 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Fast Decoding of High-Capacity Color QR Codes for Mobile Applications
May 19, 2018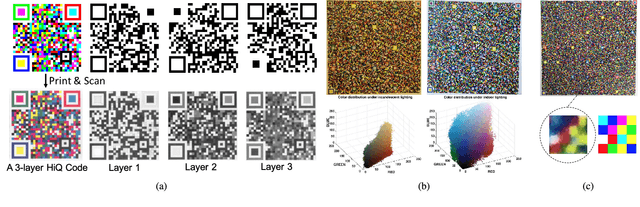
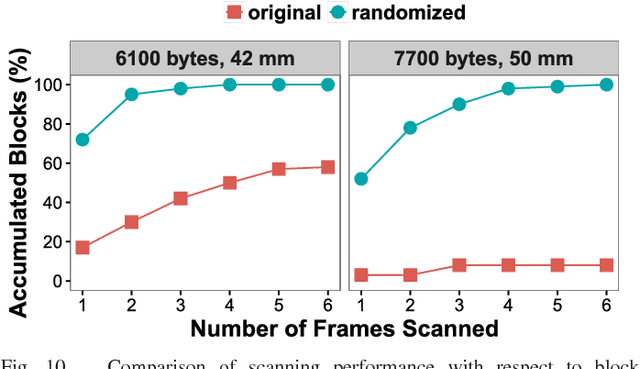
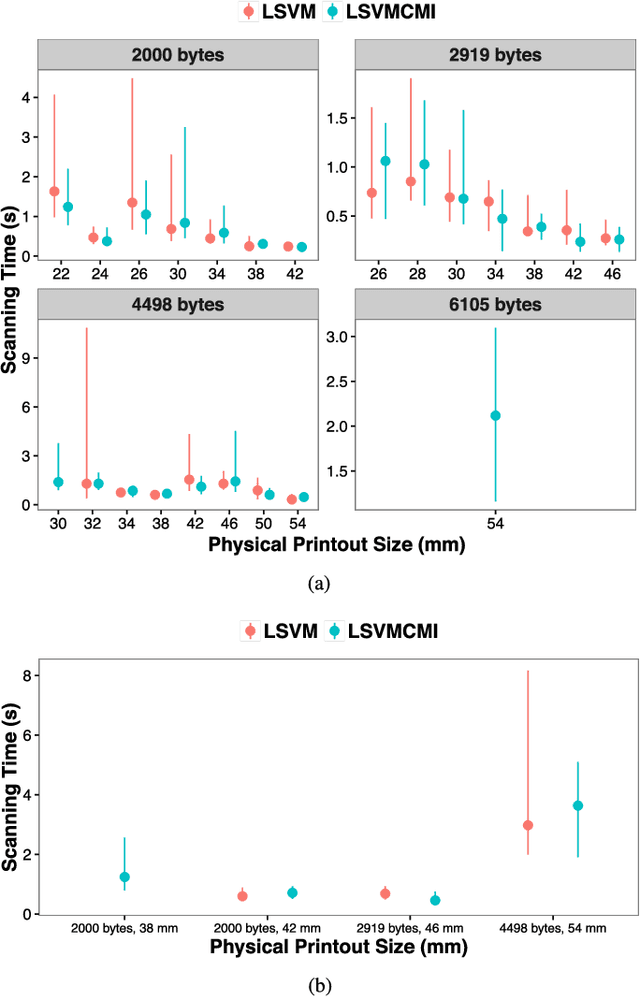

The use of color in QR codes brings extra data capacity, but also inflicts tremendous challenges on the decoding process due to chromatic distortion, cross-channel color interference and illumination variation. Particularly, we further discover a new type of chromatic distortion in high-density color QR codes, cross-module color interference, caused by the high density which also makes the geometric distortion correction more challenging. To address these problems, we propose two approaches, namely, LSVM-CMI and QDA-CMI, which jointly model these different types of chromatic distortion. Extended from SVM and QDA, respectively, both LSVM-CMI and QDA-CMI optimize over a particular objective function to learn a color classifier. Furthermore, a robust geometric transformation method and several pipeline refinements are proposed to boost the decoding performance for mobile applications. We put forth and implement a framework for high-capacity color QR codes equipped with our methods, called HiQ. To evaluate the performance of HiQ, we collect a challenging large-scale color QR code dataset, CUHK-CQRC, which consists of 5390 high-density color QR code samples. The comparison with the baseline method [2] on CUHK-CQRC shows that HiQ at least outperforms [2] by 188% in decoding success rate and 60% in bit error rate. Our implementation of HiQ in iOS and Android also demonstrates the effectiveness of our framework in real-world applications.
Similar Handwritten Chinese Character Discrimination by Weakly Supervised Learning
Sep 19, 2015
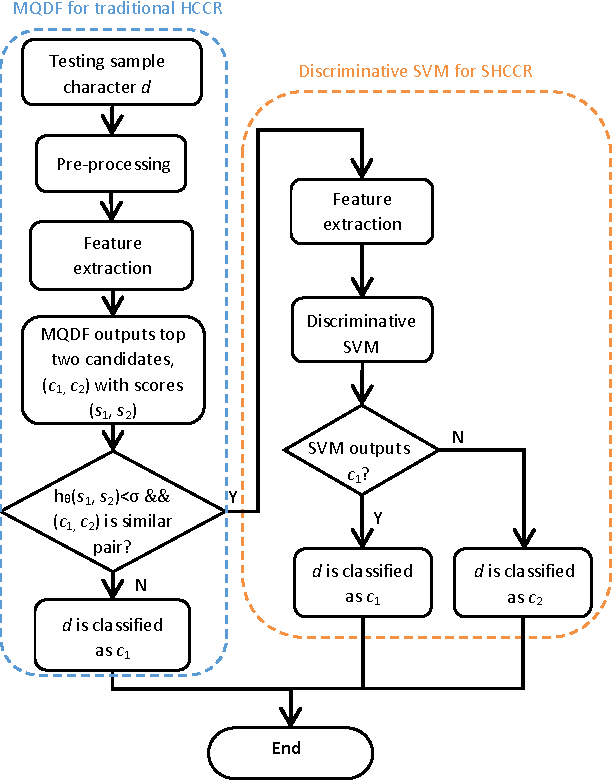
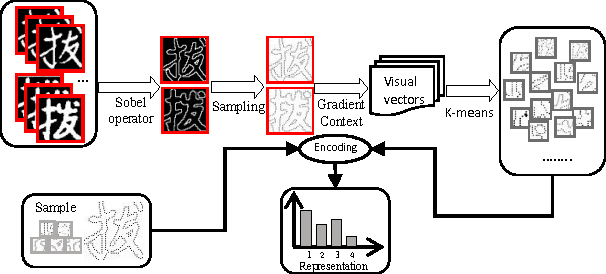

Traditional approaches for handwritten Chinese character recognition suffer in classifying similar characters. In this paper, we propose to discriminate similar handwritten Chinese characters by using weakly supervised learning. Our approach learns a discriminative SVM for each similar pair which simultaneously localizes the discriminative region of similar character and makes the classification. For the first time, similar handwritten Chinese character recognition (SHCCR) is formulated as an optimization problem extended from SVM. We also propose a novel feature descriptor, Gradient Context, and apply bag-of-words model to represent regions with different scales. In our method, we do not need to select a sized-fixed sub-window to differentiate similar characters. The unconstrained property makes our method well adapted to high variance in the size and position of discriminative regions in similar handwritten Chinese characters. We evaluate our proposed approach over the CASIA Chinese character data set and the results show that our method outperforms the state of the art.