 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Potential Drug Targets Using Tensor Factorisation and Knowledge Graph Embeddings
May 20, 2021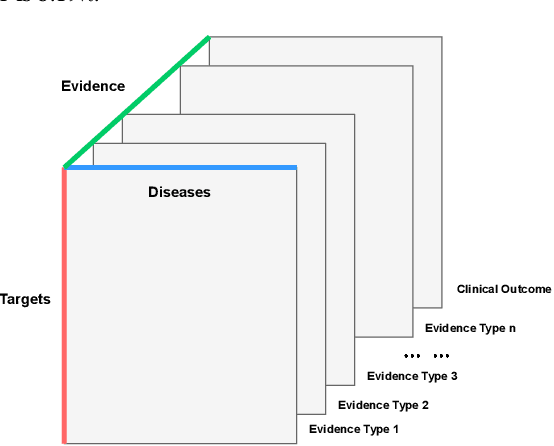
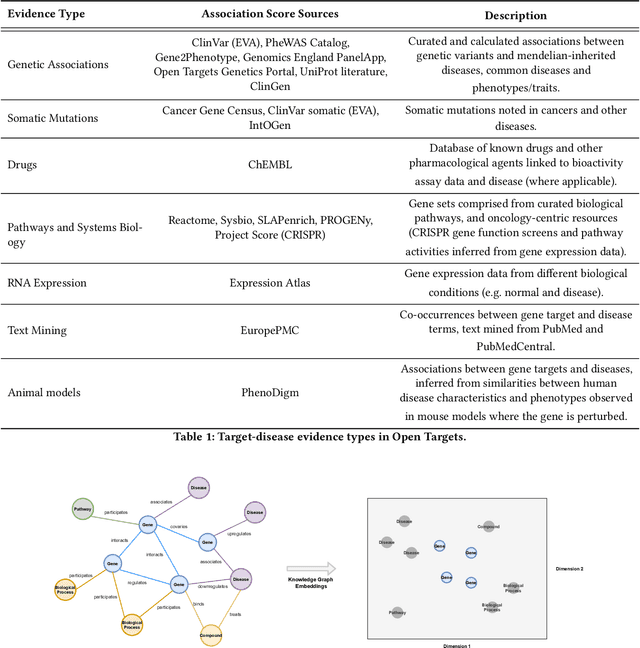
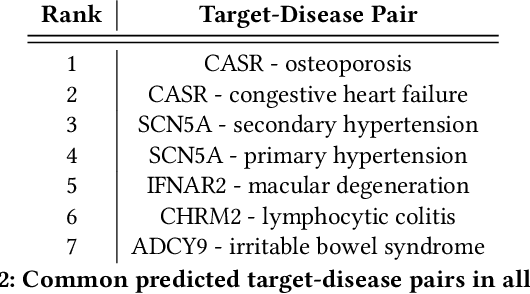
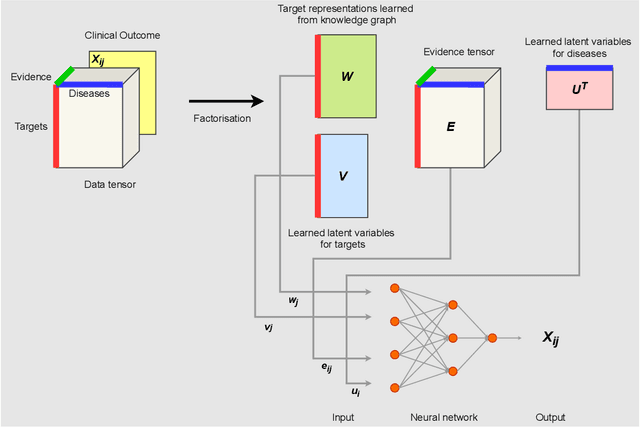
The drug discovery and development process is a long and expensive one, costing over 1 billion USD on average per drug and taking 10-15 years. To reduce the high levels of attrition throughout the process, there has been a growing interest in applying machine learning methodologies to various stages of drug discovery process in the recent decade, including at the earliest stage - identification of druggable disease genes. In this paper, we have developed a new tensor factorisation model to predict potential drug targets (i.e.,genes or proteins) for diseases. We created a three dimensional tensor which consists of 1,048 targets, 860 diseases and 230,011 evidence attributes and clinical outcomes connecting them, using data extracted from the Open Targets and PharmaProjects databases. We enriched the data with gene representations learned from a drug discovery-oriented knowledge graph and applied our proposed method to predict the clinical outcomes for unseen target and dis-ease pairs. We designed three evaluation strategies to measure the prediction performance and benchmarked several commonly used machine learning classifiers together with matrix and tensor factorisation methods. The result shows that incorporating knowledge graph embeddings significantly improves the prediction accuracy and that training tensor factorisation alongside a dense neural network outperforms other methods. In summary, our framework combines two actively studied machine learning approaches to disease target identification, tensor factorisation and knowledge graph representation learning, which could be a promising avenue for further exploration in data-driven drug discovery.