 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASemConsist: Adaptive Semantic Feature Control for Training-Free Identity-Consistent Generation
Dec 29, 2025Recent text-to-image diffusion models have significantly improved visual quality and text alignment. However, generating a sequence of images while preserving consistent character identity across diverse scene descriptions remains a challenging task. Existing methods often struggle with a trade-off between maintaining identity consistency and ensuring per-image prompt alignment. In this paper, we introduce a novel framework, ASemconsist, that addresses this challenge through selective text embedding modification, enabling explicit semantic control over character identity without sacrificing prompt alignment. Furthermore, based on our analysis of padding embeddings in FLUX, we propose a semantic control strategy that repurposes padding embeddings as semantic containers. Additionally, we introduce an adaptive feature-sharing strategy that automatically evaluates textual ambiguity and applies constraints only to the ambiguous identity prompt. Finally, we propose a unified evaluation protocol, the Consistency Quality Score (CQS), which integrates identity preservation and per-image text alignment into a single comprehensive metric, explicitly capturing performance imbalances between the two metrics. Our framework achieves state-of-the-art performance, effectively overcoming prior trade-offs. Project page: https://minjung-s.github.io/asemconsist
Semantic Image Synthesis with Unconditional Generator
Feb 22, 2024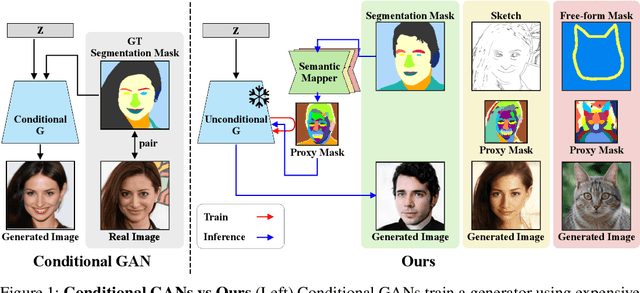
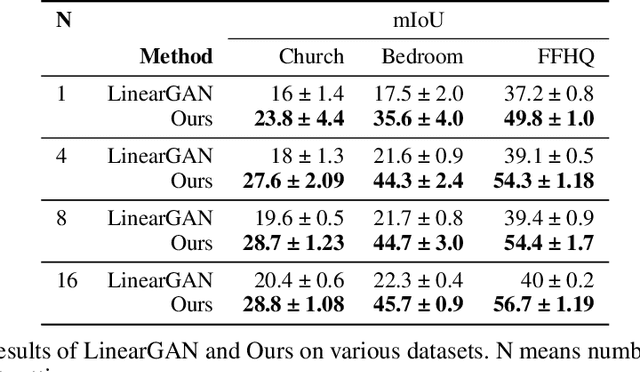
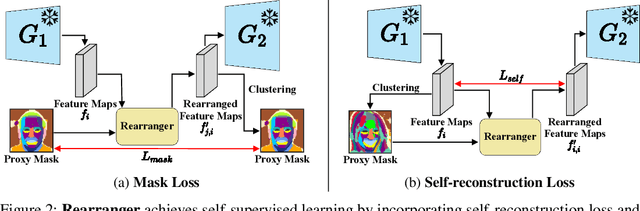
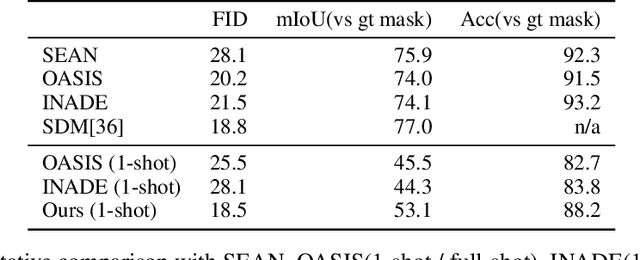
Semantic image synthesis (SIS) aims to generate realistic images that match given semantic masks. Despite recent advances allowing high-quality results and precise spatial control, they require a massive semantic segmentation dataset for training the models. Instead, we propose to employ a pre-trained unconditional generator and rearrange its feature maps according to proxy masks. The proxy masks are prepared from the feature maps of random samples in the generator by simple clustering. The feature rearranger learns to rearrange original feature maps to match the shape of the proxy masks that are either from the original sample itself or from random samples. Then we introduce a semantic mapper that produces the proxy masks from various input conditions including semantic masks. Our method is versatile across various applications such as free-form spatial editing of real images, sketch-to-photo, and even scribble-to-photo. Experiments validate advantages of our method on a range of datasets: human faces, animal faces, and buildings.