 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan AI Replace Human Subjects? A Large-Scale Replication of Psychological Experiments with LLMs
Paper and Code
Sep 04, 2024

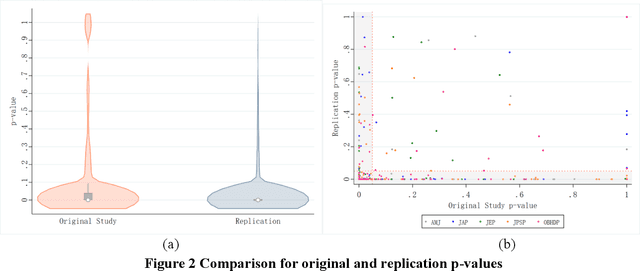

Artificial Intelligence (AI) is increasingly being integrated into scientific research, particularly in the social sciences, where understanding human behavior is critical. Large Language Models (LLMs) like GPT-4 have shown promise in replicating human-like responses in various psychological experiments. However, the extent to which LLMs can effectively replace human subjects across diverse experimental contexts remains unclear. Here, we conduct a large-scale study replicating 154 psychological experiments from top social science journals with 618 main effects and 138 interaction effects using GPT-4 as a simulated participant. We find that GPT-4 successfully replicates 76.0 percent of main effects and 47.0 percent of interaction effects observed in the original studies, closely mirroring human responses in both direction and significance. However, only 19.44 percent of GPT-4's replicated confidence intervals contain the original effect sizes, with the majority of replicated effect sizes exceeding the 95 percent confidence interval of the original studies. Additionally, there is a 71.6 percent rate of unexpected significant results where the original studies reported null findings, suggesting potential overestimation or false positives. Our results demonstrate the potential of LLMs as powerful tools in psychological research but also emphasize the need for caution in interpreting AI-driven findings. While LLMs can complement human studies, they cannot yet fully replace the nuanced insights provided by human subjects.