 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Complete System for Automated 3D Semantic-Geometric Mapping of Corrosion in Industrial Environments
Apr 21, 2024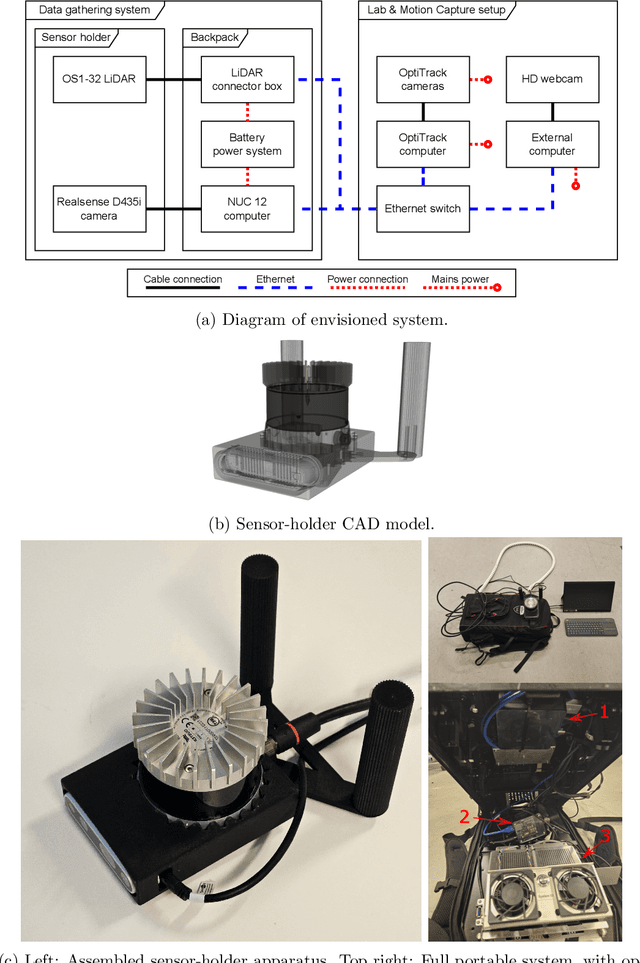

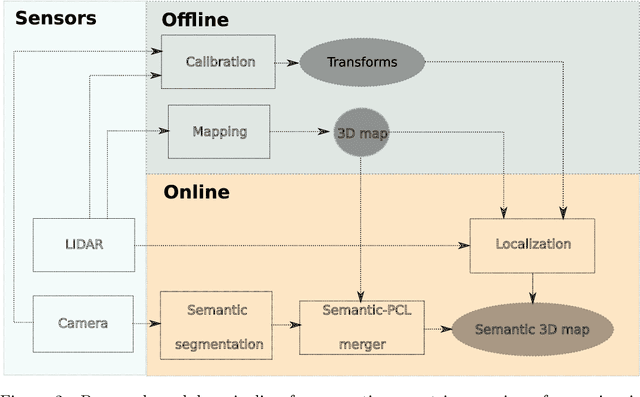
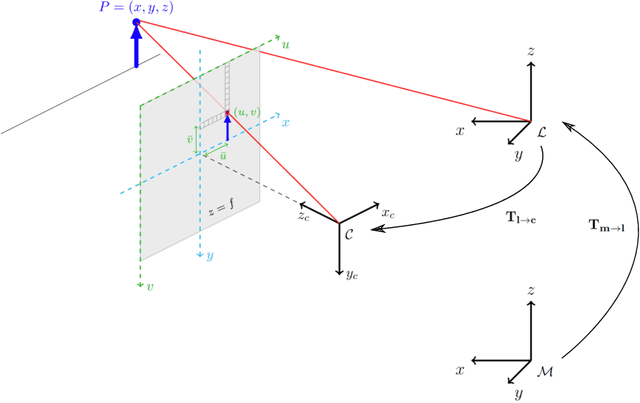
Corrosion, a naturally occurring process leading to the deterioration of metallic materials, demands diligent detection for quality control and the preservation of metal-based objects, especially within industrial contexts. Traditional techniques for corrosion identification, including ultrasonic testing, radio-graphic testing, and magnetic flux leakage, necessitate the deployment of expensive and bulky equipment on-site for effective data acquisition. An unexplored alternative involves employing lightweight, conventional camera systems, and state-of-the-art computer vision methods for its identification. In this work, we propose a complete system for semi-automated corrosion identification and mapping in industrial environments. We leverage recent advances in LiDAR-based methods for localization and mapping, with vision-based semantic segmentation deep learning techniques, in order to build semantic-geometric maps of industrial environments. Unlike previous corrosion identification systems available in the literature, our designed multi-modal system is low-cost, portable, semi-autonomous and allows collecting large datasets by untrained personnel. A set of experiments in an indoor laboratory environment, demonstrate quantitatively the high accuracy of the employed LiDAR based 3D mapping and localization system, with less then $0.05m$ and 0.02m average absolute and relative pose errors. Also, our data-driven semantic segmentation model, achieves around 70\% precision when trained with our pixel-wise manually annotated dataset.
Forecasting blood sugar levels in Diabetes with univariate algorithms
Jan 21, 2021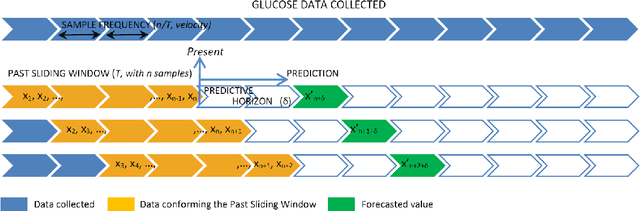
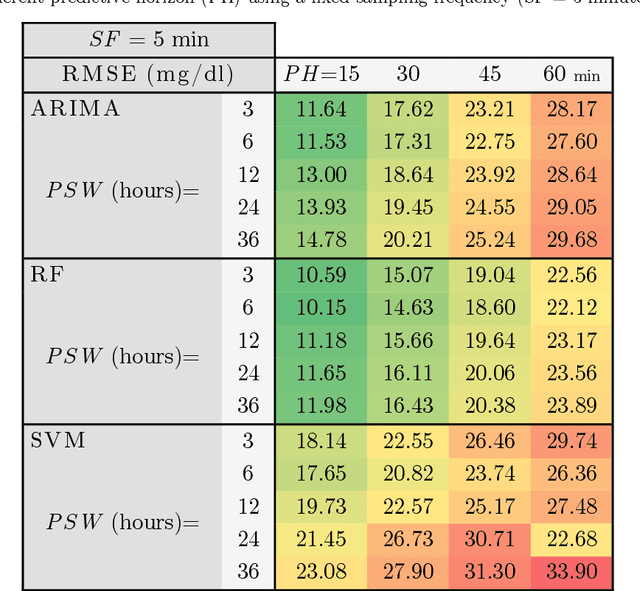

AI procedures joined with wearable gadgets can convey exact transient blood glucose level forecast models. Also, such models can learn customized glucose-insulin elements dependent on the sensor information gathered by observing a few parts of the physiological condition and every day movement of a person. Up to this point, the predominant methodology for creating information driven forecast models was to gather "however much information as could be expected" to help doctors and patients ideally change treatment. The goal of this work was to examine the base information assortment, volume, and speed needed to accomplish exact individual driven diminutive term expectation models. We built up a progression of these models utilizing distinctive AI time arrangement guaging strategies that are appropriate for execution inside a wearable processor. We completed a broad aloof patient checking concentrate in genuine conditions to fabricate a strong informational collection. The examination included a subset of type-1 diabetic subjects wearing a glimmer glucose checking framework. We directed a relative quantitative assessment of the presentation of the created information driven expectation models and comparing AI methods. Our outcomes show that precise momentary forecast can be accomplished by just checking interstitial glucose information over a brief timeframe and utilizing a low examining recurrence. The models created can anticipate glucose levels inside a 15-minute skyline with a normal mistake as low as 15.43 mg/dL utilizing just 24 memorable qualities gathered inside a time of 6 hours, and by expanding the inspecting recurrence to incorporate 72 qualities, the normal blunder is limited to 10.15 mg/dL. Our forecast models are reasonable for execution inside a wearable gadget, requiring the base equipment necessities while simultaneously accomplishing high expectation precision.
On the Management of Type 1 Diabetes Mellitus with IoT Devices and ML Techniques
Jan 07, 2021
The purpose of this Conference is to present the main lines of base projects that are founded on research already begun in previous years. In this sense, this manuscript will present the main lines of research in Diabetes Mellitus type 1 and Machine Learning techniques in an Internet of Things environment, so that we can summarize the future lines to be developed as follows: data collection through biosensors, massive data processing in the cloud, interconnection of biodevices, local computing vs. cloud computing, and possibilities of machine learning techniques to predict blood glucose values, including both variable selection algorithms and predictive techniques.