 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representations for Clustering via Partial Information Discrimination and Cross-Level Interaction
Jan 24, 2024In this paper, we present a novel deep image clustering approach termed PICI, which enforces the partial information discrimination and the cross-level interaction in a joint learning framework. In particular, we leverage a Transformer encoder as the backbone, through which the masked image modeling with two paralleled augmented views is formulated. After deriving the class tokens from the masked images by the Transformer encoder, three partial information learning modules are further incorporated, including the PISD module for training the auto-encoder via masked image reconstruction, the PICD module for employing two levels of contrastive learning, and the CLI module for mutual interaction between the instance-level and cluster-level subspaces. Extensive experiments have been conducted on six real-world image datasets, which demononstrate the superior clustering performance of the proposed PICI approach over the state-of-the-art deep clustering approaches. The source code is available at https://github.com/Regan-Zhang/PICI.
Vision Transformer for Contrastive Clustering
Jun 26, 2022


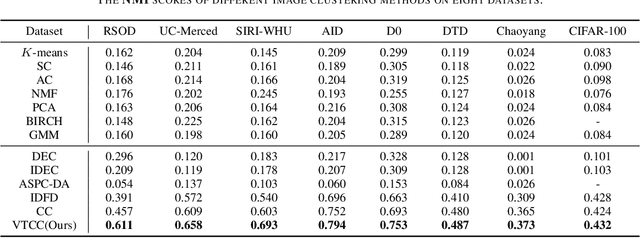
Vision Transformer (ViT) has shown its advantages over the convolutional neural network (CNN) with its ability to capture global long-range dependencies for visual representation learning. Besides ViT, contrastive learning is another popular research topic recently. While previous contrastive learning works are mostly based on CNNs, some latest studies have attempted to jointly model the ViT and the contrastive learning for enhanced self-supervised learning. Despite the considerable progress, these combinations of ViT and contrastive learning mostly focus on the instance-level contrastiveness, which often overlook the contrastiveness of the global clustering structures and also lack the ability to directly learn the clustering result (e.g., for images). In view of this, this paper presents an end-to-end deep image clustering approach termed Vision Transformer for Contrastive Clustering (VTCC), which for the first time, to the best of our knowledge, unifies the Transformer and the contrastive learning for the image clustering task. Specifically, with two random augmentations performed on each image in a mini-batch, we utilize a ViT encoder with two weight-sharing views as the backbone to learn the representations for the augmented samples. To remedy the potential instability of the ViT, we incorporate a convolutional stem, which uses multiple stacked small convolutions instead of a big convolution in the patch projection layer, to split each augmented sample into a sequence of patches. With representations learned via the backbone, an instance projector and a cluster projector are further utilized for the instance-level contrastive learning and the global clustering structure learning, respectively. Extensive experiments on eight image datasets demonstrate the stability (during the training-from-scratch) and the superiority (in clustering performance) of VTCC over the state-of-the-art.