 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptOVCD: Training-Free Open-Vocabulary Remote Sensing Change Detection via Adaptive Information Fusion
Feb 06, 2026Remote sensing change detection plays a pivotal role in domains such as environmental monitoring, urban planning, and disaster assessment. However, existing methods typically rely on predefined categories and large-scale pixel-level annotations, which limit their generalization and applicability in open-world scenarios. To address these limitations, this paper proposes AdaptOVCD, a training-free Open-Vocabulary Change Detection (OVCD) architecture based on dual-dimensional multi-level information fusion. The framework integrates multi-level information fusion across data, feature, and decision levels vertically while incorporating targeted adaptive designs horizontally, achieving deep synergy among heterogeneous pre-trained models to effectively mitigate error propagation. Specifically, (1) at the data level, Adaptive Radiometric Alignment (ARA) fuses radiometric statistics with original texture features and synergizes with SAM-HQ to achieve radiometrically consistent segmentation; (2) at the feature level, Adaptive Change Thresholding (ACT) combines global difference distributions with edge structure priors and leverages DINOv3 to achieve robust change detection; (3) at the decision level, Adaptive Confidence Filtering (ACF) integrates semantic confidence with spatial constraints and collaborates with DGTRS-CLIP to achieve high-confidence semantic identification. Comprehensive evaluations across nine scenarios demonstrate that AdaptOVCD detects arbitrary category changes in a zero-shot manner, significantly outperforming existing training-free methods. Meanwhile, it achieves 84.89\% of the fully-supervised performance upper bound in cross-dataset evaluations and exhibits superior generalization capabilities. The code is available at https://github.com/Dmygithub/AdaptOVCD.
Enhancing 3D Medical Image Understanding with Pretraining Aided by 2D Multimodal Large Language Models
Sep 11, 2025Understanding 3D medical image volumes is critical in the medical field, yet existing 3D medical convolution and transformer-based self-supervised learning (SSL) methods often lack deep semantic comprehension. Recent advancements in multimodal large language models (MLLMs) provide a promising approach to enhance image understanding through text descriptions. To leverage these 2D MLLMs for improved 3D medical image understanding, we propose Med3DInsight, a novel pretraining framework that integrates 3D image encoders with 2D MLLMs via a specially designed plane-slice-aware transformer module. Additionally, our model employs a partial optimal transport based alignment, demonstrating greater tolerance to noise introduced by potential noises in LLM-generated content. Med3DInsight introduces a new paradigm for scalable multimodal 3D medical representation learning without requiring human annotations. Extensive experiments demonstrate our state-of-the-art performance on two downstream tasks, i.e., segmentation and classification, across various public datasets with CT and MRI modalities, outperforming current SSL methods. Med3DInsight can be seamlessly integrated into existing 3D medical image understanding networks, potentially enhancing their performance. Our source code, generated datasets, and pre-trained models will be available at https://github.com/Qybc/Med3DInsight.
Med3DInsight: Enhancing 3D Medical Image Understanding with 2D Multi-Modal Large Language Models
Mar 08, 2024


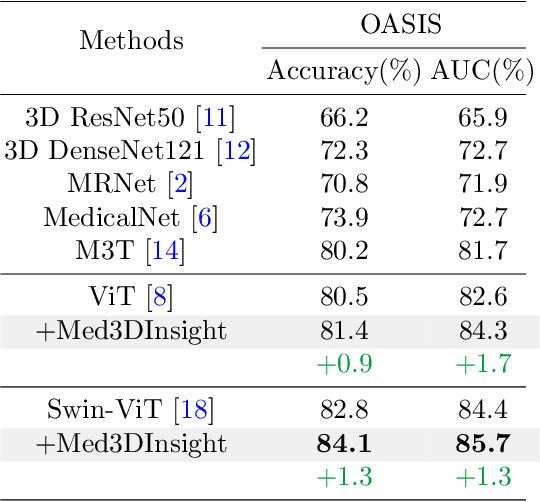
Understanding 3D medical image volumes is a critical task in the medical domain. However, existing 3D convolution and transformer-based methods have limited semantic understanding of an image volume and also need a large set of volumes for training. Recent advances in multi-modal large language models (MLLMs) provide a new and promising way to understand images with the help of text descriptions. However, most current MLLMs are designed for 2D natural images. To enhance the 3D medical image understanding with 2D MLLMs, we propose a novel pre-training framework called Med3DInsight, which marries existing 3D image encoders with 2D MLLMs and bridges them via a designed Plane-Slice-Aware Transformer (PSAT) module. Extensive experiments demonstrate our SOTA performance on two downstream segmentation and classification tasks, including three public datasets with CT and MRI modalities and comparison to more than ten baselines. Med3DInsight can be easily integrated into any current 3D medical image understanding network and improves its performance by a good margin.