 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Feature Representation on the Accuracy of Photonic Neural Networks
Jun 26, 2024



Photonic Neural Networks (PNNs) are gaining significant interest in the research community due to their potential for high parallelization, low latency, and energy efficiency. PNNs compute using light, which leads to several differences in implementation when compared to electronics, such as the need to represent input features in the photonic domain before feeding them into the network. In this encoding process, it is common to combine multiple features into a single input to reduce the number of inputs and associated devices, leading to smaller and more energy-efficient PNNs. Although this alters the network's handling of input data, its impact on PNNs remains understudied. This paper addresses this open question, investigating the effect of commonly used encoding strategies that combine features on the performance and learning capabilities of PNNs. Here, using the concept of feature importance, we develop a mathematical framework for analyzing feature combination. Through this framework, we demonstrate that encoding multiple features together in a single input determines their relative importance, thus limiting the network's ability to learn from the data. Given some prior knowledge of the data, however, this can also be leveraged for higher accuracy. By selecting an optimal encoding method, we achieve up to a 12.3\% improvement in accuracy of PNNs trained on the Iris dataset compared to other encoding techniques, surpassing the performance of networks where features are not combined. These findings highlight the importance of carefully choosing the encoding to the accuracy and decision-making strategies of PNNs, particularly in size or power constrained applications.
NEUROPULS: NEUROmorphic energy-efficient secure accelerators based on Phase change materials aUgmented siLicon photonicS
May 04, 2023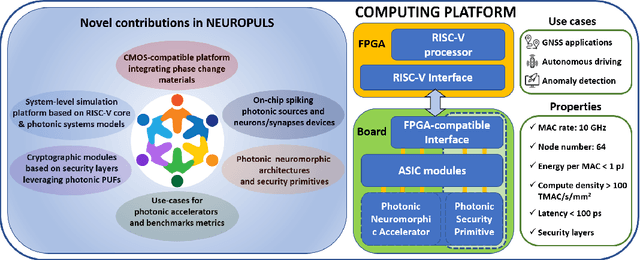
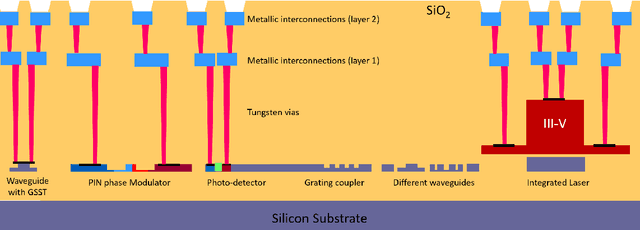
This special session paper introduces the Horizon Europe NEUROPULS project, which targets the development of secure and energy-efficient RISC-V interfaced neuromorphic accelerators using augmented silicon photonics technology. Our approach aims to develop an augmented silicon photonics platform, an FPGA-powered RISC-V-connected computing platform, and a complete simulation platform to demonstrate the neuromorphic accelerator capabilities. In particular, their main advantages and limitations will be addressed concerning the underpinning technology for each platform. Then, we will discuss three targeted use cases for edge-computing applications: Global National Satellite System (GNSS) anti-jamming, autonomous driving, and anomaly detection in edge devices. Finally, we will address the reliability and security aspects of the stand-alone accelerator implementation and the project use cases.
Approximations in Deep Learning
Dec 08, 2022The design and implementation of Deep Learning (DL) models is currently receiving a lot of attention from both industrials and academics. However, the computational workload associated with DL is often out of reach for low-power embedded devices and is still costly when run on datacenters. By relaxing the need for fully precise operations, Approximate Computing (AxC) substantially improves performance and energy efficiency. DL is extremely relevant in this context, since playing with the accuracy needed to do adequate computations will significantly enhance performance, while keeping the quality of results in a user-constrained range. This chapter will explore how AxC can improve the performance and energy efficiency of hardware accelerators in DL applications during inference and training.
Hitless memory-reconfigurable photonic reservoir computing architecture
Jul 13, 2022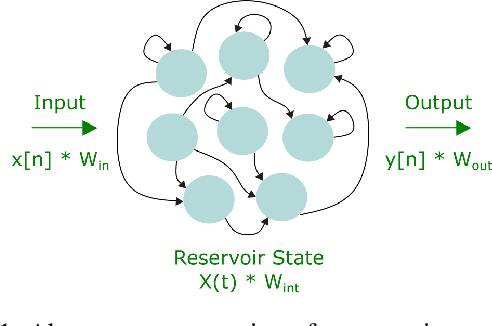
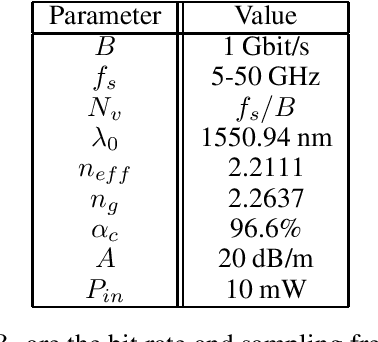
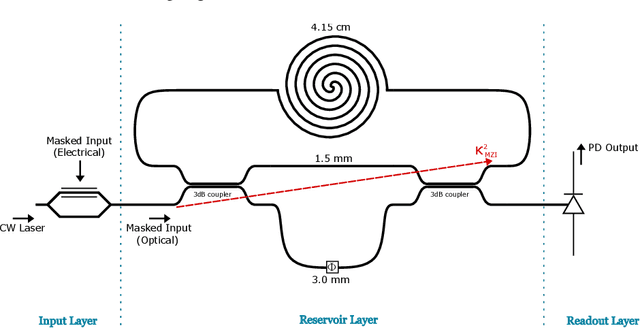

Reservoir computing is an analog bio-inspired computation model for efficiently processing time-dependent signals, the photonic implementations of which promise a combination of massive parallel information processing, low power consumption, and high speed operation. However, most implementations, especially for the case of time-delay reservoir computing (TDRC), require signal attenuation in the reservoir to achieve the desired system dynamics for a specific task, often resulting in large amounts of power being coupled outside of the system. We propose a novel TDRC architecture based on an asymmetric Mach-Zehnder interferometer (MZI) integrated in a resonant cavity which allows the memory capacity of the system to be tuned without the need for an optical attenuator block. Furthermore, this can be leveraged to find the optimal value for the specific components of the total memory capacity metric. We demonstrate this approach on the temporal bitwise XOR task and conclude that this way of memory capacity reconfiguration allows optimal performance to be achieved for memory-specific tasks.
Fast Exploration of Weight Sharing Opportunities for CNN Compression
Feb 02, 2021
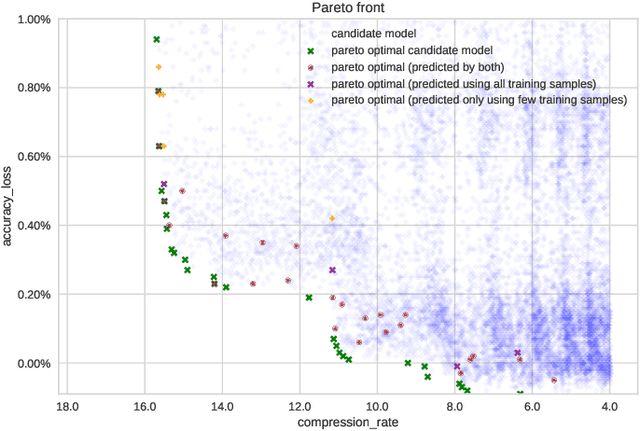
The computational workload involved in Convolutional Neural Networks (CNNs) is typically out of reach for low-power embedded devices. There are a large number of approximation techniques to address this problem. These methods have hyper-parameters that need to be optimized for each CNNs using design space exploration (DSE). The goal of this work is to demonstrate that the DSE phase time can easily explode for state of the art CNN. We thus propose the use of an optimized exploration process to drastically reduce the exploration time without sacrificing the quality of the output.