 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-Users
Jun 30, 2016

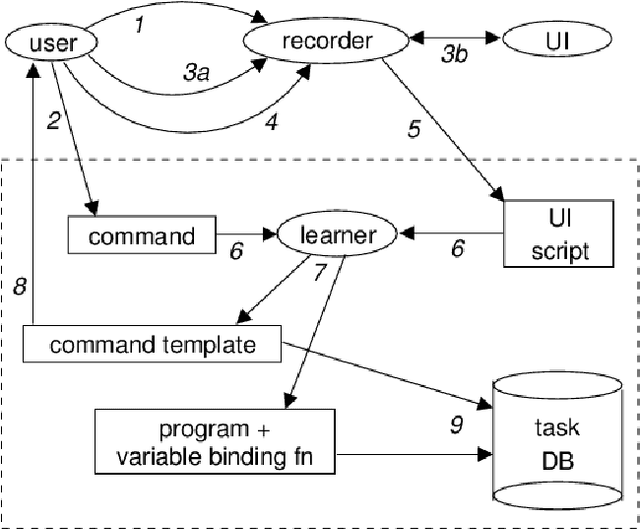
The challenge stated in the title can be divided into two main problems. The first problem is to reliably mimic the way that users interact with user interfaces. The second problem is to build an instructible agent, i.e. one that can be taught to execute tasks expressed as previously unseen natural language commands. This paper proposes a solution to the second problem, a system we call Helpa. End-users can teach Helpa arbitrary new tasks whose level of complexity is similar to the tasks available from today's most popular virtual assistants. Teaching Helpa does not involve any programming. Instead, users teach Helpa by providing just one example of a command paired with a demonstration of how to execute that command. Helpa does not rely on any pre-existing domain-specific knowledge. It is therefore completely domain-independent. Our usability study showed that end-users can teach Helpa many new tasks in less than a minute each, often much less.
Statistical Machine Translation by Generalized Parsing
Nov 24, 2005

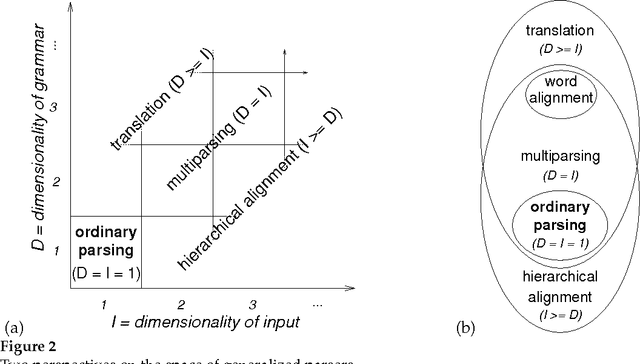

Designers of statistical machine translation (SMT) systems have begun to employ tree-structured translation models. Systems involving tree-structured translation models tend to be complex. This article aims to reduce the conceptual complexity of such systems, in order to make them easier to design, implement, debug, use, study, understand, explain, modify, and improve. In service of this goal, the article extends the theory of semiring parsing to arrive at a novel abstract parsing algorithm with five functional parameters: a logic, a grammar, a semiring, a search strategy, and a termination condition. The article then shows that all the common algorithms that revolve around tree-structured translation models, including hierarchical alignment, inference for parameter estimation, translation, and structured evaluation, can be derived by generalizing two of these parameters -- the grammar and the logic. The article culminates with a recipe for using such generalized parsers to train, apply, and evaluate an SMT system that is driven by tree-structured translation models.
Tagger Evaluation Given Hierarchical Tag Sets
Aug 10, 2000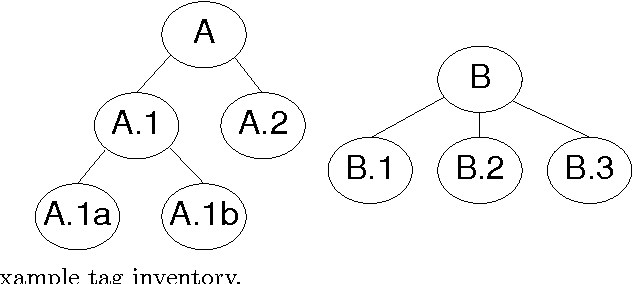

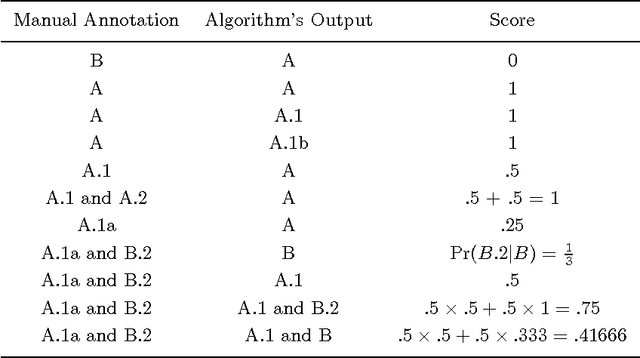
We present methods for evaluating human and automatic taggers that extend current practice in three ways. First, we show how to evaluate taggers that assign multiple tags to each test instance, even if they do not assign probabilities. Second, we show how to accommodate a common property of manually constructed ``gold standards'' that are typically used for objective evaluation, namely that there is often more than one correct answer. Third, we show how to measure performance when the set of possible tags is tree-structured in an IS-A hierarchy. To illustrate how our methods can be used to measure inter-annotator agreement, we show how to compute the kappa coefficient over hierarchical tag sets.
* preprint is 7 pages, laid out differently than printed version
Word-to-Word Models of Translational Equivalence
May 11, 1998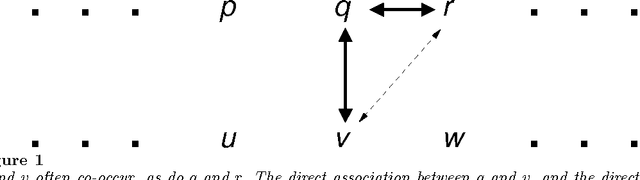


Parallel texts (bitexts) have properties that distinguish them from other kinds of parallel data. First, most words translate to only one other word. Second, bitext correspondence is noisy. This article presents methods for biasing statistical translation models to reflect these properties. Analysis of the expected behavior of these biases in the presence of sparse data predicts that they will result in more accurate models. The prediction is confirmed by evaluation with respect to a gold standard -- translation models that are biased in this fashion are significantly more accurate than a baseline knowledge-poor model. This article also shows how a statistical translation model can take advantage of various kinds of pre-existing knowledge that might be available about particular language pairs. Even the simplest kinds of language-specific knowledge, such as the distinction between content words and function words, is shown to reliably boost translation model performance on some tasks. Statistical models that are informed by pre-existing knowledge about the model domain combine the best of both the rationalist and empiricist traditions.
Manual Annotation of Translational Equivalence: The Blinker Project
May 11, 1998
Bilingual annotators were paid to link roughly sixteen thousand corresponding words between on-line versions of the Bible in modern French and modern English. These annotations are freely available to the research community from http://www.cis.upenn.edu/~melamed . The annotations can be used for several purposes. First, they can be used as a standard data set for developing and testing translation lexicons and statistical translation models. Second, researchers in lexical semantics will be able to mine the annotations for insights about cross-linguistic lexicalization patterns. Third, the annotations can be used in research into certain recently proposed methods for monolingual word-sense disambiguation. This paper describes the annotated texts, the specially-designed annotation tool, and the strategies employed to increase the consistency of the annotations. The annotation process was repeated five times by different annotators. Inter-annotator agreement rates indicate that the annotations are reasonably reliable and that the method is easy to replicate.
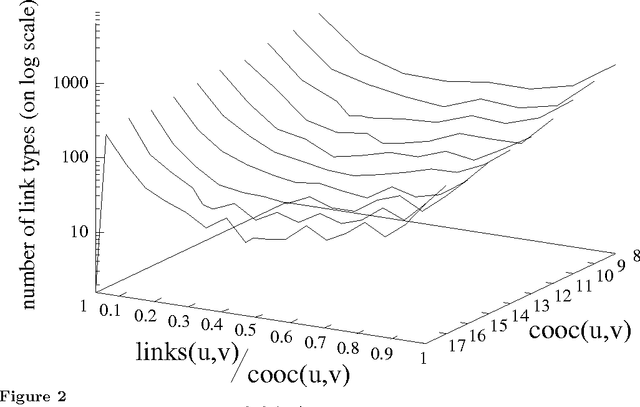
Models of Co-occurrence
May 08, 1998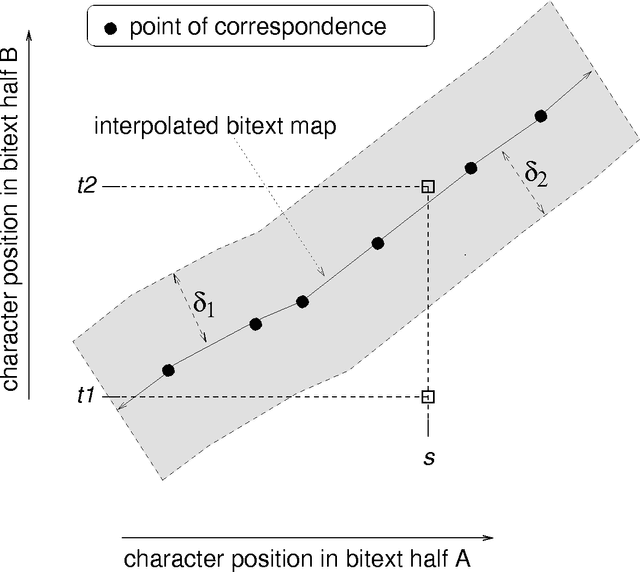
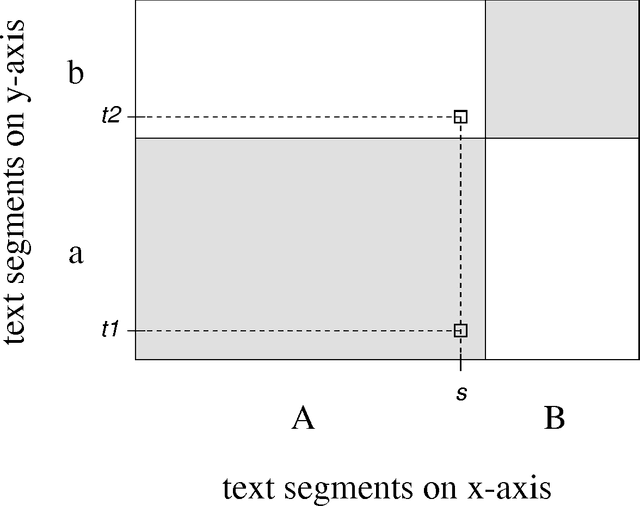
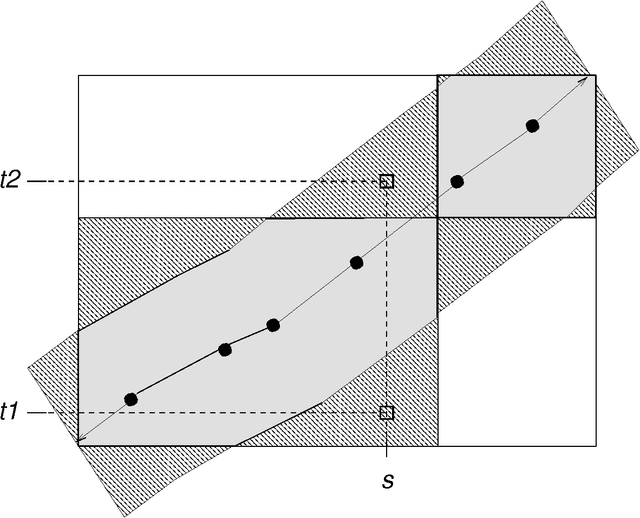
A model of co-occurrence in bitext is a boolean predicate that indicates whether a given pair of word tokens co-occur in corresponding regions of the bitext space. Co-occurrence is a precondition for the possibility that two tokens might be mutual translations. Models of co-occurrence are the glue that binds methods for mapping bitext correspondence with methods for estimating translation models into an integrated system for exploiting parallel texts. Different models of co-occurrence are possible, depending on the kind of bitext map that is available, the language-specific information that is available, and the assumptions made about the nature of translational equivalence. Although most statistical translation models are based on models of co-occurrence, modeling co-occurrence correctly is more difficult than it may at first appear.
Annotation Style Guide for the Blinker Project
May 08, 1998
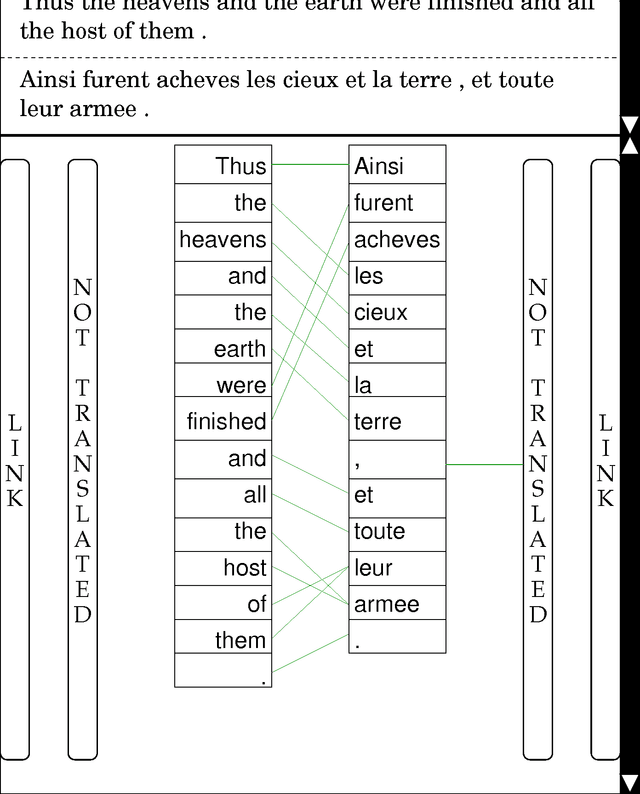
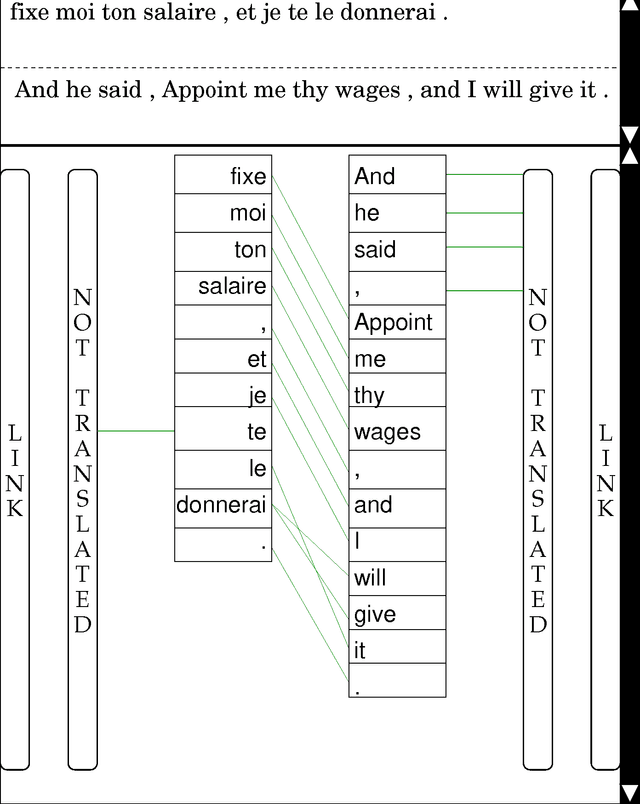
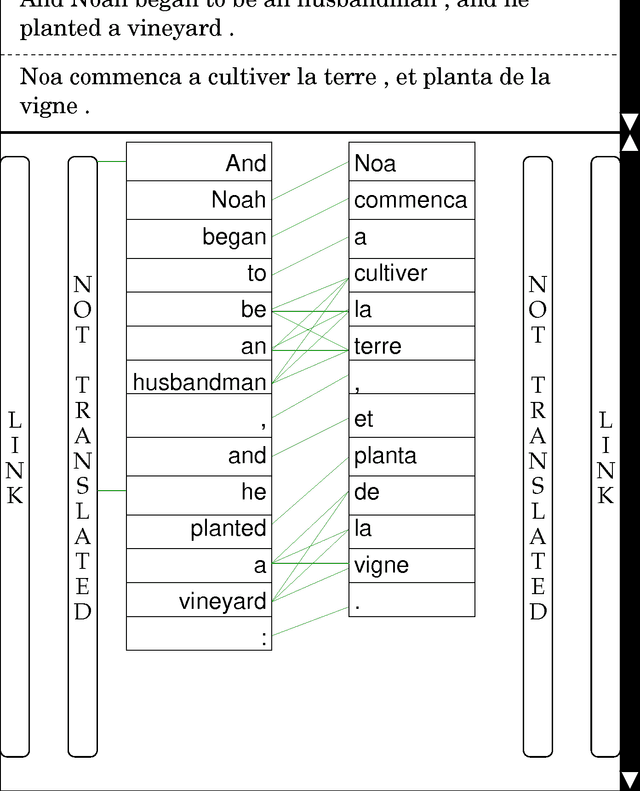
This annotation style guide was created by and for the Blinker project at the University of Pennsylvania. The Blinker project was so named after the ``bilingual linker'' GUI, which was created to enable bilingual annotators to ``link'' word tokens that are mutual translations in parallel texts. The parallel text chosen for this project was the Bible, because it is probably the easiest text to obtain in electronic form in multiple languages. The languages involved were English and French, because, of the languages with which the project co-ordinator was familiar, these were the two for which a sufficient number of annotators was likely to be found.
Automatic Discovery of Non-Compositional Compounds in Parallel Data
Jun 24, 1997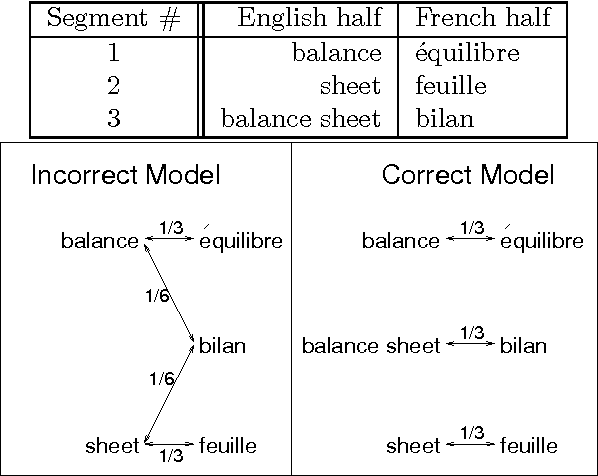
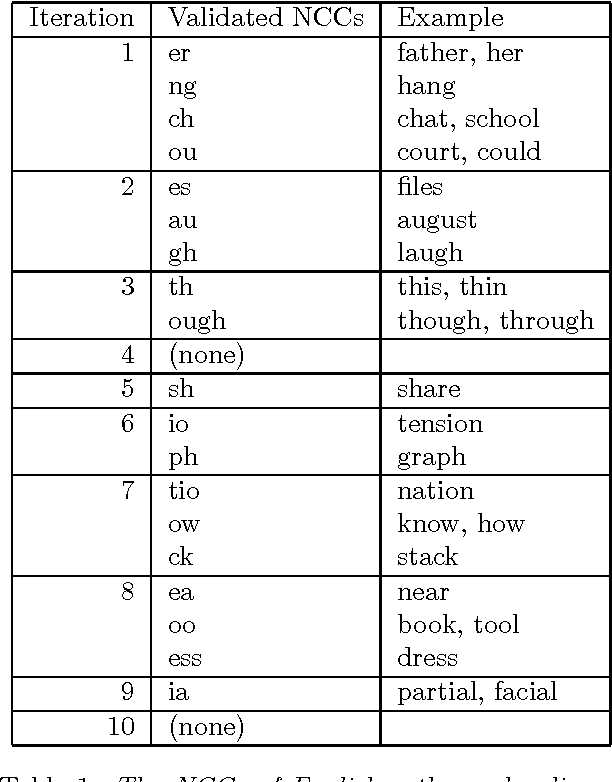
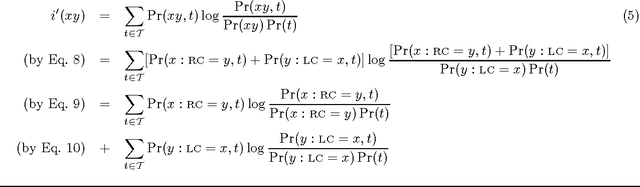
Automatic segmentation of text into minimal content-bearing units is an unsolved problem even for languages like English. Spaces between words offer an easy first approximation, but this approximation is not good enough for machine translation (MT), where many word sequences are not translated word-for-word. This paper presents an efficient automatic method for discovering sequences of words that are translated as a unit. The method proceeds by comparing pairs of statistical translation models induced from parallel texts in two languages. It can discover hundreds of non-compositional compounds on each iteration, and constructs longer compounds out of shorter ones. Objective evaluation on a simple machine translation task has shown the method's potential to improve the quality of MT output. The method makes few assumptions about the data, so it can be applied to parallel data other than parallel texts, such as word spellings and pronunciations.
* 12 pages; uses natbib.sty, here.sty
A Word-to-Word Model of Translational Equivalence
Jun 24, 1997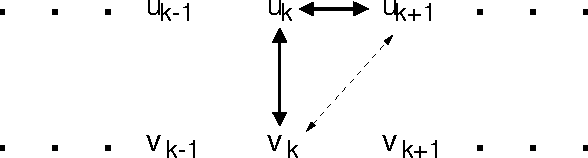


Many multilingual NLP applications need to translate words between different languages, but cannot afford the computational expense of inducing or applying a full translation model. For these applications, we have designed a fast algorithm for estimating a partial translation model, which accounts for translational equivalence only at the word level. The model's precision/recall trade-off can be directly controlled via one threshold parameter. This feature makes the model more suitable for applications that are not fully statistical. The model's hidden parameters can be easily conditioned on information extrinsic to the model, providing an easy way to integrate pre-existing knowledge such as part-of-speech, dictionaries, word order, etc.. Our model can link word tokens in parallel texts as well as other translation models in the literature. Unlike other translation models, it can automatically produce dictionary-sized translation lexicons, and it can do so with over 99% accuracy.
* 8 pages; this version has some typos corrected
A Portable Algorithm for Mapping Bitext Correspondence
Jun 24, 1997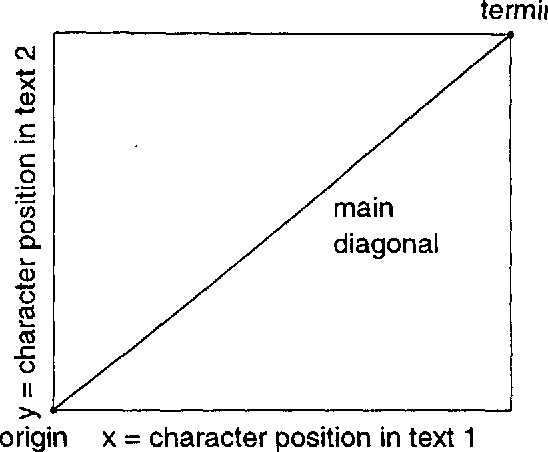

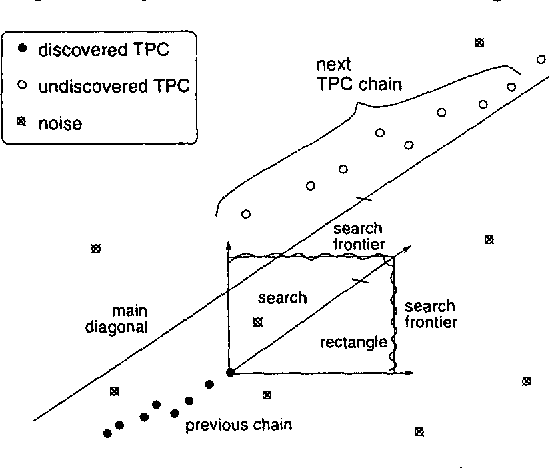
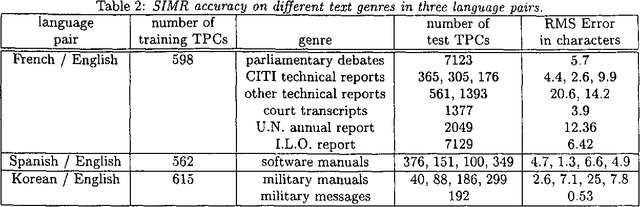
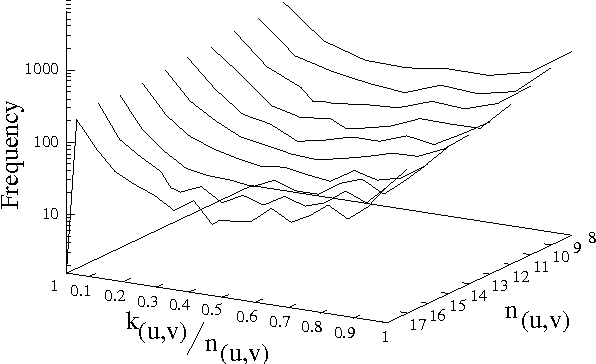
The first step in most empirical work in multilingual NLP is to construct maps of the correspondence between texts and their translations ({\bf bitext maps}). The Smooth Injective Map Recognizer (SIMR) algorithm presented here is a generic pattern recognition algorithm that is particularly well-suited to mapping bitext correspondence. SIMR is faster and significantly more accurate than other algorithms in the literature. The algorithm is robust enough to use on noisy texts, such as those resulting from OCR input, and on translations that are not very literal. SIMR encapsulates its language-specific heuristics, so that it can be ported to any language pair with a minimal effort.
* 8 pages