 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMed3DInsight: Enhancing 3D Medical Image Understanding with 2D Multi-Modal Large Language Models
Paper and Code



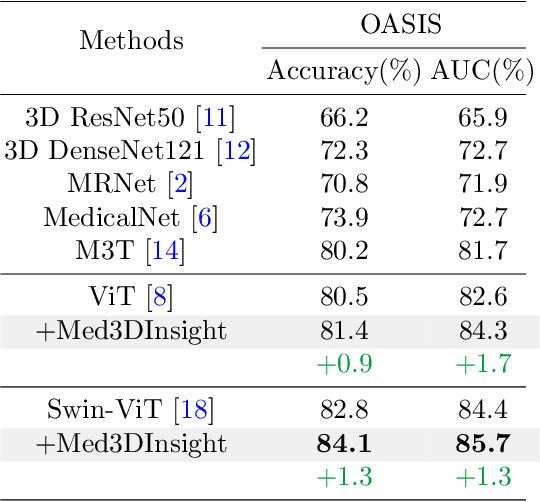
Understanding 3D medical image volumes is a critical task in the medical domain. However, existing 3D convolution and transformer-based methods have limited semantic understanding of an image volume and also need a large set of volumes for training. Recent advances in multi-modal large language models (MLLMs) provide a new and promising way to understand images with the help of text descriptions. However, most current MLLMs are designed for 2D natural images. To enhance the 3D medical image understanding with 2D MLLMs, we propose a novel pre-training framework called Med3DInsight, which marries existing 3D image encoders with 2D MLLMs and bridges them via a designed Plane-Slice-Aware Transformer (PSAT) module. Extensive experiments demonstrate our SOTA performance on two downstream segmentation and classification tasks, including three public datasets with CT and MRI modalities and comparison to more than ten baselines. Med3DInsight can be easily integrated into any current 3D medical image understanding network and improves its performance by a good margin.