 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA deep belief network-based method to identify proteomic risk markers for Alzheimer disease
Mar 11, 2020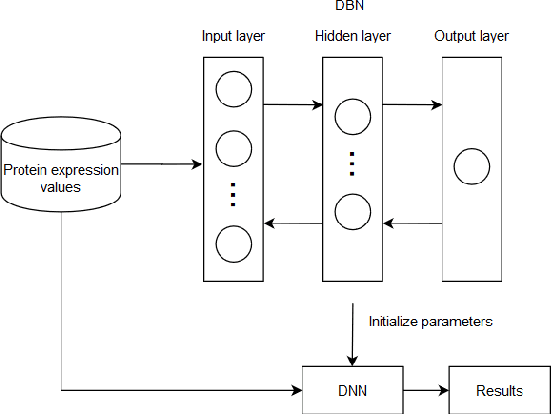
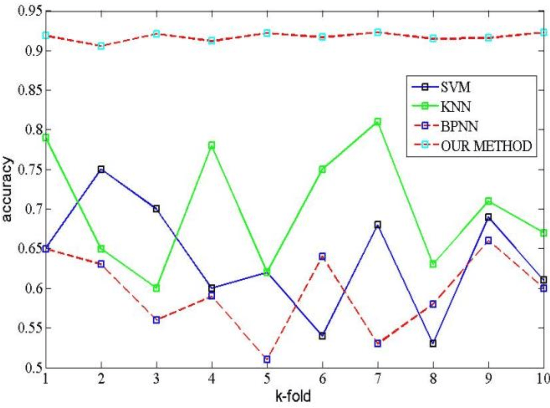
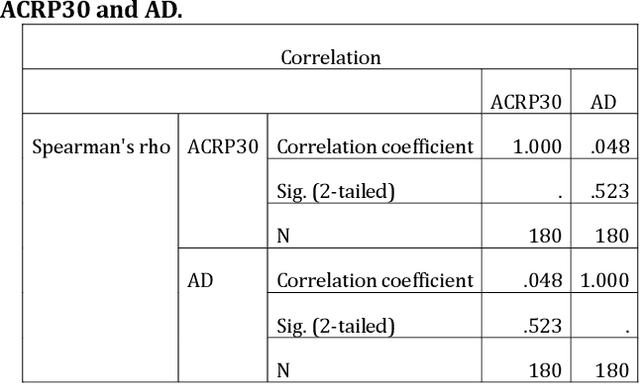
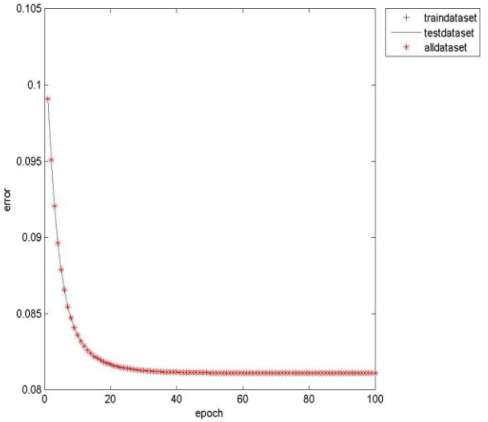
While a large body of research has formally identified apolipoprotein E (APOE) as a major genetic risk marker for Alzheimer disease, accumulating evidence supports the notion that other risk markers may exist. The traditional Alzheimer-specific signature analysis methods, however, have not been able to make full use of rich protein expression data, especially the interaction between attributes. This paper develops a novel feature selection method to identify pathogenic factors of Alzheimer disease using the proteomic and clinical data. This approach has taken the weights of network nodes as the importance order of signaling protein expression values. After generating and evaluating the candidate subset, the method helps to select an optimal subset of proteins that achieved an accuracy greater than 90%, which is superior to traditional machine learning methods for clinical Alzheimer disease diagnosis. Besides identifying a proteomic risk marker and further reinforce the link between metabolic risk factors and Alzheimer disease, this paper also suggests that apidonectin-linked pathways are a possible therapeutic drug target.
Deep ensemble learning for Alzheimers disease classification
May 30, 2019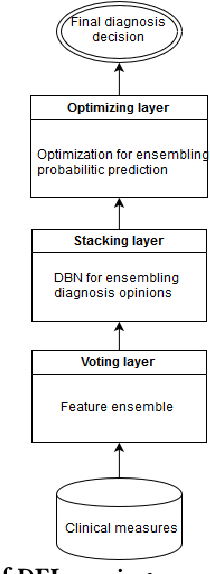

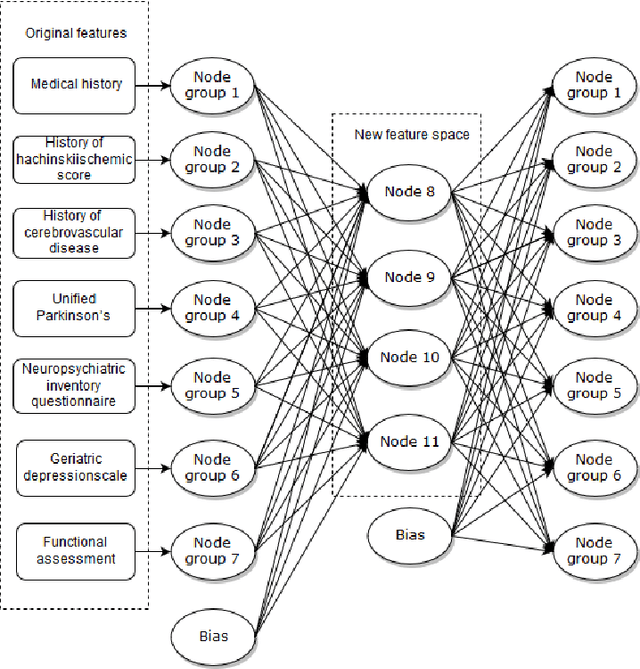

Ensemble learning use multiple algorithms to obtain better predictive performance than any single one of its constituent algorithms could. With growing popularity of deep learning, researchers have started to ensemble them for various purposes. Few if any, however, has used the deep learning approach as a means to ensemble algorithms. This paper presents a deep ensemble learning framework which aims to harness deep learning algorithms to integrate multisource data and tap the wisdom of experts. At the voting layer, a sparse autoencoder is trained for feature learning to reduce the correlation of attributes and diversify the base classifiers ultimately. At the stacking layer, a nonlinear feature-weighted method based on deep belief networks is proposed to rank the base classifiers which may violate the conditional independence. Neural network is used as meta classifier. At the optimizing layer, under-sampling and threshold-moving are used to cope with cost-sensitive problem. Optimized predictions are obtained based on ensemble of probabilistic predictions by similarity calculation. The proposed deep ensemble learning framework is used for Alzheimers disease classification. Experiments with the clinical dataset from national Alzheimers coordinating center demonstrate that the classification accuracy of our proposed framework is 4% better than 6 well-known ensemble approaches as well as the standard stacking algorithm. Adequate coverage of more accurate diagnostic services can be provided by utilizing the wisdom of averaged physicians. This paper points out a new way to boost the primary care of Alzheimers disease from the view of machine learning.