 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Emotion Intensity in Polish Political Texts: Comparing Supervised Models and Large Language Models in a Resource-Poor Language
Paper and Code
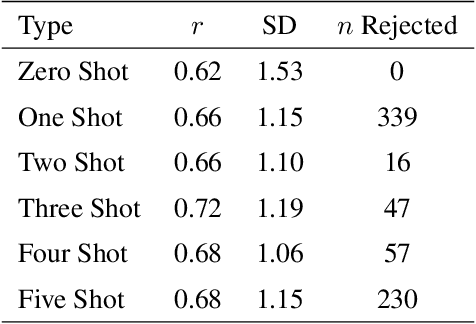
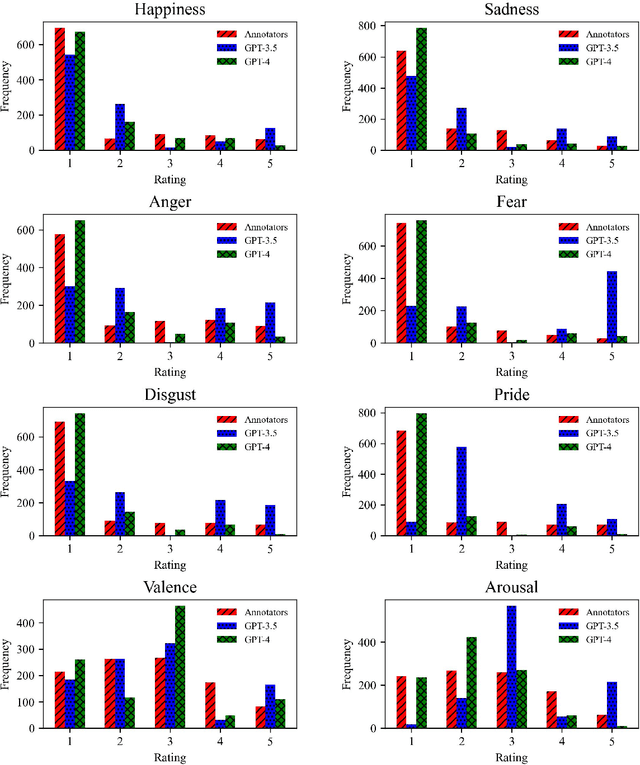
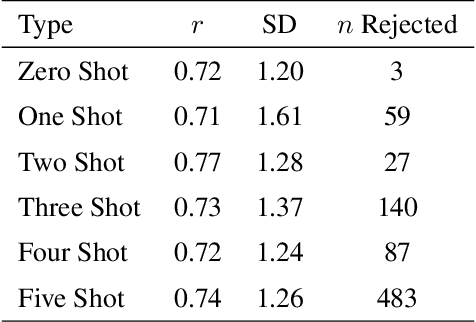
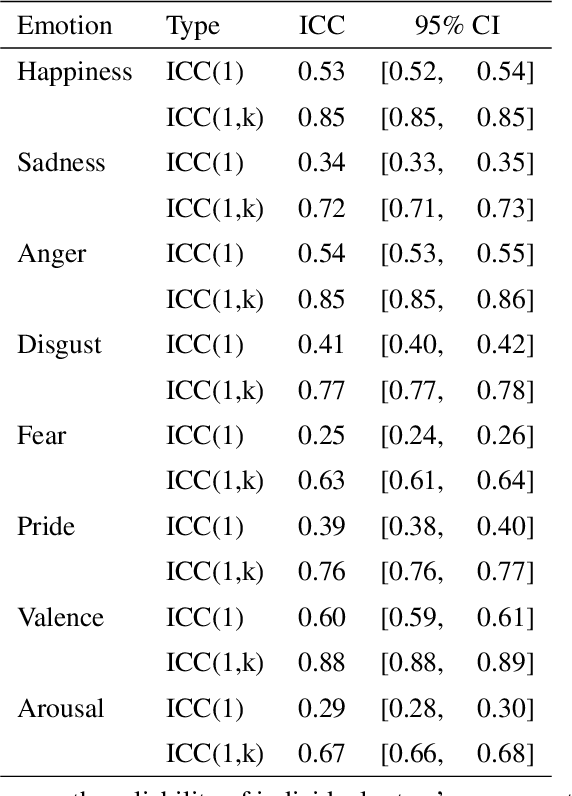
This study explores the use of large language models (LLMs) to predict emotion intensity in Polish political texts, a resource-poor language context. The research compares the performance of several LLMs against a supervised model trained on an annotated corpus of 10,000 social media texts, evaluated for the intensity of emotions by expert judges. The findings indicate that while the supervised model generally outperforms LLMs, offering higher accuracy and lower variance, LLMs present a viable alternative, especially given the high costs associated with data annotation. The study highlights the potential of LLMs in low-resource language settings and underscores the need for further research on emotion intensity prediction and its application across different languages and continuous features. The implications suggest a nuanced decision-making process to choose the right approach to emotion prediction for researchers and practitioners based on resource availability and the specific requirements of their tasks.