 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensionality reduction methods for molecular simulations
Nov 02, 2017
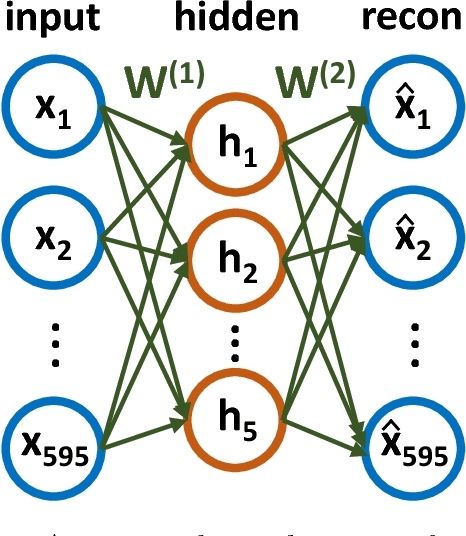
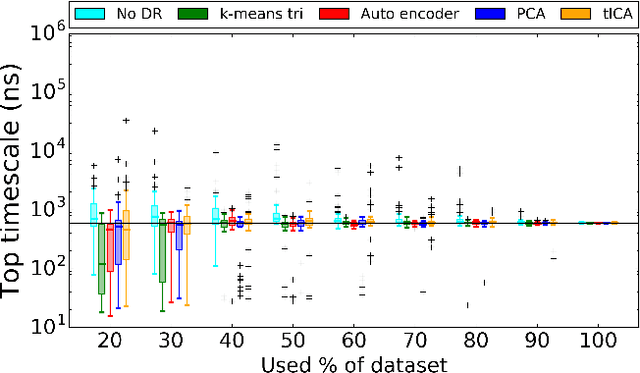
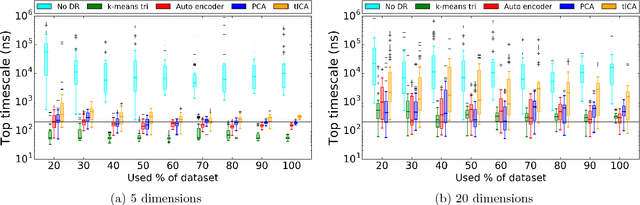
Molecular simulations produce very high-dimensional data-sets with millions of data points. As analysis methods are often unable to cope with so many dimensions, it is common to use dimensionality reduction and clustering methods to reach a reduced representation of the data. Yet these methods often fail to capture the most important features necessary for the construction of a Markov model. Here we demonstrate the results of various dimensionality reduction methods on two simulation data-sets, one of protein folding and another of protein-ligand binding. The methods tested include a k-means clustering variant, a non-linear auto encoder, principal component analysis and tICA. The dimension-reduced data is then used to estimate the implied timescales of the slowest process by a Markov state model analysis to assess the quality of the projection. The projected dimensions learned from the data are visualized to demonstrate which conformations the various methods choose to represent the molecular process.