 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachines acquire scientific taste from institutional traces
Mar 17, 2026Artificial intelligence matches or exceeds human performance on tasks with verifiable answers, from protein folding to Olympiad mathematics. Yet the capacity that most governs scientific advance is not reasoning but taste: the ability to judge which untested ideas deserve pursuit, exercised daily by editors and funders but never successfully articulated, taught, or automated. Here we show that fine-tuning language models on journal publication decisions recovers evaluative judgment inaccessible to both frontier models and human expertise. Using a held-out benchmark of research pitches in management spanning four quality tiers, we find that eleven frontier models, spanning major proprietary and open architectures, barely exceed chance, averaging 31% accuracy. Panels of journal editors and editorial board members reach 42% by majority vote. Fine-tuned models trained on years of publication records each surpass every frontier model and expert panel, with the best single model achieving 59%. These models exhibit calibrated confidence, reaching 100% accuracy on their highest-confidence predictions, and transfer this evaluative signal to untrained pairwise comparisons and one-sentence summaries. The mechanism generalizes: models trained on economics publication records achieve 70% accuracy. Scientific taste was not missing from AI's reach; it was deposited in the institutional record, waiting to be extracted. These results provide a scalable mechanism to triage the expanding volume of scientific production across disciplines where quality resists formal verification.
Can AI Replace Human Subjects? A Large-Scale Replication of Psychological Experiments with LLMs
Sep 04, 2024

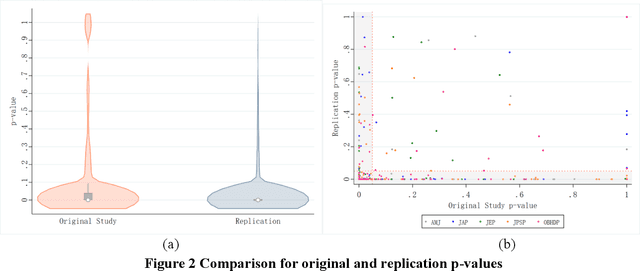

Artificial Intelligence (AI) is increasingly being integrated into scientific research, particularly in the social sciences, where understanding human behavior is critical. Large Language Models (LLMs) like GPT-4 have shown promise in replicating human-like responses in various psychological experiments. However, the extent to which LLMs can effectively replace human subjects across diverse experimental contexts remains unclear. Here, we conduct a large-scale study replicating 154 psychological experiments from top social science journals with 618 main effects and 138 interaction effects using GPT-4 as a simulated participant. We find that GPT-4 successfully replicates 76.0 percent of main effects and 47.0 percent of interaction effects observed in the original studies, closely mirroring human responses in both direction and significance. However, only 19.44 percent of GPT-4's replicated confidence intervals contain the original effect sizes, with the majority of replicated effect sizes exceeding the 95 percent confidence interval of the original studies. Additionally, there is a 71.6 percent rate of unexpected significant results where the original studies reported null findings, suggesting potential overestimation or false positives. Our results demonstrate the potential of LLMs as powerful tools in psychological research but also emphasize the need for caution in interpreting AI-driven findings. While LLMs can complement human studies, they cannot yet fully replace the nuanced insights provided by human subjects.
From Text to Insight: Leveraging Large Language Models for Performance Evaluation in Management
Aug 09, 2024This study explores the potential of Large Language Models (LLMs), specifically GPT-4, to enhance objectivity in organizational task performance evaluations. Through comparative analyses across two studies, including various task performance outputs, we demonstrate that LLMs can serve as a reliable and even superior alternative to human raters in evaluating knowledge-based performance outputs, which are a key contribution of knowledge workers. Our results suggest that GPT ratings are comparable to human ratings but exhibit higher consistency and reliability. Additionally, combined multiple GPT ratings on the same performance output show strong correlations with aggregated human performance ratings, akin to the consensus principle observed in performance evaluation literature. However, we also find that LLMs are prone to contextual biases, such as the halo effect, mirroring human evaluative biases. Our research suggests that while LLMs are capable of extracting meaningful constructs from text-based data, their scope is currently limited to specific forms of performance evaluation. By highlighting both the potential and limitations of LLMs, our study contributes to the discourse on AI role in management studies and sets a foundation for future research to refine AI theoretical and practical applications in management.
Generative AI Enhances Team Performance and Reduces Need for Traditional Teams
May 28, 2024Recent advancements in generative artificial intelligence (AI) have transformed collaborative work processes, yet the impact on team performance remains underexplored. Here we examine the role of generative AI in enhancing or replacing traditional team dynamics using a randomized controlled experiment with 435 participants across 122 teams. We show that teams augmented with generative AI significantly outperformed those relying solely on human collaboration across various performance measures. Interestingly, teams with multiple AIs did not exhibit further gains, indicating diminishing returns with increased AI integration. Our analysis suggests that centralized AI usage by a few team members is more effective than distributed engagement. Additionally, individual-AI pairs matched the performance of conventional teams, suggesting a reduced need for traditional team structures in some contexts. However, despite this capability, individual-AI pairs still fell short of the performance levels achieved by AI-assisted teams. These findings underscore that while generative AI can replace some traditional team functions, more comprehensively integrating AI within team structures provides superior benefits, enhancing overall effectiveness beyond individual efforts.