 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free ZS-CIR via Weighted Modality Fusion and Similarity
Sep 07, 2024Composed image retrieval (CIR), which formulates the query as a combination of a reference image and modified text, has emerged as a new form of image search due to its enhanced ability to capture users' intentions. However, training a CIR model in a supervised manner typically requires labor-intensive collection of (reference image, text modifier, target image) triplets. While existing zero-shot CIR (ZS-CIR) methods eliminate the need for training on specific downstream datasets, they still require additional pretraining with large-scale image-text pairs. In this paper, we introduce a training-free approach for ZS-CIR. Our approach, \textbf{Wei}ghted \textbf{Mo}dality fusion and similarity for \textbf{CIR} (WeiMoCIR), operates under the assumption that image and text modalities can be effectively combined using a simple weighted average. This allows the query representation to be constructed directly from the reference image and text modifier. To further enhance retrieval performance, we employ multimodal large language models (MLLMs) to generate image captions for the database images and incorporate these textual captions into the similarity computation by combining them with image information using a weighted average. Our approach is simple, easy to implement, and its effectiveness is validated through experiments on the FashionIQ and CIRR datasets.
Latent Feature Representation via Unsupervised Learning for Pattern Discovery in Massive Electron Microscopy Image Volumes
Dec 22, 2020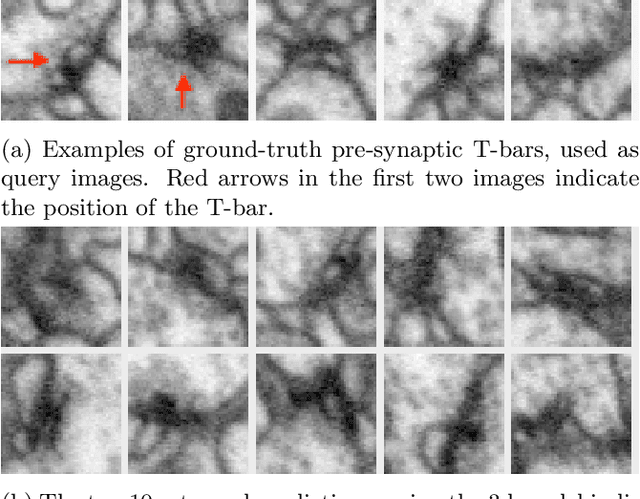
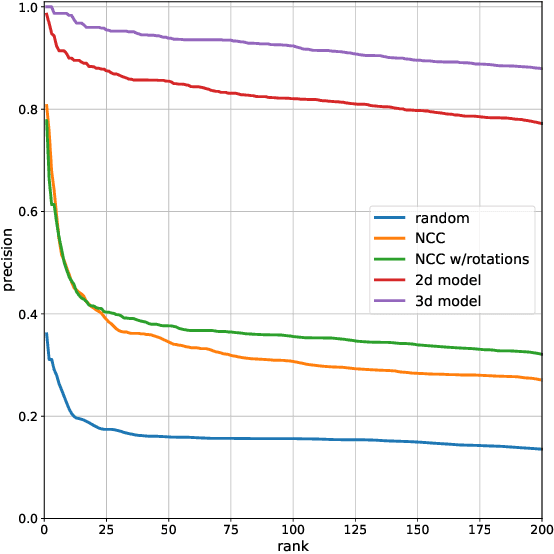

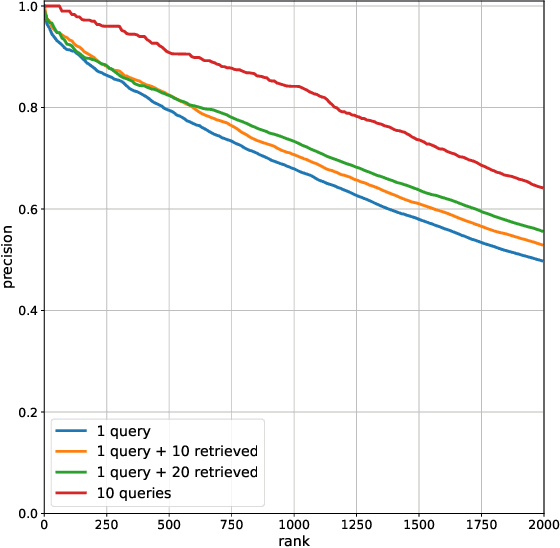
We propose a method to facilitate exploration and analysis of new large data sets. In particular, we give an unsupervised deep learning approach to learning a latent representation that captures semantic similarity in the data set. The core idea is to use data augmentations that preserve semantic meaning to generate synthetic examples of elements whose feature representations should be close to one another. We demonstrate the utility of our method applied to nano-scale electron microscopy data, where even relatively small portions of animal brains can require terabytes of image data. Although supervised methods can be used to predict and identify known patterns of interest, the scale of the data makes it difficult to mine and analyze patterns that are not known a priori. We show the ability of our learned representation to enable query by example, so that if a scientist notices an interesting pattern in the data, they can be presented with other locations with matching patterns. We also demonstrate that clustering of data in the learned space correlates with biologically-meaningful distinctions. Finally, we introduce a visualization tool and software ecosystem to facilitate user-friendly interactive analysis and uncover interesting biological patterns. In short, our work opens possible new avenues in understanding of and discovery in large data sets, arising in domains such as EM analysis.
Supervised Learning of Semantics-Preserving Hash via Deep Convolutional Neural Networks
Feb 14, 2017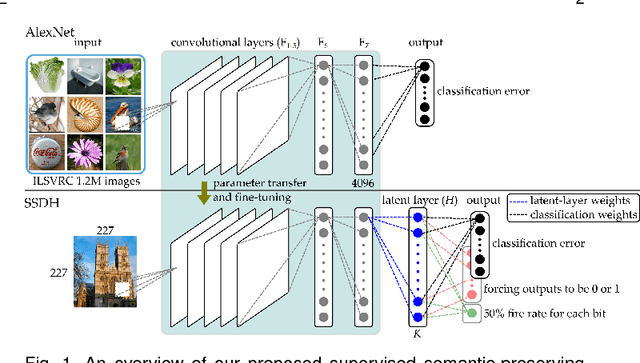
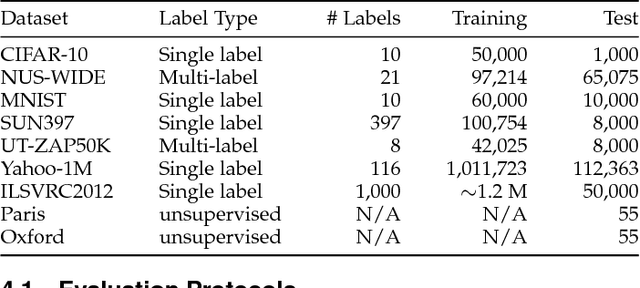
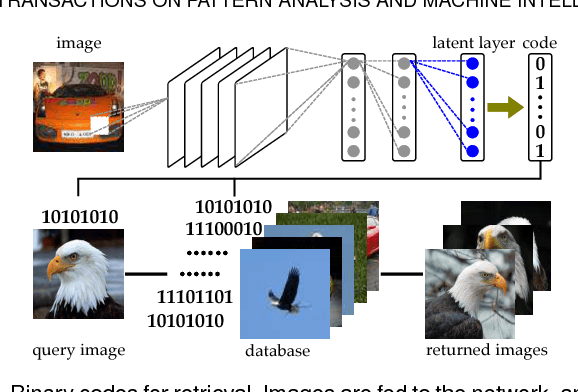

This paper presents a simple yet effective supervised deep hash approach that constructs binary hash codes from labeled data for large-scale image search. We assume that the semantic labels are governed by several latent attributes with each attribute on or off, and classification relies on these attributes. Based on this assumption, our approach, dubbed supervised semantics-preserving deep hashing (SSDH), constructs hash functions as a latent layer in a deep network and the binary codes are learned by minimizing an objective function defined over classification error and other desirable hash codes properties. With this design, SSDH has a nice characteristic that classification and retrieval are unified in a single learning model. Moreover, SSDH performs joint learning of image representations, hash codes, and classification in a point-wised manner, and thus is scalable to large-scale datasets. SSDH is simple and can be realized by a slight enhancement of an existing deep architecture for classification; yet it is effective and outperforms other hashing approaches on several benchmarks and large datasets. Compared with state-of-the-art approaches, SSDH achieves higher retrieval accuracy, while the classification performance is not sacrificed.