 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Autonomous Cyber Defense using Adversarial Multi-Agent Reinforcement Learning
Apr 06, 2026Autonomous agents are increasingly deployed in both offensive and defensive cyber operations, creating high-speed, closed-loop interactions in critical infrastructure environments. Advanced Persistent Threat (APT) actors exploit "Living off the Land" techniques and targeted telemetry perturbations to induce ambiguity in monitoring systems, causing automated defenses to overreact or misclassify benign behavior as malicious activity. Existing monolithic and multi-agent defense pipelines largely operate on correlation-based signals, lack structural constraints on response actions, and are vulnerable to reasoning drift under ambiguous or adversarial inputs. We present the Causal Multi-Agent Decision Framework (C-MADF), a structurally constrained architecture for autonomous cyber defense that integrates causal modeling with adversarial dual-policy control. C-MADF first learns a Structural Causal Model (SCM) from historical telemetry and compiles it into an investigation-level Directed Acyclic Graph (DAG) that defines admissible response transitions. This roadmap is formalized as a Markov Decision Process (MDP) whose action space is explicitly restricted to causally consistent transitions. Decision-making within this constrained space is performed by a dual-agent reinforcement learning system in which a threat-optimizing Blue-Team policy is counterbalanced by a conservatively shaped Red-Team policy. Inter-policy disagreement is quantified through a Policy Divergence Score and exposed via a human-in-the-loop interface equipped with an Explainability-Transparency Score that serves as an escalation signal under uncertainty. On the real-world CICIoT2023 dataset, C-MADF reduces the false-positive rate from 11.2%, 9.7%, and 8.4% in three cutting-edge literature baselines to 1.8%, while achieving 0.997 precision, 0.961 recall, and 0.979 F1-score.
A Benchmark Dataset and a Framework for Urdu Multimodal Named Entity Recognition
May 08, 2025



The emergence of multimodal content, particularly text and images on social media, has positioned Multimodal Named Entity Recognition (MNER) as an increasingly important area of research within Natural Language Processing. Despite progress in high-resource languages such as English, MNER remains underexplored for low-resource languages like Urdu. The primary challenges include the scarcity of annotated multimodal datasets and the lack of standardized baselines. To address these challenges, we introduce the U-MNER framework and release the Twitter2015-Urdu dataset, a pioneering resource for Urdu MNER. Adapted from the widely used Twitter2015 dataset, it is annotated with Urdu-specific grammar rules. We establish benchmark baselines by evaluating both text-based and multimodal models on this dataset, providing comparative analyses to support future research on Urdu MNER. The U-MNER framework integrates textual and visual context using Urdu-BERT for text embeddings and ResNet for visual feature extraction, with a Cross-Modal Fusion Module to align and fuse information. Our model achieves state-of-the-art performance on the Twitter2015-Urdu dataset, laying the groundwork for further MNER research in low-resource languages.
The Future of AI: Exploring the Potential of Large Concept Models
Jan 08, 2025The field of Artificial Intelligence (AI) continues to drive transformative innovations, with significant progress in conversational interfaces, autonomous vehicles, and intelligent content creation. Since the launch of ChatGPT in late 2022, the rise of Generative AI has marked a pivotal era, with the term Large Language Models (LLMs) becoming a ubiquitous part of daily life. LLMs have demonstrated exceptional capabilities in tasks such as text summarization, code generation, and creative writing. However, these models are inherently limited by their token-level processing, which restricts their ability to perform abstract reasoning, conceptual understanding, and efficient generation of long-form content. To address these limitations, Meta has introduced Large Concept Models (LCMs), representing a significant shift from traditional token-based frameworks. LCMs use concepts as foundational units of understanding, enabling more sophisticated semantic reasoning and context-aware decision-making. Given the limited academic research on this emerging technology, our study aims to bridge the knowledge gap by collecting, analyzing, and synthesizing existing grey literature to provide a comprehensive understanding of LCMs. Specifically, we (i) identify and describe the features that distinguish LCMs from LLMs, (ii) explore potential applications of LCMs across multiple domains, and (iii) propose future research directions and practical strategies to advance LCM development and adoption.
Machine Learning Driven Smishing Detection Framework for Mobile Security
Dec 09, 2024



The increasing reliance on smartphones for communication, financial transactions, and personal data management has made them prime targets for cyberattacks, particularly smishing, a sophisticated variant of phishing conducted via SMS. Despite the growing threat, traditional detection methods often struggle with the informal and evolving nature of SMS language, which includes abbreviations, slang, and short forms. This paper presents an enhanced content-based smishing detection framework that leverages advanced text normalization techniques to improve detection accuracy. By converting nonstandard text into its standardized form, the proposed model enhances the efficacy of machine learning classifiers, particularly the Naive Bayesian classifier, in distinguishing smishing messages from legitimate ones. Our experimental results, validated on a publicly available dataset, demonstrate a detection accuracy of 96.2%, with a low False Positive Rate of 3.87% and False Negative Rate of 2.85%. This approach significantly outperforms existing methodologies, providing a robust solution to the increasingly sophisticated threat of smishing in the mobile environment.
ChatNVD: Advancing Cybersecurity Vulnerability Assessment with Large Language Models
Dec 06, 2024The increasing frequency and sophistication of cybersecurity vulnerabilities in software systems underscore the urgent need for robust and effective methods of vulnerability assessment. However, existing approaches often rely on highly technical and abstract frameworks, which hinders understanding and increases the likelihood of exploitation, resulting in severe cyberattacks. Given the growing adoption of Large Language Models (LLMs) across diverse domains, this paper explores their potential application in cybersecurity, specifically for enhancing the assessment of software vulnerabilities. We propose ChatNVD, an LLM-based cybersecurity vulnerability assessment tool leveraging the National Vulnerability Database (NVD) to provide context-rich insights and streamline vulnerability analysis for cybersecurity professionals, developers, and non-technical users. We develop three variants of ChatNVD, utilizing three prominent LLMs: GPT-4o mini by OpenAI, Llama 3 by Meta, and Gemini 1.5 Pro by Google. To evaluate their efficacy, we conduct a comparative analysis of these models using a comprehensive questionnaire comprising common security vulnerability questions, assessing their accuracy in identifying and analyzing software vulnerabilities. This study provides valuable insights into the potential of LLMs to address critical challenges in understanding and mitigation of software vulnerabilities.
Robust Partial Least Squares Using Low Rank and Sparse Decomposition
Jul 09, 2024This paper proposes a framework for simultaneous dimensionality reduction and regression in the presence of outliers in data by applying low-rank and sparse matrix decomposition. For multivariate data corrupted with outliers, it is generally hard to estimate the true low dimensional manifold from corrupted data. The objective of the proposed framework is to find a robust estimate of the low dimensional space of data to reliably perform regression. The effectiveness of the proposed algorithm is demonstrated experimentally for simultaneous regression and dimensionality reduction in the presence of outliers in data.
"I think this is the most disruptive technology": Exploring Sentiments of ChatGPT Early Adopters using Twitter Data
Dec 12, 2022

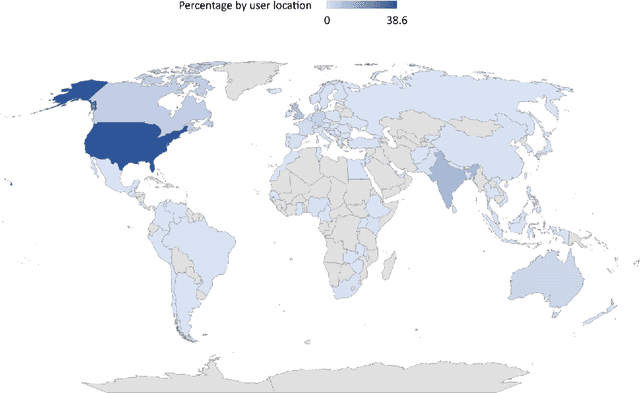
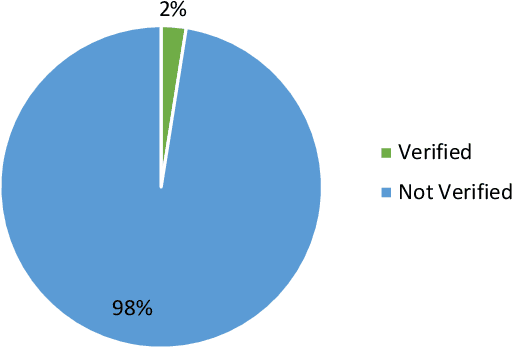
Large language models have recently attracted significant attention due to their impressive performance on a variety of tasks. ChatGPT developed by OpenAI is one such implementation of a large, pre-trained language model that has gained immense popularity among early adopters, where certain users go to the extent of characterizing it as a disruptive technology in many domains. Understanding such early adopters' sentiments is important because it can provide insights into the potential success or failure of the technology, as well as its strengths and weaknesses. In this paper, we conduct a mixed-method study using 10,732 tweets from early ChatGPT users. We first use topic modelling to identify the main topics and then perform an in-depth qualitative sentiment analysis of each topic. Our results show that the majority of the early adopters have expressed overwhelmingly positive sentiments related to topics such as Disruptions to software development, Entertainment and exercising creativity. Only a limited percentage of users expressed concerns about issues such as the potential for misuse of ChatGPT, especially regarding topics such as Impact on educational aspects. We discuss these findings by providing specific examples for each topic and then detail implications related to addressing these concerns for both researchers and users.
Smart Grid: A Survey of Architectural Elements, Machine Learning and Deep Learning Applications and Future Directions
Oct 16, 2020
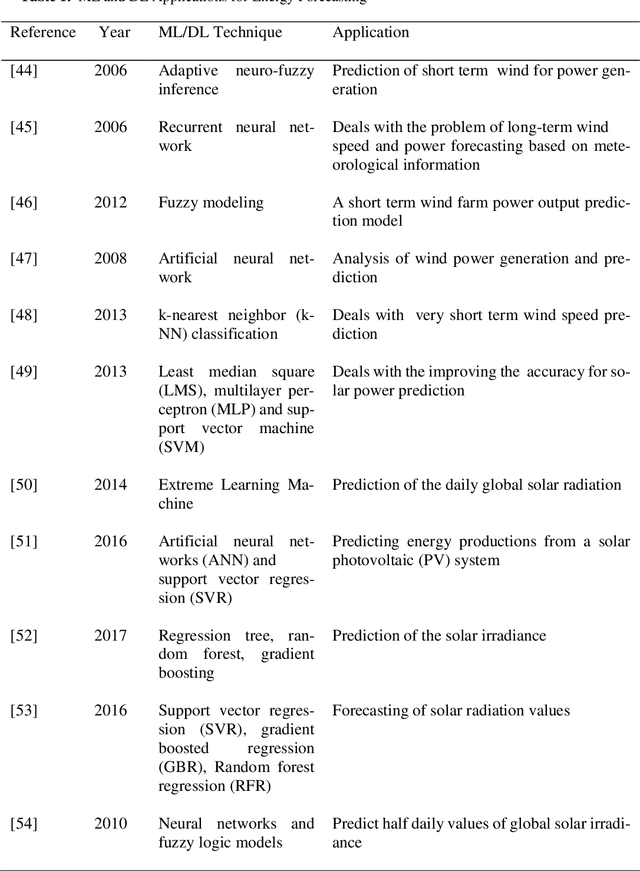
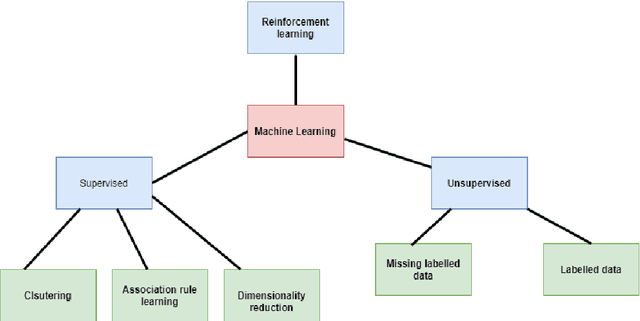
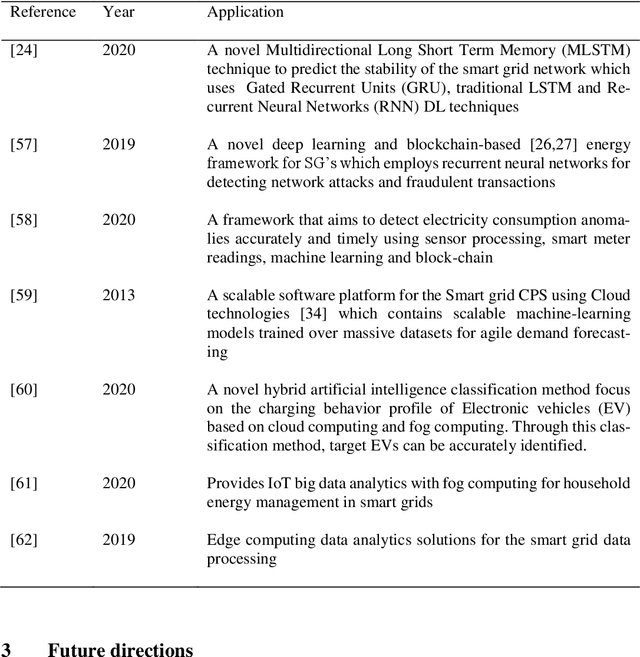
The Smart grid (SG), generally known as the next-generation power grid emerged as a replacement for ill-suited power systems in the 21st century. It is in-tegrated with advanced communication and computing capabilities, thus it is ex-pected to enhance the reliability and the efficiency of energy distribution with minimum effects. With the massive infrastructure it holds and the underlying communication network in the system, it introduced a large volume of data that demands various techniques for proper analysis and decision making. Big data analytics, machine learning (ML), and deep learning (DL) plays a key role when it comes to the analysis of this massive amount of data and generation of valuable insights. This paper explores and surveys the Smart grid architectural elements, machine learning, and deep learning-based applications and approaches in the context of the Smart grid. In addition in terms of machine learning-based data an-alytics, this paper highlights the limitations of the current research and highlights future directions as well.