 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformer for Contrastive Clustering
Jun 26, 2022


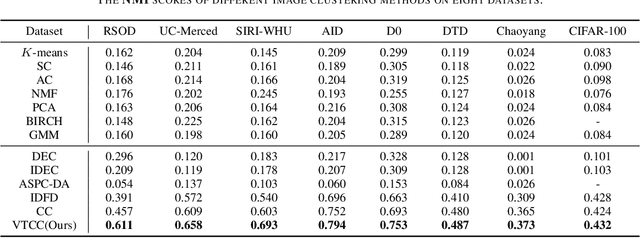
Vision Transformer (ViT) has shown its advantages over the convolutional neural network (CNN) with its ability to capture global long-range dependencies for visual representation learning. Besides ViT, contrastive learning is another popular research topic recently. While previous contrastive learning works are mostly based on CNNs, some latest studies have attempted to jointly model the ViT and the contrastive learning for enhanced self-supervised learning. Despite the considerable progress, these combinations of ViT and contrastive learning mostly focus on the instance-level contrastiveness, which often overlook the contrastiveness of the global clustering structures and also lack the ability to directly learn the clustering result (e.g., for images). In view of this, this paper presents an end-to-end deep image clustering approach termed Vision Transformer for Contrastive Clustering (VTCC), which for the first time, to the best of our knowledge, unifies the Transformer and the contrastive learning for the image clustering task. Specifically, with two random augmentations performed on each image in a mini-batch, we utilize a ViT encoder with two weight-sharing views as the backbone to learn the representations for the augmented samples. To remedy the potential instability of the ViT, we incorporate a convolutional stem, which uses multiple stacked small convolutions instead of a big convolution in the patch projection layer, to split each augmented sample into a sequence of patches. With representations learned via the backbone, an instance projector and a cluster projector are further utilized for the instance-level contrastive learning and the global clustering structure learning, respectively. Extensive experiments on eight image datasets demonstrate the stability (during the training-from-scratch) and the superiority (in clustering performance) of VTCC over the state-of-the-art.
Strongly Augmented Contrastive Clustering
Jun 01, 2022


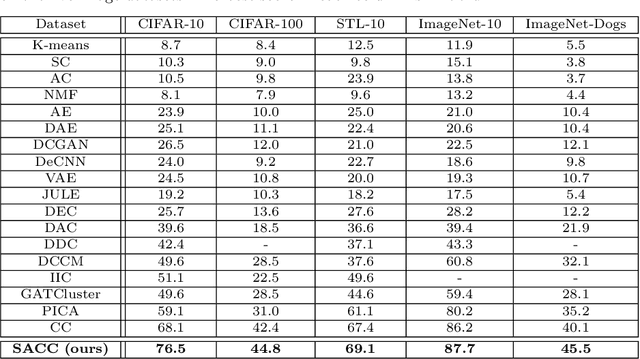
Deep clustering has attracted increasing attention in recent years due to its capability of joint representation learning and clustering via deep neural networks. In its latest developments, the contrastive learning has emerged as an effective technique to substantially enhance the deep clustering performance. However, the existing contrastive learning based deep clustering algorithms mostly focus on some carefully-designed augmentations (often with limited transformations to preserve the structure), referred to as weak augmentations, but cannot go beyond the weak augmentations to explore the more opportunities in stronger augmentations (with more aggressive transformations or even severe distortions). In this paper, we present an end-to-end deep clustering approach termed strongly augmented contrastive clustering (SACC), which extends the conventional two-augmentation-view paradigm to multiple views and jointly leverages strong and weak augmentations for strengthened deep clustering. Particularly, we utilize a backbone network with triply-shared weights, where a strongly augmented view and two weakly augmented views are incorporated. Based on the representations produced by the backbone, the weak-weak view pair and the strong-weak view pairs are simultaneously exploited for the instance-level contrastive learning (via an instance projector) and the cluster-level contrastive learning (via a cluster projector), which, together with the backbone, can be jointly optimized in a purely unsupervised manner. Experimental results on five challenging image datasets have shown the superior performance of the proposed SACC approach over the state-of-the-art.
DeepCluE: Enhanced Image Clustering via Multi-layer Ensembles in Deep Neural Networks
Jun 01, 2022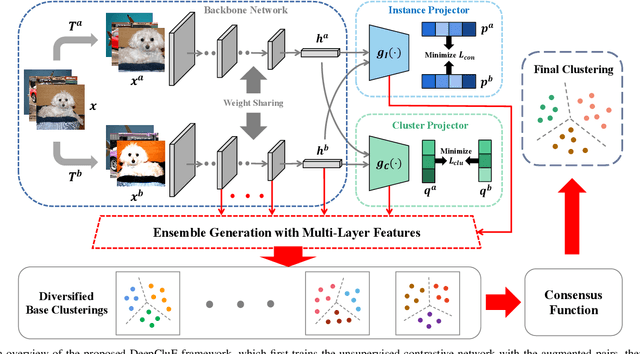


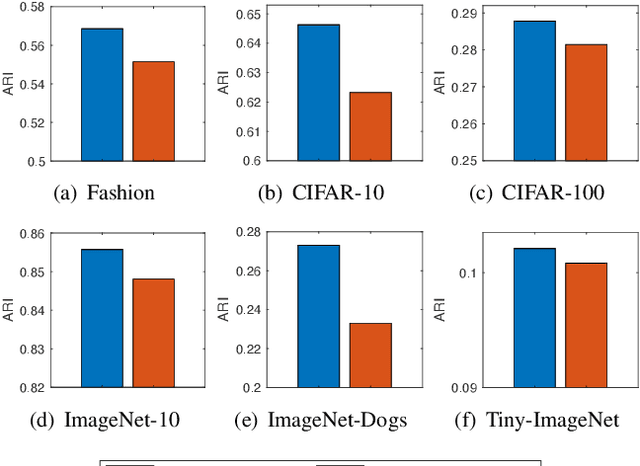
Deep clustering has recently emerged as a promising technique for complex image clustering. Despite the significant progress, previous deep clustering works mostly tend to construct the final clustering by utilizing a single layer of representation, e.g., by performing $K$-means on the last fully-connected layer or by associating some clustering loss to a specific layer. However, few of them have considered the possibilities and potential benefits of jointly leveraging multi-layer representations for enhancing the deep clustering performance. In light of this, this paper presents a Deep Clustering via Ensembles (DeepCluE) approach, which bridges the gap between deep clustering and ensemble clustering by harnessing the power of multiple layers in deep neural networks. Particularly, we utilize a weight-sharing convolutional neural network as the backbone, which is trained with both the instance-level contrastive learning (via an instance projector) and the cluster-level contrastive learning (via a cluster projector) in an unsupervised manner. Thereafter, multiple layers of feature representations are extracted from the trained network, upon which a set of diversified base clusterings can be generated via a highly efficient clusterer. Then, the reliability of the clusters in multiple base clusterings is automatically estimated by exploiting an entropy-based criterion, based on which the multiple base clusterings are further formulated into a weighted-cluster bipartite graph. By partitioning this bipartite graph via transfer cut, the final image clustering result can therefore be obtained. Experimental results on six image datasets confirm the advantages of our DeepCluE approach over the state-of-the-art deep clustering approaches.