 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Coupled Deep Q-Networks
Oct 28, 2023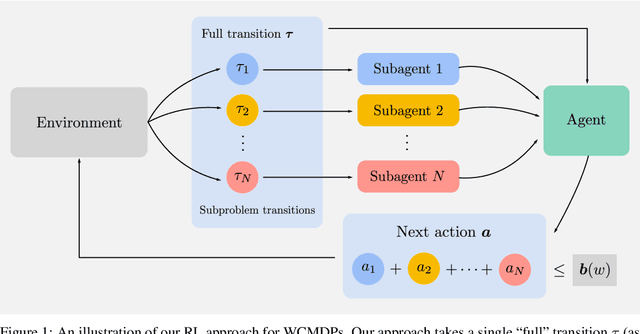

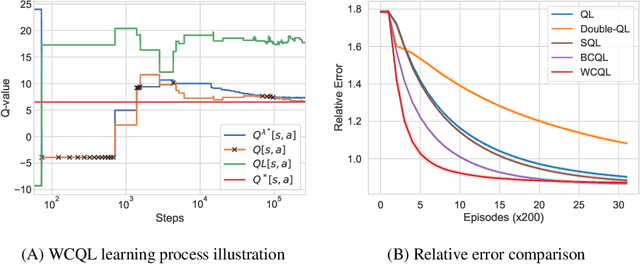
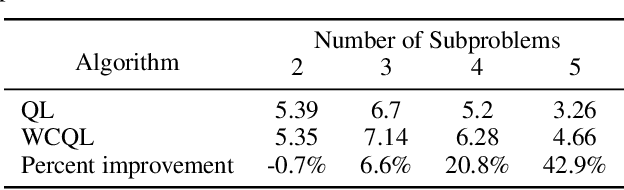
We propose weakly coupled deep Q-networks (WCDQN), a novel deep reinforcement learning algorithm that enhances performance in a class of structured problems called weakly coupled Markov decision processes (WCMDP). WCMDPs consist of multiple independent subproblems connected by an action space constraint, which is a structural property that frequently emerges in practice. Despite this appealing structure, WCMDPs quickly become intractable as the number of subproblems grows. WCDQN employs a single network to train multiple DQN "subagents", one for each subproblem, and then combine their solutions to establish an upper bound on the optimal action value. This guides the main DQN agent towards optimality. We show that the tabular version, weakly coupled Q-learning (WCQL), converges almost surely to the optimal action value. Numerical experiments show faster convergence compared to DQN and related techniques in settings with as many as 10 subproblems, $3^{10}$ total actions, and a continuous state space.
Lookahead-Bounded Q-Learning
Jun 28, 2020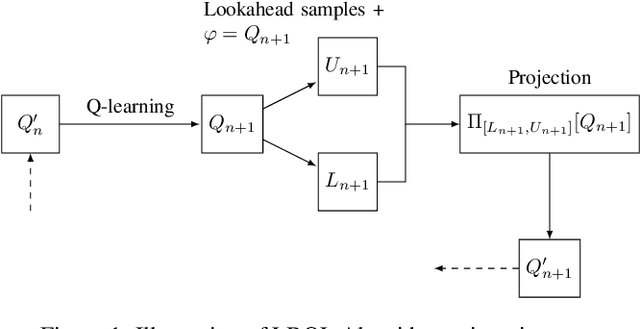
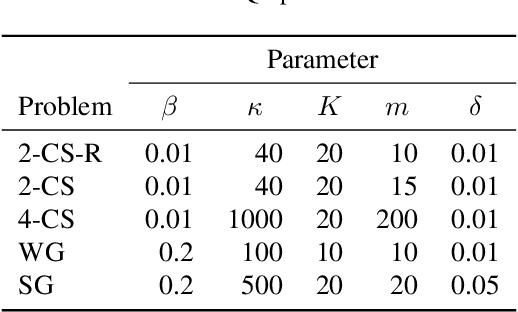

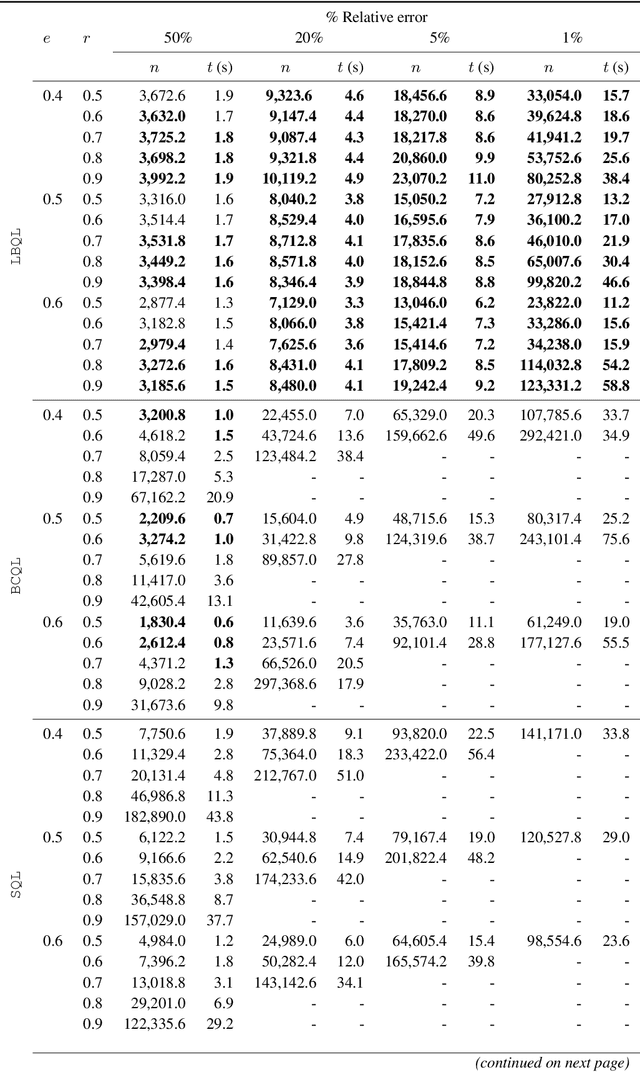
We introduce the lookahead-bounded Q-learning (LBQL) algorithm, a new, provably convergent variant of Q-learning that seeks to improve the performance of standard Q-learning in stochastic environments through the use of ``lookahead'' upper and lower bounds. To do this, LBQL employs previously collected experience and each iteration's state-action values as dual feasible penalties to construct a sequence of sampled information relaxation problems. The solutions to these problems provide estimated upper and lower bounds on the optimal value, which we track via stochastic approximation. These quantities are then used to constrain the iterates to stay within the bounds at every iteration. Numerical experiments on benchmark problems show that LBQL exhibits faster convergence and more robustness to hyperparameters when compared to standard Q-learning and several related techniques. Our approach is particularly appealing in problems that require expensive simulations or real-world interactions.