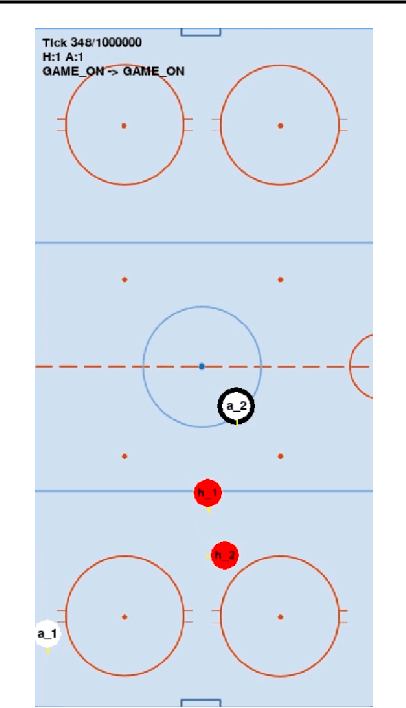
In recent years, reinforcement learning has been successful in solving video games from Atari to Star Craft II. However, the end-to-end model-free reinforcement learning (RL) is not sample efficient and requires a significant amount of computational resources to achieve superhuman level performance. Model-free RL is also unlikely to produce human-like agents for playtesting and gameplaying AI in the development cycle of complex video games. In this paper, we present a hierarchical approach to training agents with the goal of achieving human-like style and high skill level in team sports games. While this is still work in progress, our preliminary results show that the presented approach holds promise for solving the posed multi-agent learning problem.
Towards Interactive Training of Non-Player Characters in Video Games
Jun 03, 2019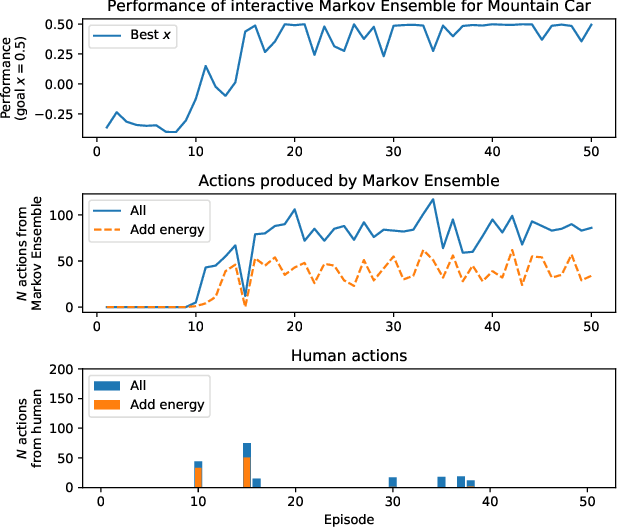
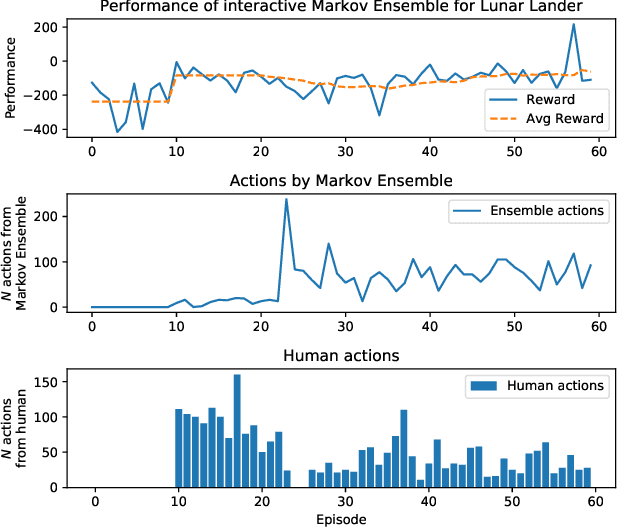
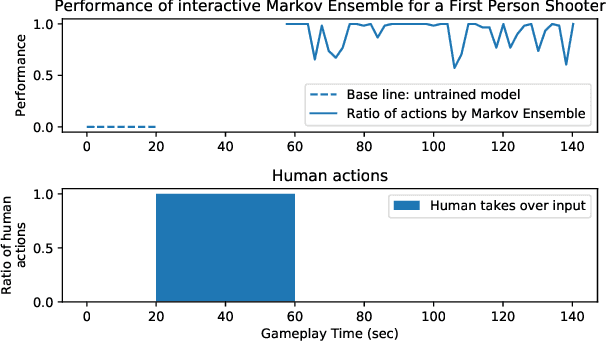
There is a high demand for high-quality Non-Player Characters (NPCs) in video games. Hand-crafting their behavior is a labor intensive and error prone engineering process with limited controls exposed to the game designers. We propose to create such NPC behaviors interactively by training an agent in the target environment using imitation learning with a human in the loop. While traditional behavior cloning may fall short of achieving the desired performance, we show that interactivity can substantially improve it with a modest amount of human efforts. The model we train is a multi-resolution ensemble of Markov models, which can be used as is or can be further "compressed" into a more compact model for inference on consumer devices. We illustrate our approach on an example in OpenAI Gym, where a human can help to quickly train an agent with only a handful of interactive demonstrations. We also outline our experiments with NPC training for a first-person shooter game currently in development.
Winning Isn't Everything: Training Human-Like Agents for Playtesting and Game AI
Mar 25, 2019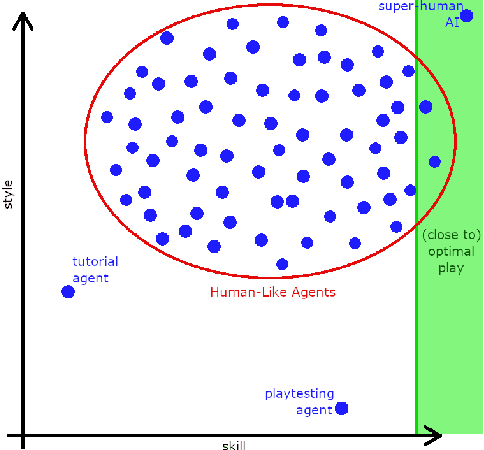
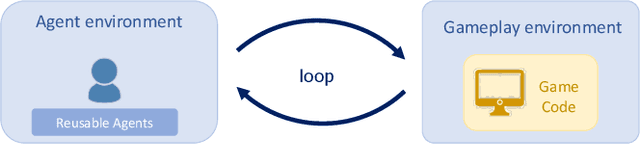
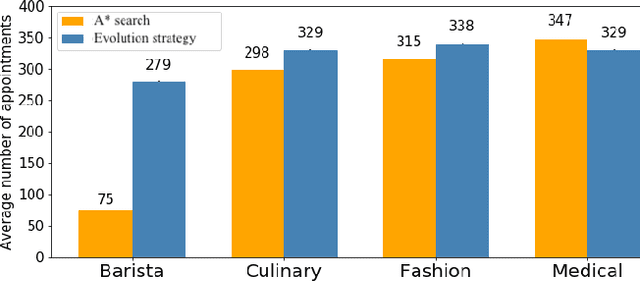
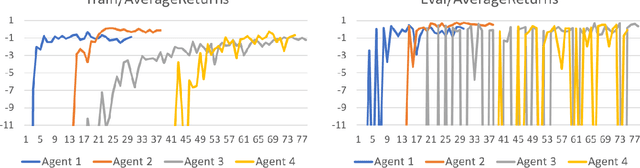
Recently, there have been several high-profile achievements of agents learning to play games against humans and beat them. We consider an alternative approach that instead addresses game design for a better player experience by training human-like game agents. Specifically, we study the problem of training game agents in service of the development processes of the game developers that design, build, and operate modern games. We highlight some of the ways in which we think intelligent agents can assist game developers to understand their games, and even to build them. Our early results using the proposed agent framework mark a few steps toward addressing the unique challenges that game developers face.
Exploring Gameplay With AI Agents
Nov 16, 2018



The process of playtesting a game is subjective, expensive and incomplete. In this paper, we present a playtesting approach that explores the game space with automated agents and collects data to answer questions posed by the designers. Rather than have agents interacting with an actual game client, this approach recreates the bare bone mechanics of the game as a separate system. Our agent is able to play in minutes what would take testers days of organic gameplay. The analysis of thousands of game simulations exposed imbalances in game actions, identified inconsequential rewards and evaluated the effectiveness of optional strategic choices. Our test case game, The Sims Mobile, was recently released and the findings shown here influenced design changes that resulted in improved player experience.