 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Political Bias in Emotion Inference Models: Implications for sentiment analysis in social science research
Jul 18, 2024This paper investigates the presence of political bias in emotion inference models used for sentiment analysis (SA) in social science research. Machine learning models often reflect biases in their training data, impacting the validity of their outcomes. While previous research has highlighted gender and race biases, our study focuses on political bias - an underexplored yet pervasive issue that can skew the interpretation of text data across a wide array of studies. We conducted a bias audit on a Polish sentiment analysis model developed in our lab. By analyzing valence predictions for names and sentences involving Polish politicians, we uncovered systematic differences influenced by political affiliations. Our findings indicate that annotations by human raters propagate political biases into the model's predictions. To mitigate this, we pruned the training dataset of texts mentioning these politicians and observed a reduction in bias, though not its complete elimination. Given the significant implications of political bias in SA, our study emphasizes caution in employing these models for social science research. We recommend a critical examination of SA results and propose using lexicon-based systems as a more ideologically neutral alternative. This paper underscores the necessity for ongoing scrutiny and methodological adjustments to ensure the reliability and impartiality of the use of machine learning in academic and applied contexts.
Predicting Emotion Intensity in Polish Political Texts: Comparing Supervised Models and Large Language Models in a Resource-Poor Language
Jul 16, 2024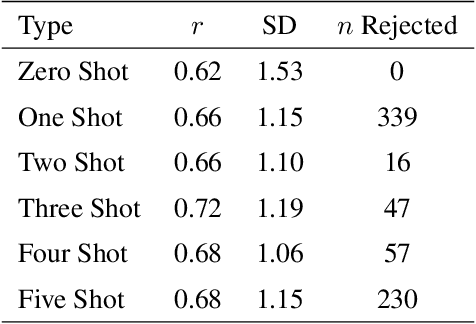
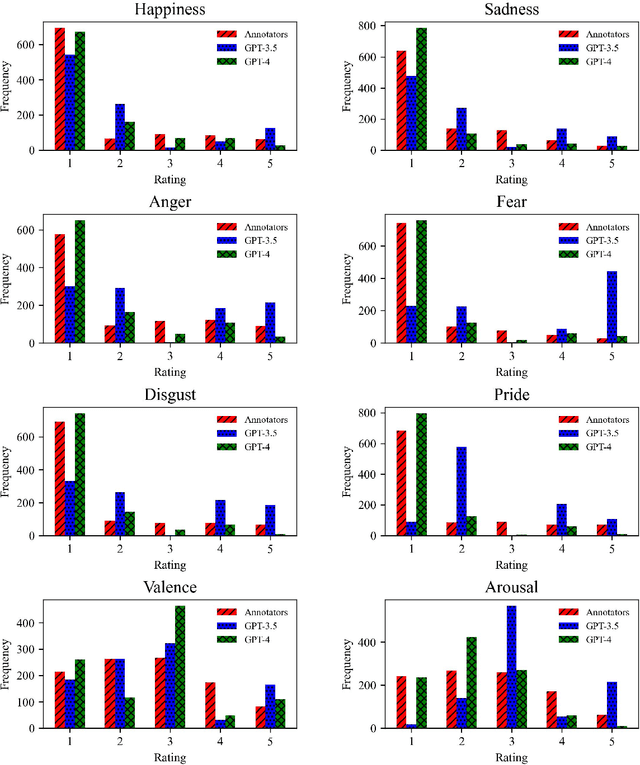
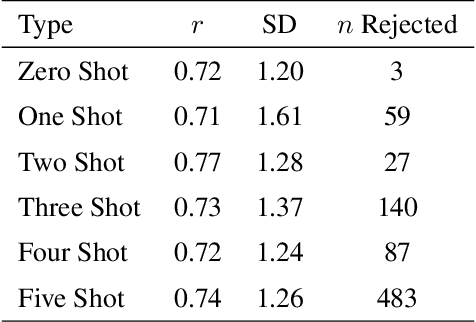
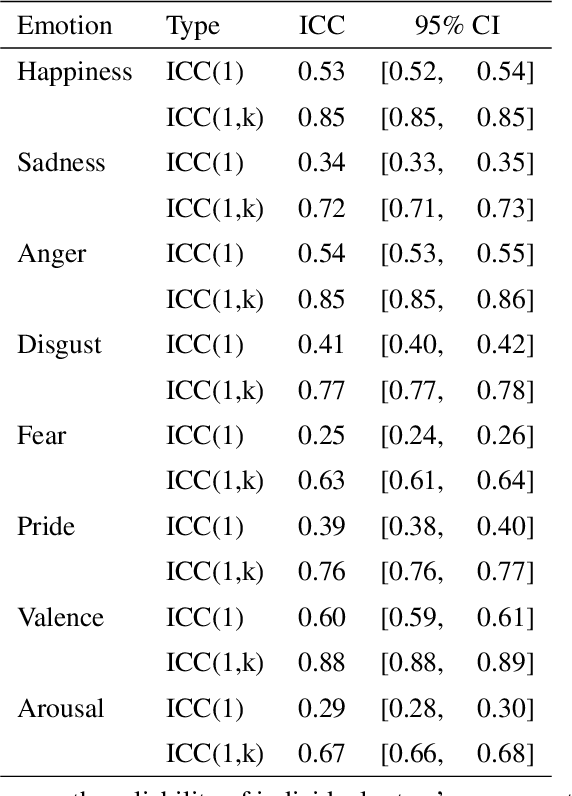
This study explores the use of large language models (LLMs) to predict emotion intensity in Polish political texts, a resource-poor language context. The research compares the performance of several LLMs against a supervised model trained on an annotated corpus of 10,000 social media texts, evaluated for the intensity of emotions by expert judges. The findings indicate that while the supervised model generally outperforms LLMs, offering higher accuracy and lower variance, LLMs present a viable alternative, especially given the high costs associated with data annotation. The study highlights the potential of LLMs in low-resource language settings and underscores the need for further research on emotion intensity prediction and its application across different languages and continuous features. The implications suggest a nuanced decision-making process to choose the right approach to emotion prediction for researchers and practitioners based on resource availability and the specific requirements of their tasks.