 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Semantic Differential for Cross-Cultural Concept Analysis: A Case Study of Human Affect
May 27, 2026Cross-cultural comparison of psychological meaning requires methods that go beyond word-level translation and examine how semantic dimensions are organized across languages. We introduce a cross-lingual extension of the Supervised Semantic Differential (SSD), which estimates supervised semantic gradients in embedding space and compares them across aligned multilingual word embeddings. The method tests gradient alignment and difference using permutation procedures and bootstrap intervals, and interprets residual differences through clustering around the difference gradient. We demonstrate the approach on Polish, English, and French affective norm lexicons, modeling Valence, Arousal, and Dominance where available. Affective dimensions were significantly recoverable across languages and model settings. Cross-lingual comparisons showed broad alignment together with structured residual differences: Valence appeared mostly shared, whereas Arousal and Dominance produced more interpretable contrasts involving bodily threat, aesthetic stimulation, internal emotionality, macro-level authority, and everyday control. Several clusters also reflected corpus-specific artifacts, underscoring the need for cautious interpretation. Cross-lingual SSD offers an explainable framework for testing semantic alignment, identifying divergence, and generating hypotheses about cross-cultural differences in psychological meaning.
Semantic Gradients Interactions in SSD: A Case Study in Racial Identity and Hate Speech
May 26, 2026We introduce interaction SSD, an extension of Supervised Semantic Differential that models how semantic meaning varies across moderators such as groups, traits, or conditions making this variation testable and interpretable. The method estimates a main semantic gradient, an interaction gradient, and conditional gradients, all interpretable through standard SSD tools. We illustrate it on the UC Berkeley Measuring Hate Speech corpus, testing whether annotator racial identity moderates hate-speech judgments of comments targeting people of color. The interaction model detects a significant moderation effect: the shared gradient contrasts dehumanizing hostility with counter-speech, while the interaction gradient reveals smaller group-linked differences in which semantic cues predict hate-speech ratings. Interaction SSD makes moderated meaning-outcome relationships statistically testable and interpretable.
Psychological Constructs in Shared Semantic Space
May 26, 2026Psychological constructs are often measured in separate instruments, datasets, and research traditions, which makes direct comparison difficult. This paper proposes a framework for making such constructs semantically commensurate by representing and comparing them as directions in a shared word-embedding space. Using Supervised Semantic Differential, we estimate construct-specific semantic gradients from text-outcome associations and project them onto theoretically motivated reference axes. As an initial test case, we use Valence, Arousal, and Dominance (VAD) as an affective coordinate system. First, we recover interpretable VAD directions from English word-level affective norms. Second, we project semantic gradients for 27 GoEmotions categories into this space and recover the expected organization of emotions, especially along valence and arousal. Third, we apply the same procedure to Big Five personality domains and facets derived from IPIP-NEO-300 item-factor associations. Domain-level placements are broadly coherent, while facet-level results are more exploratory because they rely on sparse questionnaire text. The results suggest that embedding spaces can support construct-level comparison across otherwise incommensurable psychological measurements, provided that semantic placements are assessed for stability and interpretability.
The Pinocchio Dimension: Phenomenality of Experience as the Primary Axis of LLM Psychometric Differences
May 06, 2026We administer 45 validated psychometric questionnaires to 50 large language models (LLMs) to identify the dimensions along which LLMs differ psychometrically. Using Supervised Semantic Differential (SSD), we find that the primary axis of between-model variance separates items describing phenomenally rich experience, including embodied sensation, felt affect, inner speech, imagery, and empathy, from items describing stimulus-driven behavioral reactivity ($R^2_{adj}=.037$, $p<.0001$). To test this hypothesis at the item level, we introduce the Pinocchio score ($π_i$), the ratio of inter-model response variance under neutral prompting to that under a human-simulation prompt, as an annotation-free measure of each item's experiential demand. $π_i$ predicts condition-induced shifts in primary factor loading magnitudes ($ρ=-.215$, $p<.0001$, $n=1292$--$1310$ items), confirming that between-model divergence on experiential items is structured rather than noisy. Applying PCA to per-model EFA scores across all questionnaires reveals one dominant dimension, the Pinocchio Axis ($Π$): the degree to which a model presents itself as a locus of phenomenal experience rather than a system of behavioral responses. This axis captures 47.1% of cross-questionnaire between-model variance in primary factor scores and converges with item-level Pinocchio scores ($r=.864$). Marked within-provider divergence across closely related model variants is consistent with post-training fine-tuning as a key contributor, supporting the interpretation that $Π$ reflects a training-shaped self-representational tendency governing how a model treats experiential language as self-applicable. The dominant axis of between-model psychometric variation is therefore not a conventional personality trait but a self-representational stance toward one's own nature as an experiencer.
Interpretable Semantic Gradients in SSD: A PCA Sweep Approach and a Case Study on AI Discourse
Mar 13, 2026Supervised Semantic Differential (SSD) is a mixed quantitative-interpretive method that models how text meaning varies with continuous individual-difference variables by estimating a semantic gradient in an embedding space and interpreting its poles through clustering and text retrieval. SSD applies PCA before regression, but currently no systematic method exists for choosing the number of retained components, introducing avoidable researcher degrees of freedom in the analysis pipeline. We propose a PCA sweep procedure that treats dimensionality selection as a joint criterion over representation capacity, gradient interpretability, and stability across nearby values of K. We illustrate the method on a corpus of short posts about artificial intelligence written by Prolific participants who also completed Admiration and Rivalry narcissism scales. The sweep yields a stable, interpretable Admiration-related gradient contrasting optimistic, collaborative framings of AI with distrustful and derisive discourse, while no robust alignment emerges for Rivalry. We also show that a counterfactual using a high-PCA dimension solution heuristic produces diffuse, weakly structured clusters instead, reinforcing the value of the sweep-based choice of K. The case study shows how the PCA sweep constrains researcher degrees of freedom while preserving SSD's interpretive aims, supporting transparent and psychologically meaningful analyses of connotative meaning.
The Prediction-Measurement Gap: Toward Meaning Representations as Scientific Instruments
Mar 10, 2026Text embeddings have become central to computational social science and psychology, enabling scalable measurement of meaning and mixed-method inference. Yet most representation learning is optimized and evaluated for prediction and retrieval, yielding a prediction-measurement gap: representations that perform well as features may be poorly suited as scientific instruments. The paper argues that scientific meaning analysis motivates a distinct family of objectives - scientific usability - emphasizing geometric legibility, interpretability and traceability to linguistic evidence, robustness to non-semantic confounds, and compatibility with regression-style inference over semantic directions. Grounded in cognitive and neuro-psychological views of meaning, the paper assesses static word embeddings and contextual transformer representations against these requirements: static spaces remain attractive for transparent measurement, whereas contextual spaces offer richer semantics but entangle meaning with other signals and exhibit geometric and interpretability issues that complicate inference. The paper then outlines a course-setting agenda around (i) geometry-first design for gradients and abstraction, including hierarchy-aware spaces constrained by psychologically privileged levels; (ii) invertible post-hoc transformations that recondition embedding geometry and reduce nuisance influence; and (iii) meaning atlases and measurement-oriented evaluation protocols for reliable and traceable semantic inference. As the field debates the limits of scale-first progress, measurement-ready representations offer a principled new frontier.
Bias-Free Sentiment Analysis through Semantic Blinding and Graph Neural Networks
Nov 24, 2024



This paper introduces the Semantic Propagation Graph Neural Network (SProp GNN), a machine learning sentiment analysis (SA) architecture that relies exclusively on syntactic structures and word-level emotional cues to predict emotions in text. By semantically blinding the model to information about specific words, it is robust to biases such as political or gender bias that have been plaguing previous machine learning-based SA systems. The SProp GNN shows performance superior to lexicon-based alternatives such as VADER and EmoAtlas on two different prediction tasks, and across two languages. Additionally, it approaches the accuracy of transformer-based models while significantly reducing bias in emotion prediction tasks. By offering improved explainability and reducing bias, the SProp GNN bridges the methodological gap between interpretable lexicon approaches and powerful, yet often opaque, deep learning models, offering a robust tool for fair and effective emotion analysis in understanding human behavior through text.
Bias Free Sentiment Analysis
Nov 19, 2024This paper introduces the Semantic Propagation Graph Neural Network (SProp GNN), a machine learning sentiment analysis (SA) architecture that relies exclusively on syntactic structures and word-level emotional cues to predict emotions in text. By semantically blinding the model to information about specific words, it is robust to biases such as political or gender bias that have been plaguing previous machine learning-based SA systems. The SProp GNN shows performance superior to lexicon-based alternatives such as VADER and EmoAtlas on two different prediction tasks, and across two languages. Additionally, it approaches the accuracy of transformer-based models while significantly reducing bias in emotion prediction tasks. By offering improved explainability and reducing bias, the SProp GNN bridges the methodological gap between interpretable lexicon approaches and powerful, yet often opaque, deep learning models, offering a robust tool for fair and effective emotion analysis in understanding human behavior through text.
Uncovering Political Bias in Emotion Inference Models: Implications for sentiment analysis in social science research
Jul 18, 2024This paper investigates the presence of political bias in emotion inference models used for sentiment analysis (SA) in social science research. Machine learning models often reflect biases in their training data, impacting the validity of their outcomes. While previous research has highlighted gender and race biases, our study focuses on political bias - an underexplored yet pervasive issue that can skew the interpretation of text data across a wide array of studies. We conducted a bias audit on a Polish sentiment analysis model developed in our lab. By analyzing valence predictions for names and sentences involving Polish politicians, we uncovered systematic differences influenced by political affiliations. Our findings indicate that annotations by human raters propagate political biases into the model's predictions. To mitigate this, we pruned the training dataset of texts mentioning these politicians and observed a reduction in bias, though not its complete elimination. Given the significant implications of political bias in SA, our study emphasizes caution in employing these models for social science research. We recommend a critical examination of SA results and propose using lexicon-based systems as a more ideologically neutral alternative. This paper underscores the necessity for ongoing scrutiny and methodological adjustments to ensure the reliability and impartiality of the use of machine learning in academic and applied contexts.
Predicting Emotion Intensity in Polish Political Texts: Comparing Supervised Models and Large Language Models in a Resource-Poor Language
Jul 16, 2024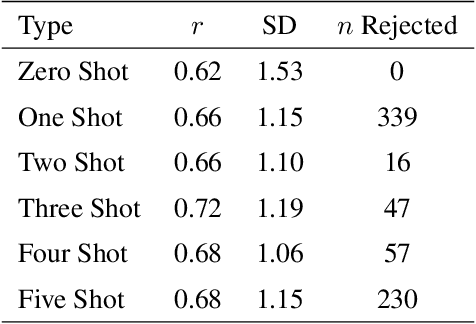
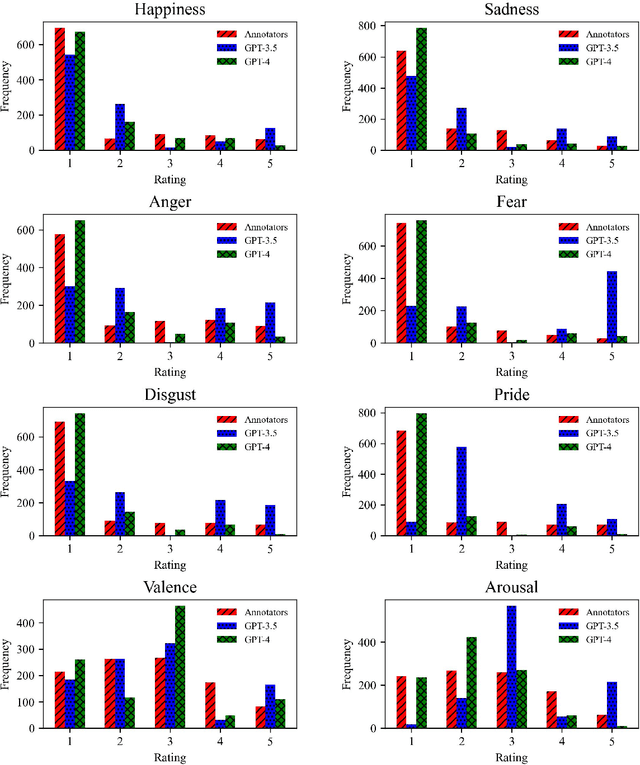
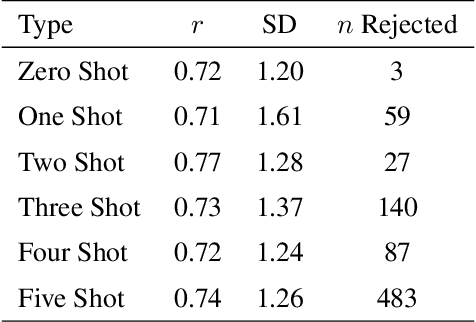
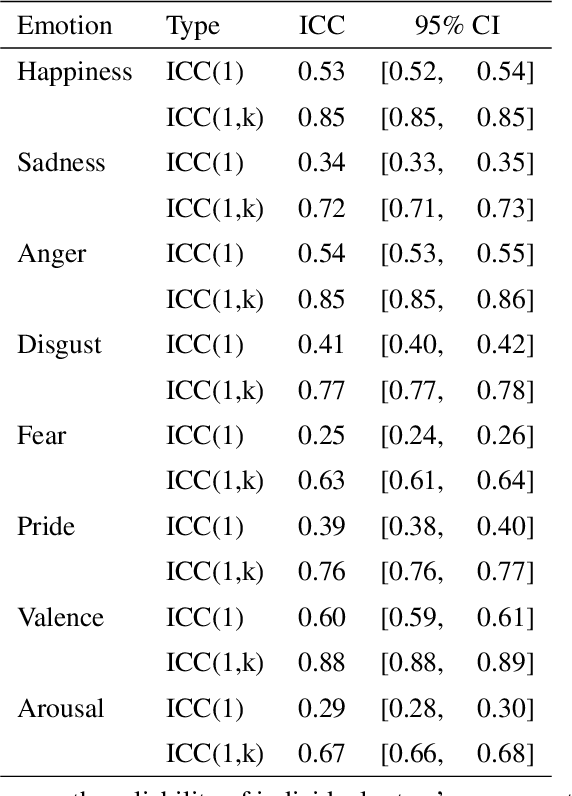
This study explores the use of large language models (LLMs) to predict emotion intensity in Polish political texts, a resource-poor language context. The research compares the performance of several LLMs against a supervised model trained on an annotated corpus of 10,000 social media texts, evaluated for the intensity of emotions by expert judges. The findings indicate that while the supervised model generally outperforms LLMs, offering higher accuracy and lower variance, LLMs present a viable alternative, especially given the high costs associated with data annotation. The study highlights the potential of LLMs in low-resource language settings and underscores the need for further research on emotion intensity prediction and its application across different languages and continuous features. The implications suggest a nuanced decision-making process to choose the right approach to emotion prediction for researchers and practitioners based on resource availability and the specific requirements of their tasks.